微调、训练大模型概念介绍及论文笔记:Tuning系列论文笔记
发布时间:2024年06月06日
Tuning整体介绍
微调(Fine-tunning)
语言模型的参数需要一起参与梯度更新
轻量微调(lightweight fine-tunning)
冻结了大部分预训练参数,仅添加任务层,语言模型层参数不变
适配器微调 (Adapter-tunning)
Adapter在预训练模型每层中插入用于下游任务的参数,在微调时将模型主体冻结,仅训练特定于任务的参数,减少训练时算力开销
提示学习(Prompting)
任务输入前添加一个自然语言任务指令和一些示例,直接在预训练语言模型中统一建模,比如GPT2/GPT3
前缀微调(Prefix-tuning)
将prompt方式扩展到连续空间,在每层输入序列前面添加prompt连续向量【随机初始化,并不对应到具体的token】目前是将语言模型freeze后,仅微调prompt参数,在实验中是增加了一个MLP重参数化,确保效果,使用MLP后的结果做预测
提示微调(Prompt-tuning)
将prompt扩展到扩展到连续空间,但是仅在输入层加入prompt连续向量,且不固定,同时使用LSTM建模prompt向量之间的关联性
【P-tuning与Prefix-tuning】:
- Prefix-tuning仅针对NLG任务生效,服务于GPT架构;P-tuning考虑所有类型的语言模型
- Prefix-tuning限定了在输入前面添加,P-tuning则可以在任意位置添加
- Prefix-tuning为了保证效果在每一层都添加,但p-tuning可以只在输入层添加
【P-tuning与fine-tuning】
P-tuning不改变预训练阶段模型参数,而是通过微调寻找更好的连续prompt提示,来引导已学习到的知识的使用;Fine-tuning可能在调整模型参数过程中,可能带来了灾难性遗忘问题
提示微调v2(Prompt-tuning)
在第一版基础上,将每层输入都添加上prompt连续向量,同时探索了prompt长度在不同规模的模型上的效果;去掉MLP层重参数化
指令微调(Instruct-tuning)
指令微调是会直接通过自然语言形式给出人类指令,是基于一组NLP任务集合上直接tuning的过程,它可以提高语言模型在未知任务上的效果,即zero-shot learning能力
【instruct-tuning 与 prompt-tuning】
- 提示微调:"我带女朋友去桂林旅游" 的英文翻译是___
- 指令微调:翻译这句话:输入:我带女朋友去桂林旅游,输出:_______
二者目的都是挖掘语言模型本身已掌握的知识,prompt是激发语言模型补全能力,是针对某特定任务而言,不同的任务需要给出不同的表达形式;instruct则是激发语言模型的理解能力,是针对任务集合而形成的指令,它能通过理解做什么任务,在未可见任务上泛化能力更强【zero-shot learning】
