如何从零开始训练专属 LoRA 模型?4600字总结送给你!
发布时间:2024年06月06日
目前 Stable Diffusion 主要有四种模型训练方法:Dreambooth、LoRA、Textual Inversion、Hypernetwork。本文主要介绍如何训练 LoRA 模型,LoRA 是一种轻量化的模型微调训练方法,是在原有大模型的基础上,对模型进行微调,从而能够生成特定的人物、物品或画风。该方法具有训练速度快,模型大小适中,训练配置要求低的特点,能用少量的图片训练出想要的风格效果。

一、训练数据集准备
这个过程主要做三件事:
- 训练素材处理
- 图像预处理
- 打标优化
1. 训练素材处理
首先确定你的训练主题,比如某个人物、某种物品、某种画风等。以下我就以训练这种大手大脚的画风主题为例进行讲解。

确定好画风后,就需要准备用于训练的素材图片,素材图的质量直接决定了模型的质量,好的训练集有以下要求:
- 不少于 15 张的高质量图片,一般可以准备 20-50 张图;
- 图片主体内容清晰可辨、特征明显,图片构图简单,避免其它杂乱元素;
- 如果是人物照,尽可能以脸部特写为主(多角度、多表情),再放几张全身像(不同姿势、不同服装);
- 减少重复或相似度高的图片。
素材图准备完毕后,需要对图片做进一步处理:
- 对于低像素的素材图,可以用 Stable Diffusion 的 Extra 功能进行高清处理;
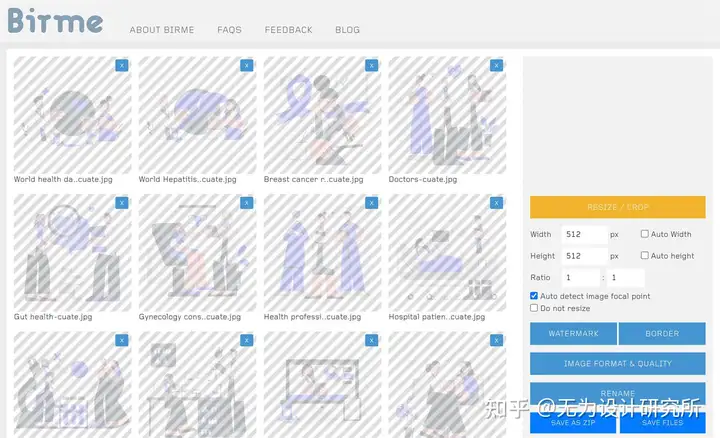
- 统一素材图分辨率,注意分辨率为 64 的倍数,显存低的可裁切为 512x512,显存高的可裁切为 768x768,可以通过 birme 网站进行批量裁切。
2. 图像预处理
这一步的关键是对训练素材进行打标签,从而辅助 AI 学习。这里介绍两种打标签的方法:
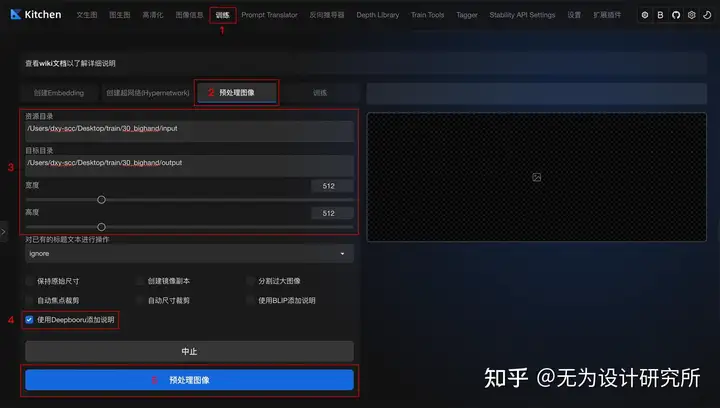
方法一:把训练素材文件夹路径填写到 Stable Diffusion 训练模块中的图像预处理功能,勾选生成 DeepBooru,进行 tags 打标签。
方法二:安装 tagger 标签器插件,进行 tags 打标签。
网址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger
选择批量处理, 输入目录填写处理好的图片目录,设置标签文件输出目录,阈值设置为 0.3(生成尽可能多的标签来描述图片内容),开始打标签。

