微调大型语言模型-核心思想和方法介绍
发布时间:2024年06月06日
上下文学习和索引
自 GPT-2(Radford 等人)和 GPT-3(Brown 等人)以来,我们已经看到在一般文本语料库上预训练的生成式大型语言模型(LLM)能够进行上下文学习,而这并不能如果我们想要执行 LLM 未明确训练的特定或新任务,则要求我们进一步训练或微调预训练的 LLM。相反,我们可以通过输入提示直接提供目标任务的几个示例,如下例所示。
如果我们无法直接访问模型,例如,如果我们通过 API 使用模型,则上下文学习非常有用。与上下文学习相关的是硬提示调整(hard prompt tuning)的概念,我们修改输入以希望改进输出,如下图所示。
顺便说一句,我们称之为硬提示调整(hard prompt tuning),因为我们是直接修改输入的单词或标记。稍后,我们将讨论称为软提示调优(或通常简称为提示调优(prompt tuning))的版本。
上面提到的快速调整方法提供了一种比参数微调更节省资源的替代方法。但是,它的性能通常达不到微调的要求,因为它不会针对特定任务更新模型的参数,这可能会限制其对特定任务细微差别的适应性。此外,提示调整可能是劳动密集型的,因为它通常需要人工参与来比较不同提示的质量。
在我们更详细地讨论微调之前,另一种利用纯基于上下文学习的方法(context learning-based approach)的方法是索引(indexing)。在 LLM 领域内,索引可以被视为一种上下文学习变通方法,它可以将 LLM 转换为信息检索系统,以便从外部资源和网站中提取数据。在此过程中,索引模块将文档或网站分解为更小的部分,将它们转换为可存储在矢量数据库中的矢量。然后,当用户提交查询时,索引模块计算嵌入查询与数据库中每个向量之间的向量相似度。最终,索引模块获取前k个最相似的嵌入以生成响应。
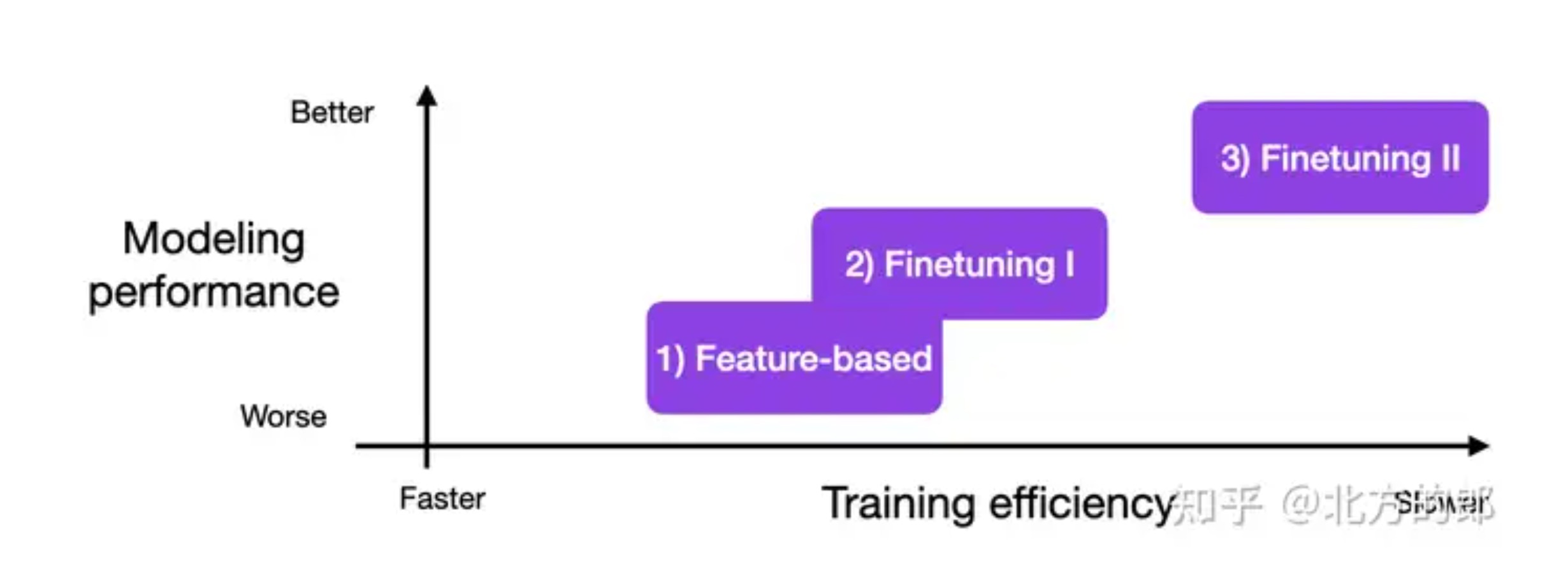
三种传统的基于特征和微调的方法(The 3 Conventional Feature-Based and Finetuning Approaches)
对于直接访问大型语言模型 (LLM) 受限的情况,例如通过 API 或用户界面与 LLM 交互时,上下文学习是一种有价值且用户友好的方法。
但是,如果我们可以访问 LLM,则使用来自目标域的数据在目标任务上对其进行调整和微调通常会产生更好的结果。那么,我们如何才能使模型适应目标任务呢?下图概述了三种常规方法。
给下面的内容提供一些实际背景,我们正在为分类任务微调编码器样式的 LLM,例如 BERT。请注意,不只是微调编码器样式的 LLM,相同的方法适用于类似 GPT 的解码器样式的 LLM。
1)基于特征的方法
在基于特征的方法中,我们加载预训练的 LLM 并将其应用于我们的目标数据集。在这里,我们特别感兴趣的是为训练集生成输出嵌入,我们可以将其用作输入特征来训练分类模型。虽然这种方法对于像 BERT 这样以嵌入为中心的方法特别常见,但我们也可以从生成的 GPT 样式模型中提取嵌入。
然后,分类模型可以是逻辑回归模型、随机森林或 XGBoost——随心所欲。(然而,根据我的经验,逻辑回归等线性分类器在这里表现最好。)
从概念上讲,我们可以使用以下代码说明基于特征的方法:
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10)
X_train = np.array(imdb_features["train"]["features"])
y_train = np.array(imdb_features["train"]["label"])
X_val = np.array(imdb_features["validation"]["features"])
y_val = np.array(imdb_features["validation"]["label"])
