大模型中的Top-k、Top-p、Temperature详细含义及解释
发布时间:2024年06月06日
Top-k & Top-p
选择输出标记的方法是使用语言模型生成文本的一个关键概念。有几种方法(也称为解码策略)用于选择输出token,其中两种主要方法是 top-k 采样和 top-p 采样。
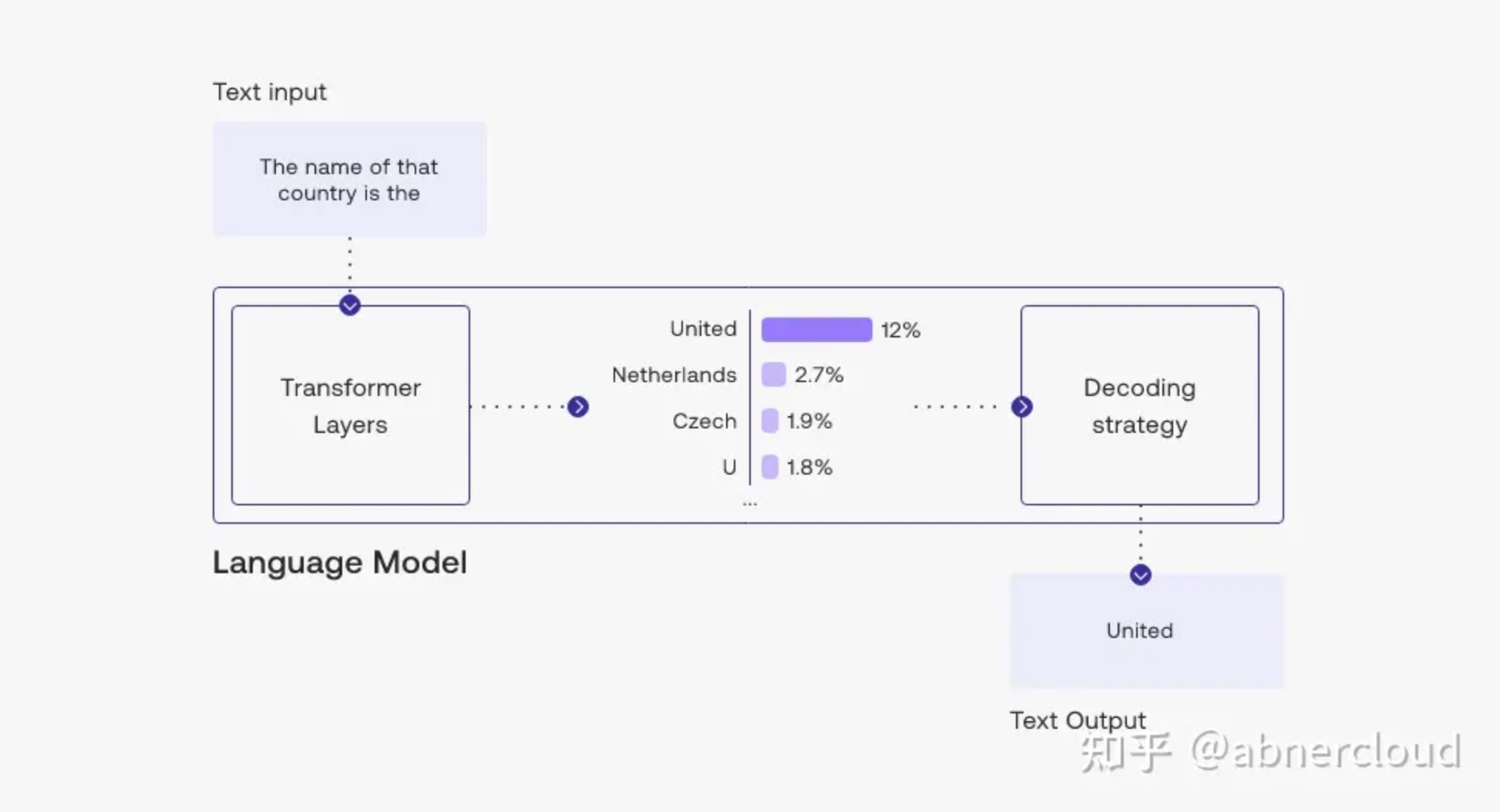
让我们看一下示例,模型的输入是这个prompt文本 The name of that country is the :
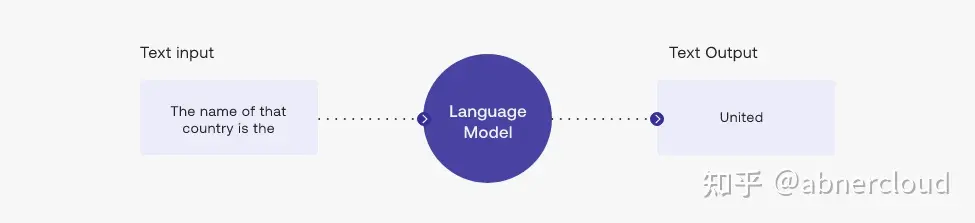
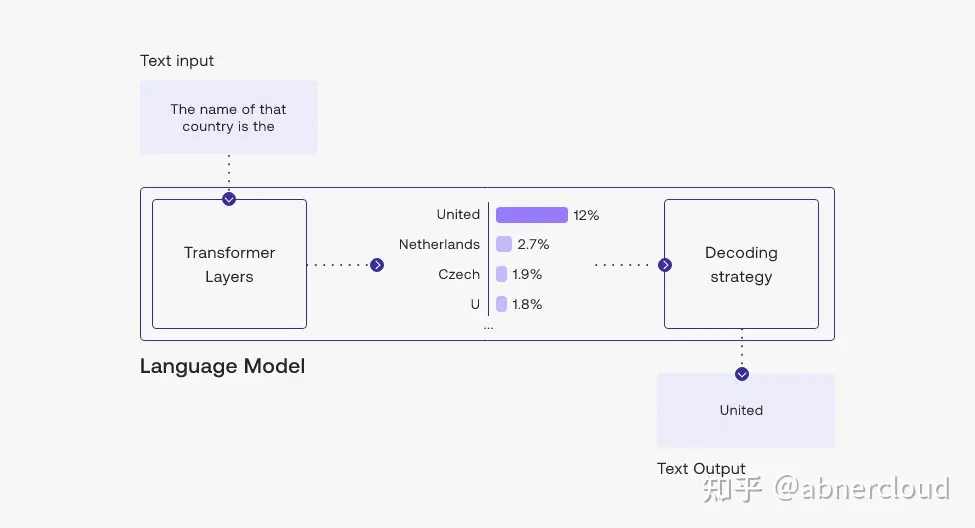
在这种情况下,输出标记 United 是在处理的最后一步选择的——在语言模型处理输入并计算其词汇表中每个标记的似然分数之后。 该分数表示它将成为句子中下一个标记的可能性(基于训练模型的所有文本)。
1.挑出top token:贪心解码
您可以在此示例中看到,我们选择了可能性最高的标记“United”。
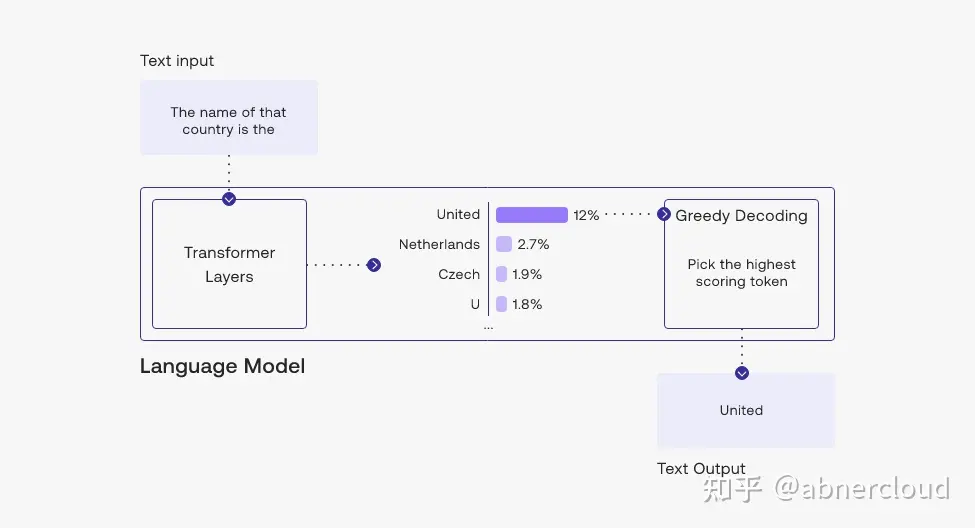
贪心解码是一种合理的策略,但也有一些缺点,例如输出带有重复文本循环。想一想智能手机的自动建议中的建议。当您不断选择最高建议的单词时,它可能会变成重复的句子。