指令提示微调(Instruction Prompt tuning)
语境提示微调是指结合LLM的ICL能力和prompt-tuning结合到指令提示微调中,将检索到的上下文演示示例和可微调的prompt嵌入式表征进行拼接,能够让LLM在医学领域方面获得不错的应用效果
Large Language Models Encode Clinical Knowledge
Lora微调
- 前人研究发现模型是过参数化的,存在更小的内在维度,可以低秩分解的
- 固定预训练语言模型的参数,额外增加新的参数,增加低秩分解的矩阵可以适配下游任务"="" display=""block"">
h = W 0 x + Δ W x = W 0 x + B A x , B → ( d , r ) , A → ( r , k ) , r << m i n d ( d , k ) " role="presentation" style="display: inline-block; font-style: normal; font-weight: normal; line-height: normal; font-size: 16px; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;"> - 效果:训练参数量显著降低,显存需求减少(GPT-3 模型上能够把参数量降低到普通fine-tune的万分之一)
- 相比Adapters, LoRA不增加推理延迟
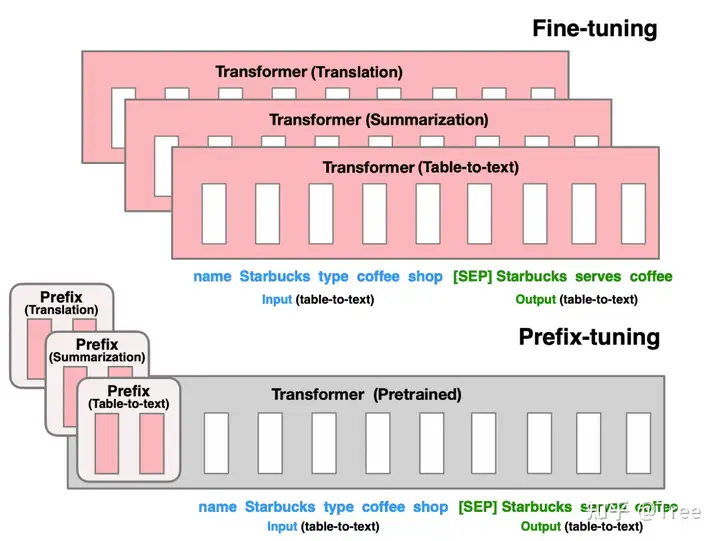
Prefix-Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-tunning 前缀学习将prompting扩展到连续空间,无需one-hot查找,而是初始化为一组自由参数,然后进行优化 -> 主要针对NLG任务
论文核心点
其实就是类似于GPT2的方式,在输入前面【固定位置】添加一个任务名的位置向量,在接入下游任务时候,freeze其他部分的参数,训练该位置向量即可
1 评估的任务
- table-to-text任务:语言模型GPT-2
- 摘要任务:BART模型
- GPT类的自回归模型上采用[PREFIX, x, y],
- T5类的encoder-decoder模型上采用[PREFIX, x, PREFIX', y]

2 模型细节
- 把预训练大模型freeze住,因为大模型参数量大,精调起来效率低,毕竟prompt的出现就是要解决大模型少样本的适配
- 作者发现直接优化Prompt参数不太稳定,加了个更大的MLP,训练完只保存MLP变换后的参数就行了
- 实验证实只加到embedding上的效果不太好,因此作者在每层都加了prompt的参数,改动较大,可能起到了类似残差的效果
Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning

论文核心内容
1 设计一种前缀prompt方法,在输入词嵌入之前添加前缀prompt,区别于人工prompt方式,其输入的前缀可以不token化, 神经网络直接表征
2 在微调的时候,固定上游模型的参数,只微调prompt的参数,相当于对每一个下游任务,只需要额外训练一个独立的prompt参数即可
对比实验
- prompt长度实验:越长的prompt能带来越好的效果,但模型规模足够大,长度影响就很小 【可能是因为越长的prompt对应越长的参数表达空间,效果自然会变好,但模型规模足够大,则这部分的参数占比可能就不明显】
- prompt初始化策略:随机初始化 < 最长词汇初始化 < 标签字符串初始化,但是模型规模变大后,则初始化策略也无关重要【整体上就是大力出奇迹,几乎可以忽略所有的超参数细节】
- Domain-shit跨域实验,prompt方法会比微调模型效果更优泛化效果,尤其域间数据差异越大,效果越明显【这主要反映的是prompt方式在下游任务使用中通用性更强,调整下游任务时候,损失的语言模型本身能力较小】
点评
这篇论文主要是针对T5模型为backbone,提出prompt微调方式训练下游任务 ;与prefix-tuning相比,主要是实验的模型架构不同,并设计了多重对比实验,探索了不同初始化方式,不同prompt对语言模型微调的影响,最终整体的结论:
随着模型规模变大,prompt的初始化和长度对效果影响很小,鲁棒性和泛化能力也有比较好的提升 整体论文没啥创新点,主要实验多
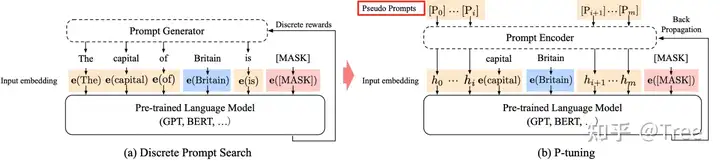
P-tuning
Motivation
1 GPT系列AR建模在自然语言理解NLU任务上效果不好,与BERT双向语言模型相比有明显差距
2 之前的研究表明GPT3使用prompt训练方式可以显著提升few-shot 和 zero-shot的效果
3 传统的prompt方法存在明显缺陷:
- 人工制定prompt模板, 需要大量的验证集校验
- 神经网络本身就是连续型建模,离散的prompts始终都只能是局部最优解
Experiment
- LAMA:固定模型参数后,GPT能够提升26.2%~41.1%
- SuperGLUE:GPT模型比BERT模型效果要好
Conclusion
- GPT在自然语言理解任务上也可以达到与BERT相似的效果,这说明GPT在自然语言理解方向是存在潜力,这种AR单向语言模型架构在NLU和NLG任务都有效,是自然语言建模可以统一的框架[chatGPT的效果足以说明GPT在语义理解层面的确是有能力的]
- 将本文的P-tuning方法应用到BERT模型架构,也使其在few-shot任务上有明显效果提升