3. 打标优化
预处理生成 tags 打标文件后,就需要对文件中的标签再进行优化,一般有两种优化方法:
方法一:保留全部标签
就是对这些标签不做删标处理, 直接用于训练。一般在训练画风,或想省事快速训练人物模型时使用。
优点:不用处理 tags 省时省力,过拟合的出现情况低。
缺点:风格变化大,需要输入大量 tag 来调用、训练时需要把 epoch 训练轮次调高,导致训练时间变长。
方法二:删除部分特征标签
比如训练某个特定角色,要保留蓝眼睛作为其自带特征,那么就要将 blue eyes 标签删除,以防止将基础模型中的 blue eyes 引导到训练的 LoRA 上。简单来说删除标签即将特征与 LoRA 做绑定,保留的话画面可调范围就大。
一般需要删掉的标签:如人物特征 long hair,blue eyes 这类。
不需要删掉的标签:如人物动作 stand,run 这类,人物表情 smile,open mouth 这类,背景 simple background,white background 这类,画幅位置等 full body,upper body,close up 这类。
优点:调用方便,更精准还原特征。
缺点:容易导致过拟合,泛化性降低。
什么是过拟合:过拟合会导致画面细节丢失、画面模糊、画面发灰、边缘不齐、无法做出指定动作、在一些大模型上表现不佳等情况。
批量打标:有时要优化等标签会比较多,可以尝试使用批量打标工具
BooruDatasetTagManager:https://github.com/starik222/BooruDatasetTagManager
二、训练环境参数配置
训练数据集准备完毕后,开始训练环境配置。一般有本地和云端两种训练环境:
- 本地训练:要求 N 卡,推荐 RTX 30 系列及以上显卡,训练环境可以用秋叶大佬的一键训练包,或者安装 Stable Diffusion WebUI 的训练插件。 https://github.com/liasece/sd-webui-train-tools
- 云端训练:如在 AutoDL、Google Colab 等云平台上训练,推荐 kohya-ss 训练脚本。云端训练的好处在于不占用本机资源,训练的同时还可以干其他事。
以下我以云端训练为例,介绍如何使用 Google Colab 进行云端训练环境配置。
1. 训练环境配置
这里推荐使用基于 kohya-ss 的训练脚本,例如: https://colab.research.google.com/github/WSH032/kohya-config-webui/blob/main/kohya_train_webui.ipynb
进入 Colab 后,点击连接。
① 建立训练文件夹
连接成功后,展开(一)环境配置:
- 运行初始化常量与挂载谷歌硬盘。
- 成功挂载谷歌硬盘后,在 content - drive 目录下建一个 Lora 训练文件夹,在训练文件夹中建立 input 文件夹用于放置输入数据集,建立 output 文件夹用于放置输出的训练模型。
- input 文件夹内建一个训练数据集文件夹,注意该文件夹的命名有格式要求:Repeat 值_主题名,这里 Repeat 值的含义代表每张素材图的训练步数。越精细的图,Repeat 值也越高,一般二次元可以 15-30,三次元可以 50-100。

② 运行克隆 github的库、安装依赖
③ 设置训练用底模型
- modelName:可以选择环境中已经提供的模型 如 Stable-Diffusion-v1-5.safetensors。
- base_model_url:也可以选择自定义模型,在 huggingface 上搜到想要模型的地址,复制过来。

2. 训练参数配置
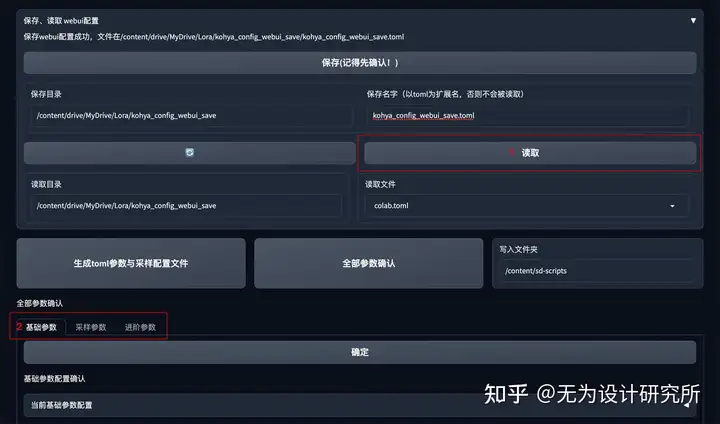
展开(二)训练参数,运行启动 WebUI 来设置参数,出现 https://localhost:xxxxx/ 链接后点击打开训练参数配置界面。