X_test = np.array(imdb_features["test"]["features"])
y_test = np.array(imdb_features["test"]["label"])
# train classifier
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("test accuracy", clf.score(X_test, y_test))(有兴趣的读者可以在此处找到完整的代码示例。)
2) Finetuning I——更新输出层
与上述基于特征的方法相关的一种流行方法是微调输出层(我们将这种方法称为微调 I )。与基于特征的方法类似,我们保持预训练 LLM 的参数不变。我们只训练新添加的输出层,类似于在嵌入特征上训练逻辑回归分类器或小型多层感知器。
在代码中,这将如下所示:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# freeze all layers
for param in model.parameters():
param.requires_grad = False
# then unfreeze the two last layers (output layers)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)
(有兴趣的读者可以在这里找到完整的代码示例。)
从理论上讲,这种方法在建模性能和速度方面应该与基于特征的方法一样好,因为我们使用相同的冻结主干模型。然而,由于基于特征的方法使得预计算和存储训练数据集的嵌入特征稍微容易一些,因此基于特征的方法对于特定的实际场景可能更方便。
3) Finetuning II – 更新所有图层
虽然原始的 BERT 论文(Devlin 等人)报告说,仅微调输出层可以产生与微调所有层相当的建模性能,但由于涉及更多参数,因此成本要高得多。例如,一个 BERT 基础模型有大约 1.1 亿个参数。然而,用于二进制分类的 BERT 基础模型的最后一层仅包含 1,500 个参数。此外,BERT 基础模型的最后两层包含 60,000 个参数——仅占模型总大小的 0.6% 左右。
我们的里程数将根据我们的目标任务和目标域与模型预训练数据集的相似程度而有所不同。但在实践中,微调所有层几乎总能获得出色的建模性能。
因此,在优化建模性能时,使用预训练 LLM 的黄金标准是更新所有层(此处称为微调 II)。从概念上讲,微调 II 与微调 I 非常相似。唯一的区别是我们不冻结预训练 LLM 的参数,而是对它们进行微调:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# freeze layers (which we don't do here)
# for param in model.parameters():
# param.requires_grad = False
# finetune model
lightning_model = LightningModel(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)
(有兴趣的读者可以在这里找到完整的代码示例。)
如果您对一些真实世界的结果感到好奇,上面的代码片段用于使用预训练的 DistilBERT 基本模型训练电影评论分类器(您可以在此处访问代码笔记本):
- 1) 基于特征的逻辑回归方法:83% 的测试准确率
- 2) Finetuning I,更新最后两层:87%准确率
- 3) Finetuning II,更新所有层:92% 准确率。
这些结果与一般经验法则一致,即微调更多层通常会带来更好的性能,但会增加成本。