P-tuning v2
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
背景
1 在NLU场景下,prompt tuning方法目前在常规尺寸的预训练语言模型上应用效果不佳【across scales】
2 prompt tuning方法很难处理比较难的序列标注任务,缺乏普适性【across tasks】
论文核心点
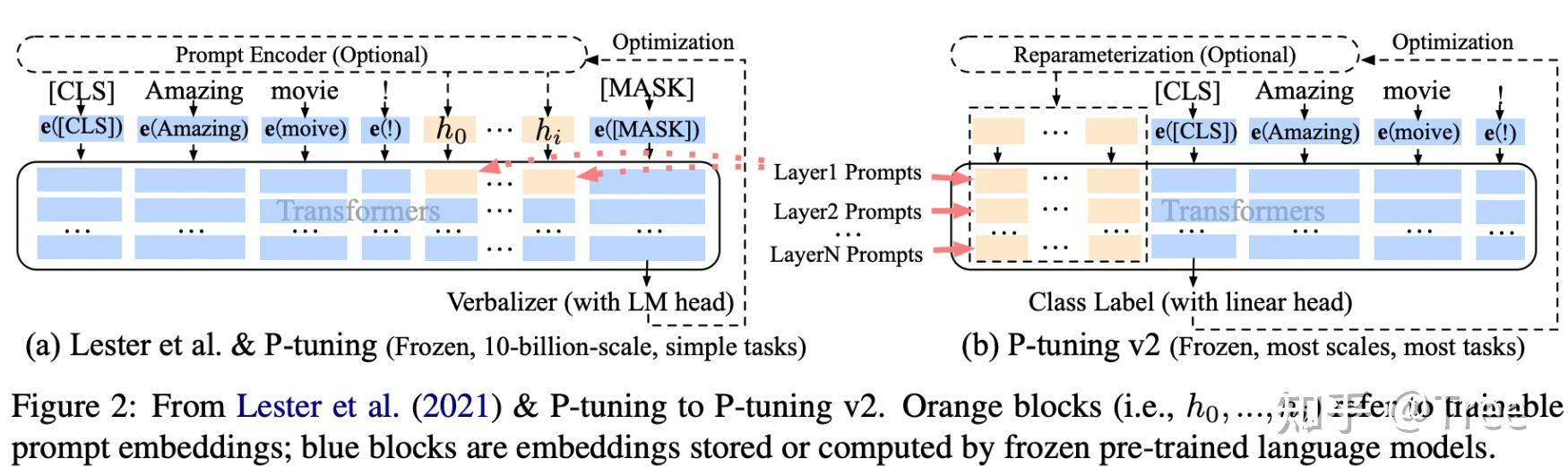
1 Deep Prompt Encoding:采用 Prefix-tuning 的做法,在输入前面的每层加入可微调的参数。
2 None-reparameterization:对pseudo token,不再增加其他网络结构进行表征(如用于 prefix-tuning 的 MLP),且不再替换pre-trained model word embedding,取而代之的是直接对pseudo token对应的深层模型的参数进行微调。
3 Multi-task learning:对于pseudo token的continuous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训练多个数据集,prefix continuous prompt共享。
4 在[CLS]部分输出sentence-level class,以及每个token位置上输出token-level class,可以解决一些没有语义标签的问题。
论文其实就是借鉴了prefix-tuning的方式,在每层都添加了prompts提升在不同规模,不同类型的任务上的普适性效果
Instruct-tuning
Fine-tuned Language Models Are Zero-Shot Learners
论文核心点
针对prompt学习方式的zero-shot learning 效果差,这篇论文提出了一个指令学习的概念,基于一组NLP任务提炼出来一种形如指令的自然语言,可以激发语言模型对任务的理解能力,通过直接在不同的任务上进行instruct-tuning,可以在任务层面有更强的泛化能力,zero-shot learning场景下能有显著的任务提升
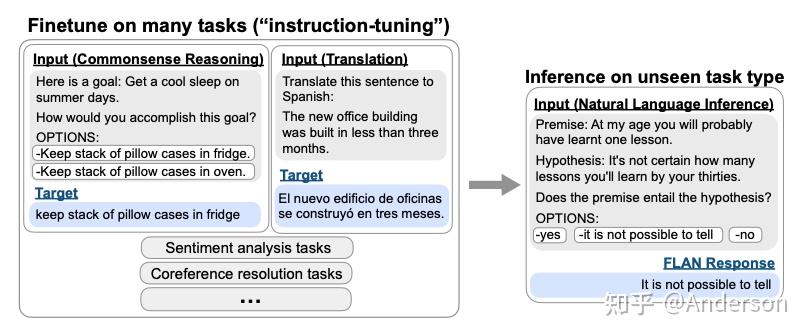

消融实验中,在instruction-tuning中增加任务数量可以提高未知任务上的效果,而且指令学习的增益仅仅在足够大的模型规模上才会出现【模型规模足够大的时候,语言理解能力才足够强】
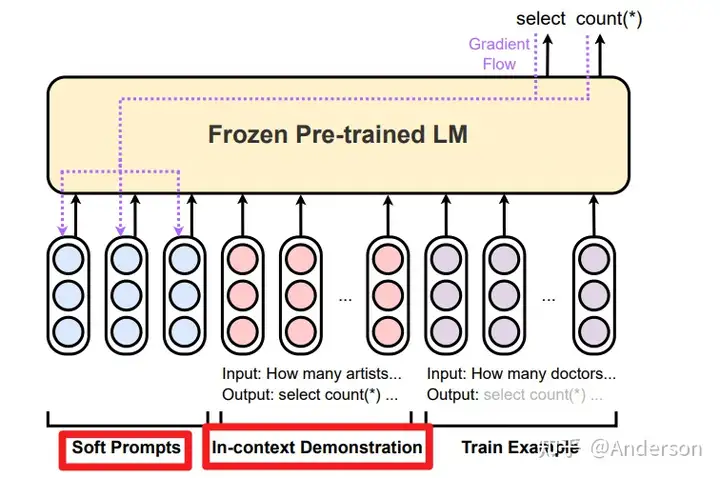
Instruction Prompt-tuning
How Does In-Context Learning Help Prompt Tuning?
