LLM大模型推理输出生成方式总结
发布时间:2024年06月06日
Greedy Search
方式:每一时间步都选择概率最大的词。
参数设置:do_sample = False, num_beams = 1
缺点:
1、生成文本重复
2、不支持生成多条结果。 当num_return_sequences参数设置大于1时,代码会报错,说greedy search不支持这个参数大于1
Beam-search
方式:每一时间步选择num_beams个词,并从中最终选择出概率最高的序列。

参数设置:do_sample = False, num_beams>1
缺点:虽然结果比贪心搜索更流畅,但是仍然存在生成重复的问题
Multinomial sampling(多项式采样)
方式:每一个时间步,根据概率分布随机采样字(每个概率>0的字都有被选中的机会)。
参数:do_sample = True, num_beams = 1
优点:解决了生成重复的问题,但是可能会出现生成的文本不准守基本的语法
Beam-search multinomial sampling
方式:结合了Beam-search和multinomial sampling的方式,每个时间步从num_beams个字中采样
参数:do_sample = True, num_beams > 1
其它Trick
惩罚重复
方式:在每步时对之前出现过的词的概率做出惩罚,即降低出现过的字的采样概率,让模型趋向于解码出没出现过的词
参数:repetition_penalty(float,取值范围>0)。默认为1,即代表不进行惩罚。值越大,即对重复的字做出更大的惩罚
代码实现逻辑:如果字的概率score<0,则score = score*penalty, 概率会越低; 如果字的概率score>0, 则则score = score/penalty,同样概率也会变低。

惩罚n-gram
方式:限制n-gram在生成结果中出现次数
参数:no_repeat_ngram_size,限制n-gram不出现2次。 (no_repeat_ngram_size=6即代表:6-gram不出现2次)
限制采样Trick
Temperature
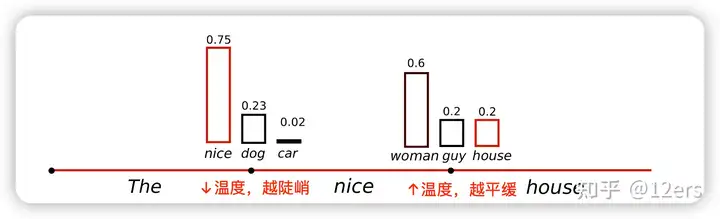
方式:通过温度,控制每个字的概率分布曲线。温度越低,分布曲线越陡峭,越容易采样到概率大的字。温度越高,分布曲线越平缓,增加了低概率字被采样到的机会。
参数:temperature(取值范围:0-1)设的越高,生成文本的自由创作空间越大;温度越低,生成的文本越偏保守。
Top-K采样
方式:每个时间步,会保留topK个字,然后对topk个字的概率重新归一化,最后在重新归一化后的这K个字中进行采样
参数:top_k
缺点:在分布陡峭的时候仍会采样到概率小的单词,或者在分布平缓的时候只能采样到部分可用单词
Top-P采样(又称Nucleus Sampling)
方式:每个时间步,按照字出现的概率由高到底排序,当概率之和大于top-p的时候,就不取后面的样本了。然后对取到的这些字的概率重新归一化后,进行采样。
参数:top_p (取值范围:0-1)
top-P采样方法往往与top-K采样方法结合使用,每次选取两者中最小的采样范围进行采样,可以减少预测分布过于平缓时采样到极小概率单词的几率。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
PhotoKit 集成了强大的在线照片编辑器