先点击读取,完成默认参数配置,再进行基础参数和采样参数设置。
① 基础参数设置
基础设置
- train_data_dir:训练集输入目录,把之前建立的数据集文件夹路径复制过来,如/content/drive/MyDrive/Lora/input。
- 底模:填入底模文件夹地址 /content/Lora/sd_model/,刷新加载底模。
resolution:训练分辨率,支持非正方形,但必须是 64 倍数。一般方图 512x512、768x768,长图 512x768。 - batch_size:一次性送入训练模型的样本数,显存小推荐 1,12G 以上可以 2-6,并行数量越大,训练速度越快。
- max_train_epoches:最大训练的 epoch 数,即模型会在整个训练数据集上循环训练的次数。如最大训练 epoch 为 10,那么训练过程中将会进行 10 次完整的训练集循环,一般可以设为 5-10。
- network_dim:线性 dim,代表模型大小,数值越大模型越精细,常用 4~128,如果设置为 128,则 LoRA 模型大小为 144M。
- network_alpha:线性 alpha,一般设置为比 Network Dim 小或者相同,通常将 network dim 设置为 128,network alpha 设置为 64。
输出设置
- 模型输出地址:模型输出目录,把之前建立的训练输出文件夹路径复制过来,如/content/drive/MyDrive/Lora/output
- 输出模型名称:可以填模型主题名,如 bighand
- 保存模型格式:模型保存格式,默认 safetensors
学习率设置
- unet_lr:unet 学习率,默认值为 0.0001
- text_encoder_lr:文本编码器的学习率,一般为 unet 学习率的十分之一 0.00001
- lr_scheduler:学习率调度器,用来控制模型学习率的变化方式,一般默认。
- lr_warmup_steps:升温步数,仅在学习率调度策略为“constant_with_warmup”时设置,用来控制模型在训练前逐渐增加学习率的步数,一般不动。
- lr_restart_cycles:退火重启次数,仅在学习率调度策略为“cosine_with_restarts”时设置,用来控制余弦退火的重启次数,一般不动。
② 采样参数设置
- Sample every n epochs:每 N 轮采样一次,一般设置为 1。
- Sample every n steps:比如设置为 100,则代表每训练 100 步采样一次。
- Sample prompt:采样提示词,设置之后,LoRA 训练的同时会每隔设定的步数或轮次,生成一副图片,以此来直观观察 LoRA 训练的进展。
完成训练参数设置后,点击全部参数确认、生成 toml 参数与采样配置文件,并保存配置文件。

三、模型训练
训练参数配置保存完成后,点击开始训练。
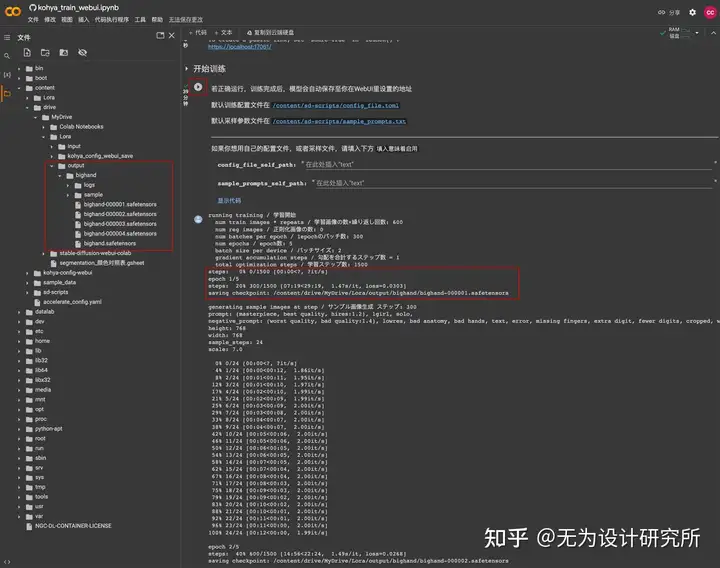
这里的 steps 代表总训练步数。一般总训练步数不低于 1500,不高于 5000。
总训练步数=(Image 图片数量 x Repeat 每张图片训练步数 x Epoch 训练轮次)/ batch_size 并行数量。
训练完成后,模型文件会保存到设置的输出目录。比如 epoch 训练轮次设置了 5,就会得到 5 个训练好的 LoRA 模型。
四、模型测试
模型训练完成后,要对训练好的这些模型进行测试,以找出最适合的那个模型(哪个模型在哪个权重值下表现最佳)。
① 把训练好的 LoRA 模型全部放入 LoRA 模型目录 stable-diffusion-webui/models/Lora。