这篇研究主要针对“指令提示调整”(IPT)方法进行拆解,分析语境学习在prompt-tuning上是如何工作的,在五项任务实验中整体观察到的结论:
- PT和IPT的效果在5个任务中始终优于ICL, 这说明域外任务至少需要少量参数的训练
- PT和IPT的性能并没有绝对优劣,性能很大程度上取决于任务和实验配置,比如可调嵌入的数量。IPT如果演示示例在语义上与测试输入相似度较高,会带来PT效果提升
- PT方法不稳定,方差高,但是与ICL结合使用后,可以降低方差,比PT更少依赖于可调嵌入的数量
- 通过PT方式在特定任务上学到的prompt效果,当结合语境学习后,可以迁移到其他任务上,并且这种迁移效果比直接在ICL演示中结合源任务和目标任务的演示示例的方法效果还要好
数据集
- data-to-text generation: DART, ToTTo, 输出短句子,评估指标为BLEU
- semantic parsing: Spider, MTOP, 评估指标Exact-Match Acc
- logic-to-text generation: Logic2Text, 评估指标BLEC

语言模型
- https://huggingface.co/bigscience/bloom-1b1
- https://huggingface.co/facebook/opt-1.3b
- https://huggingface.co/gpt2-xl
- https://huggingface.co/spaces/bigscience/BigScienceCorpu
这里论文还提出使用In-context demonstration retrieval选择最佳的演示示例,具体使用了FASIS工具
实验结果
这里贴部分主要的实验结果
- PT和IPT的效果在5个任务中始终优于ICL, 但IPT和PT的性能没有绝对优劣

- 单独的PT方法直接迁移到其他任务效果效果不是很高,但是增加ICLS示例后,迁移效果显著提升