上面的场景突出了微调的三种最明显或极端的情况:只训练最后一层与训练所有层。当然,我们的里程可能会因模型和数据集而异,但探索两者之间的各种选项也可能是值得的。例如,我们有时可以通过只训练一半的模型来获得相同的建模性能(但在下一节中会详细介绍参数有效微调)。对于那些好奇的人,下图显示了 DistilBERT 模型在来自IMDB 电影评论数据集的 20k 个训练示例上微调的预测性能和训练时间。
正如我们所见,训练最后一层是最快的,但也会导致最差的建模性能。训练更多层可以提高建模性能,但也会增加计算成本。最有趣的是,我们可以看到在训练两个完全连接的输出层和最后两个转换器块(左起第三个块)时预测性能饱和。因此,在这种特殊情况下(即对于这种特殊模型和数据集组合),训练比这些层更多的层似乎在计算上是浪费的。
参数高效微调(Parameter-Efficient Finetuning)
参数高效微调使我们能够重用预训练模型,同时最大限度地减少计算和资源占用。总而言之,参数有效微调至少有 5 个有用的原因:
- 降低计算成本(需要更少的 GPU 和 GPU 时间);
- 更快的训练时间(更快地完成训练);
- 较低的硬件要求(适用于较小的 GPU 和较少的内存);
- 更好的建模性能(减少过度拟合);
- 更少的存储空间(大部分权重可以在不同任务之间共享)。
在前面的部分中,我们了解到微调更多层通常会带来更好的结果。现在,上面的实验是基于一个相对较小的 DistilBERT 模型。如果我们想微调只能勉强放入 GPU 内存的较大模型,例如最新的生成 LLM,该怎么办?当然,我们可以使用上面的基于特征或微调的方法。但是假设我们想要获得与 Finetuning II 类似的建模质量?
多年来,研究人员开发了多种技术(Lialin 等人)来微调 LLM,使其具有高建模性能,同时只需要训练少量参数。这些方法通常称为参数高效微调技术 (PEFT)。
下图总结了一些最广泛使用的 PEFT 技术。
那么,这些技术是如何工作的呢?简而言之,它们都涉及引入我们微调的少量附加参数(与我们在上面的 Finetuning II 方法中所做的微调所有层相反)。从某种意义上说,Finetuning I(只微调最后一层)也可以被认为是一种参数有效的微调技术。然而,前缀调整、适配器和低秩自适应等技术,所有这些都“修改”了多个层,实现了更好的预测性能(以低成本)。
这部分内容详见: 北方的郎:了解Parameter-Efficient的 LLM 微调:Prompt Tuning And Prefix Tuning
人类反馈强化学习(Reinforcement Learning with Human Feedback)
在人类反馈的强化学习 (RLHF) 中,使用监督学习和强化学习的组合对预训练模型进行微调——该方法被原始的 ChatGPT 模型推广,而该模型又基于 InstructGPT的成果。
在 RLHF 中,通过让人类对不同的模型输出进行排名或评级来收集人类反馈,从而提供奖励信号。然后可以使用收集到的奖励标签来训练奖励模型,该模型随后用于指导 LLM 适应人类偏好。
奖励模型本身是通过监督学习学习的(通常使用预训练的 LLM 作为基础模型)。接下来,奖励模型用于更新要适应人类偏好的预训练 LLM——训练使用一种称为近端策略优化的强化学习。
为什么使用奖励模型而不是直接根据人类反馈训练预保留模型?这是因为让人类参与学习过程会造成瓶颈,因为我们无法实时获得反馈。
结论
微调预训练 LLM 的所有层仍然是适应新目标任务的黄金标准,但是有几种有效的替代方法可以使用预训练的转换器。基于特征的方法、上下文学习和参数高效微调技术等方法可以将 LLM 有效应用于新任务,同时最大限度地减少计算成本和资源。此外,带有人类反馈的强化学习 (RLHF) 可作为监督微调的替代方案,有可能提高模型性能。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个应用于协作式文本图表的平台,它利用人工智能生成复杂思想的可视化图表。