② 打开 Stable Diffusion WebUI,在 Stable Diffusion 模型里先加载个模型训练时的底模,LoRA 模型里加载一个刚才训练好的 LoRA 模型,如 000001 模型,填上一些必要的提示词和参数。

划重点:把引入的 LoRA 模型提示词,改成变量模式,如: 改成 ,NUM 变量代表模型序号,STRENGTH 变量代表权重值。

③ 在 Stable Diffusion WebUI 页面最底部的脚本栏中调用 XYZ plot 脚本,设置模型对比参数。
划重点:其中 X 轴类型和 Y 轴类型都选择「提示词搜索/替换」Prompt S/R。
X 轴值输入:NUM,000001,000002,000003,000004,000005,对应模型序号
Y 轴值输入:STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1,对应模型权重值
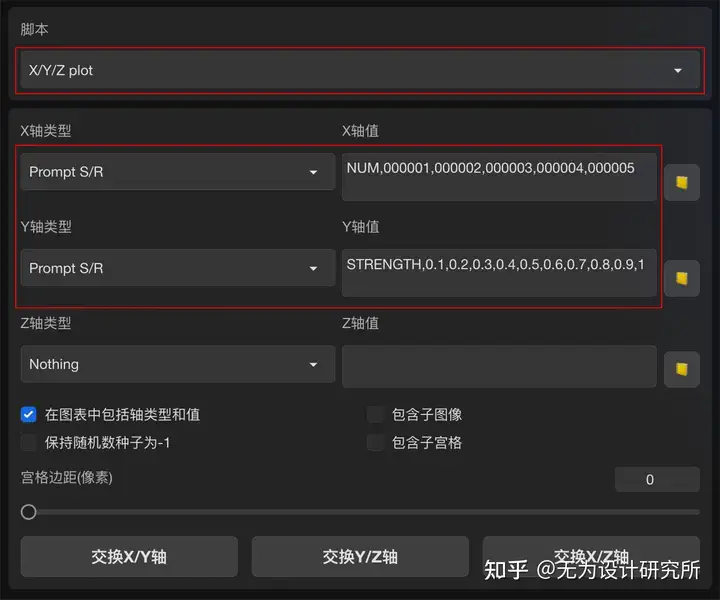
这样就形成了一张模型测试对比表。

设置完毕后,点击「生成」,开始生成模型测试对比图。
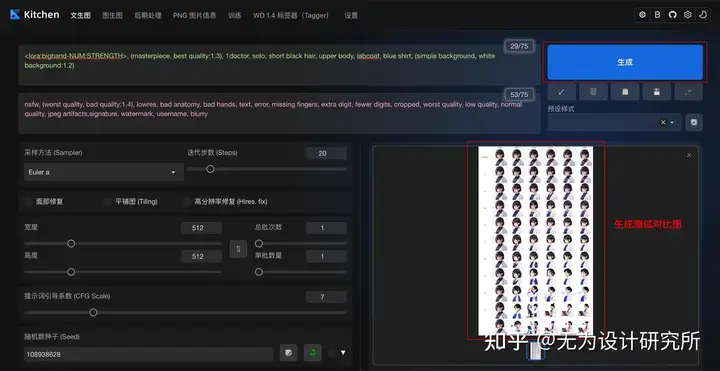
通过对比生成结果,选出表现最佳的模型和权重值。

把选出的 LoRA 训练模型做一个规范化命名,比如 bighand_lora_v1,重新刷新 LoRA 模型列表就能加载使用啦。在实际应用中,我们可以结合 ControlNet 来使用,以提升可控性。
最后总结下 LoRA 模型训练的要点:
- 训练数据集准备(训练素材处理、图像预处理、打标优化)
- 训练环境参数配置(本地或云端训练环境、训练环境配置、训练参数配置)
- 模型训练(基于 kohya-ss 训练模型)
- 模型测试(通过 XYZ plot 测试模型)
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Hacker News是一个提供专业技术分享的社区,包括文章、图像视频等。页面极其简单,没有广告。