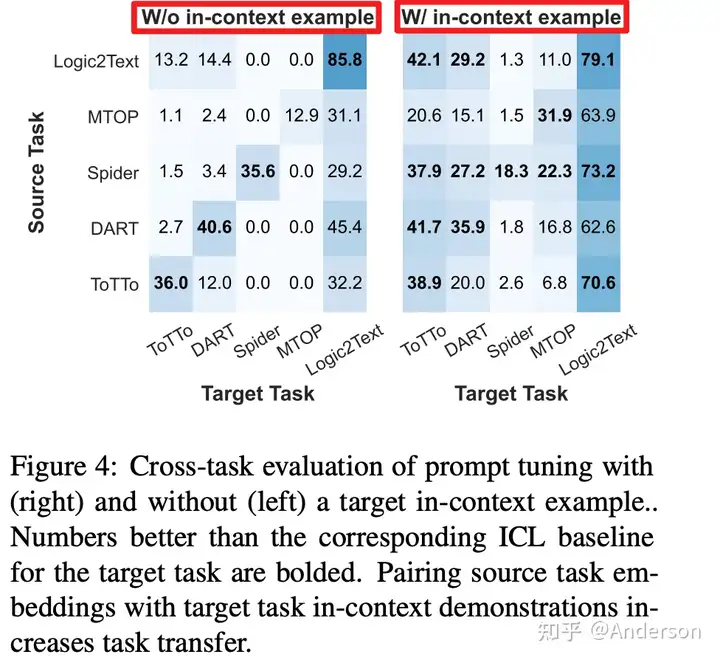
- 在检索到的上下文演示的输入与测试输入非常相似的示例中,IPT 比 PT 表现更好

Lora-Adapters
LoRA: Low-Rank Adaptation of Large Language Models
核心内容
- 灵感:前人一些 intrinsic dimension(固有维度),模型是过参数化的,存在更小的内在维度,可以低秩分解
- 思路:固定预训练语言模型的参数,额外增加新的参数,增加低秩分解的矩阵来适配下游任务"="" display=""block"">
h = W 0 x + Δ W x = W 0 x + B A x , B → ( d , r ) , A → ( r , k ) , r << m i n d ( d , k ) " role="presentation" style="display: inline-block; font-style: normal; font-weight: normal; line-height: normal; font-size: 16px; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;"> - 效果:训练参数量显著降低,显存需求减少(GPT-3 模型上能够把参数量降低到普通fine-tune的万分之一)
- 相比Adapters, LoRA不增加推理延迟

B是全0初始化的,LoRA的右路的结果会接近0, 微调的初始状态和原模型保持一致
在多个attention的矩阵上分别放置低秩一点的LoRA效果好 比 在其中一个矩阵上放一个更高秩的矩阵 更好
将秩设置到和原来的参数矩阵维度一样大,则和全参数微调没区别,一般秩=8微调性能已经接近全微调效果;对于预训练阶段和下游任务差异较大时,继续增加秩的大小仍然可以提高性能
PEFT
Towards a Unified View of Parameter-Efficient Transfer Learning
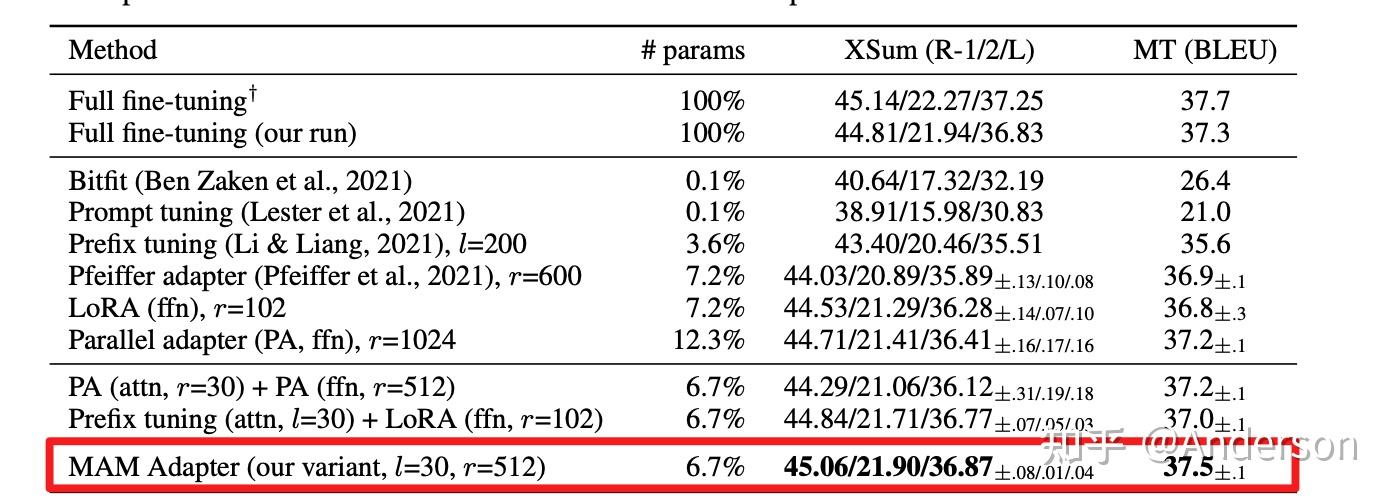
论文主要针对目前三类SOTA的参数微调策略进行拆解,提出一种统一的参数高效迁移学习框架,并从四个维度(∆h的函数计算,微调参数插入形式,隐层表征修改,h和△h函数组合方式)对方法进行拆解和分析,并由此提出了一些新的变体,通过对比实验验证了一些设计会更优,论文设计的最优变体MAM adapter(Mix-And-Match adapter)在仅用了6.7%参数量的情况下,在Xsum和MT这两个task上达到了和full fine-tuning相近的效果
核心思路
固定住Pretrain Language model的大部分参数,仅调整模型的一小部分参数来达到与Full fine-tuning接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)
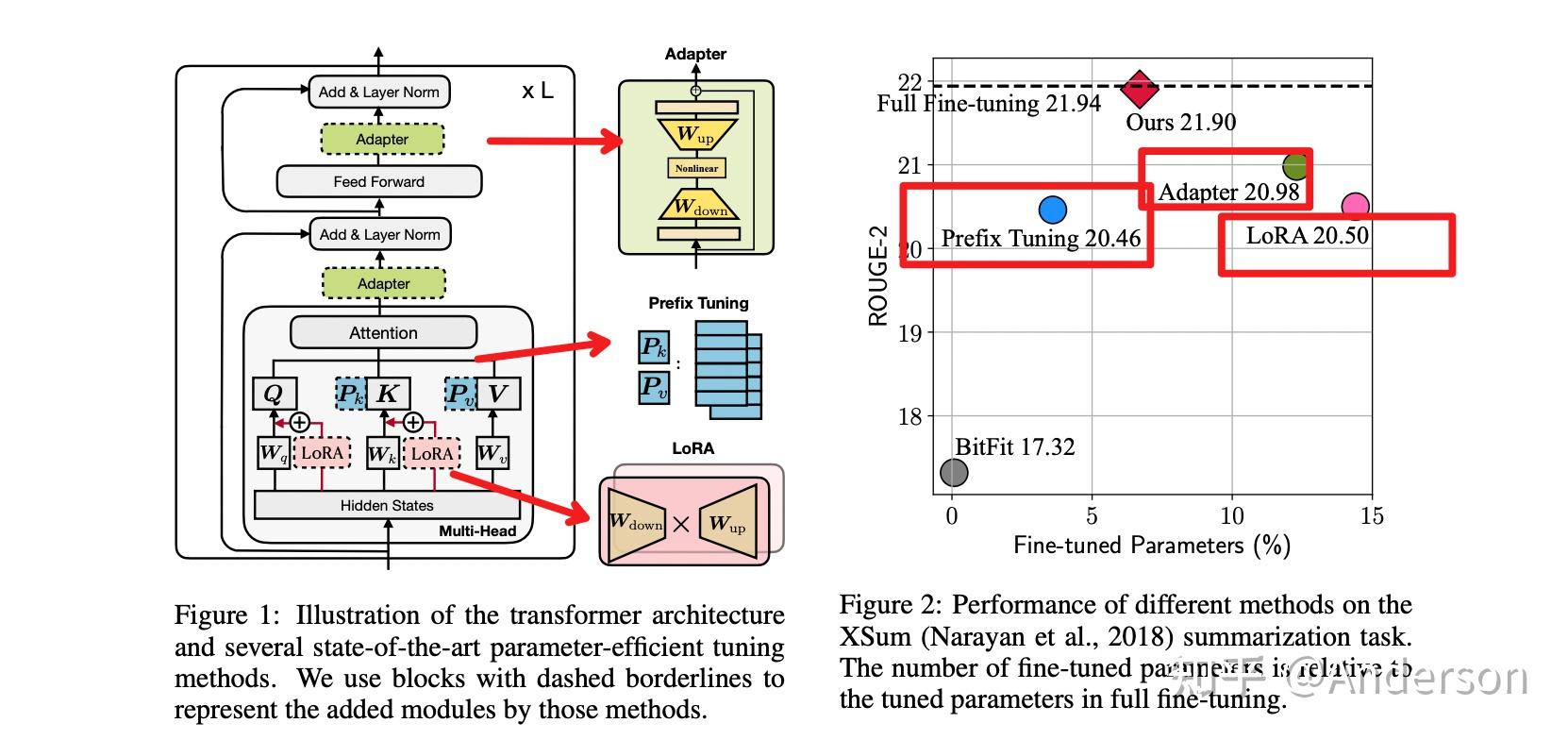
具体内容
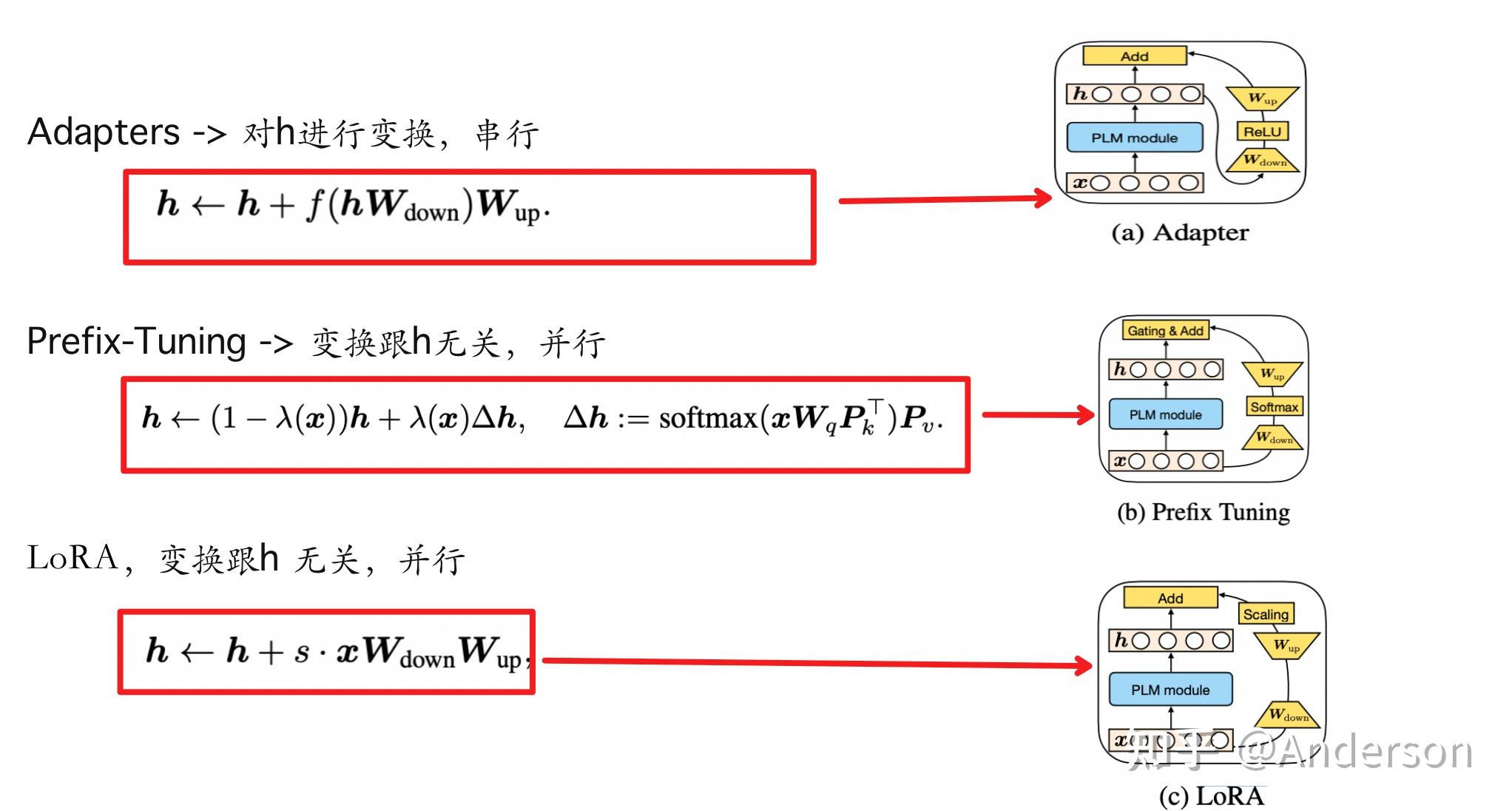
对prefix-tuning, lora 和 adapters进行公式分解,本质都是对原本的h进行了修改,不同的是Adapters是串行的,Prefix Turing 和LoRA 是并行的
实验设计
从四个维度对已有的方法进行总结,并以此提出新的变体,设计了相关的实验进行效果验证
- Functional Form : 计算∆h的函数
- Insertion Form:插入形式,并行还是串行
- Modified Representation:待修改的隐层表示
- Composition Function:组合函数,h和△h怎么组合在一起,直接相加还是门控相加

实验结论
1 Prefix tuning 只作用于attention
2 Adapter 既可以作用于attention 又可以作用于FFN
3 LoRA作用于attention , 也可以作用于FFN
4 所有方法作用于FFN比所用方法attention表现更优。
5 Prefix tuning 只能作用于attention head ,相比Adapter 和 LoRA有天然的弊端。
6 并行的结果要优于串行的结果
最优化的设计 Mix-And-Match adapter (MAM Adapter).
- Insertion Form:采取并行结构的Adapter并且设计成multi-head的形式;
- Modified Representation:将0.1%的参数分配到multi-head结构的attn上面,其余的参数量配置在ffn上
- Composition: 采用LoRA的设计方式,加一个超参数s
实验结果:MAM adapter在仅用了6.7%参数量的情况下,在Xsum和MT这两个task上达到了和full fine-tuning相近的效果
注意:self-attention的模型参数是对q, k, v进行线性变换的映射矩阵 以及 输出变换的映射矩阵 "="">
W Q ( d m o d e l ∗ d q ) , W K ( d m o d e l ∗ d k ) , W V ( d m o d e l ∗ d v ) , W O ( d v ∗ d m o d e l ) " role="presentation" style="display: inline-block; font-style: normal; font-weight: normal; line-height: normal; font-size: 16px; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;"> q, k, v是输入数据,在微调过程中仅改变输入的序列长度并不会改变权重矩阵
推荐材料
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个免费在线的去水印工具,它使用人工智能技术,支持批量去除图片中的文字、标志,多余物体等多种水印,不压画质,保证高质不糊图。