2.从top tokens中挑选:top-k
另一种常用的策略是从前 3 个tokens的候选名单中抽样。这种方法允许其他高分tokens有机会被选中。这种采样引入的随机性有助于在很多情况下生成的质量。
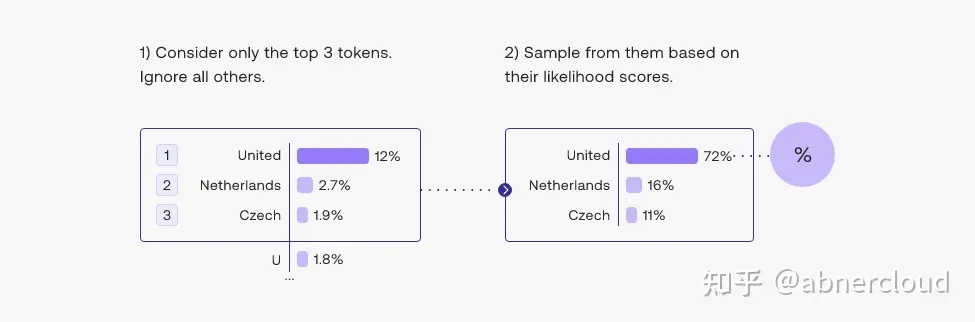
更广泛地说,选择前三个tokens意味着将 top-k 参数设置为 3。更改 top-k 参数设置模型在输出每个token时从中抽样的候选列表的大小。将 top-k 设置为 1 可以进行贪心解码。
3.从概率加起来为15%的top tokens中挑选:top-p
选择最佳 top-k 值的困难为流行的解码策略打开了大门,该策略动态设置tokens候选列表的大小。这种称为Nucleus Sampling 的方法将可能性之和不超过特定值的top tokens列入候选名单。top-p 值为 0.15 的示例可能如下所示:

Top-p 通常设置为较高的值(如 0.75),目的是限制可能被采样的低概率 token 的长尾。我们可以同时使用 top-k 和 top-p。如果 k 和 p 都启用,则 p 在 k 之后起作用。
Temperature
从生成模型中抽样包含随机性,因此每次点击“生成”时,相同的提示可能会产生不同的输出。温度是用于调整随机程度的数字。
采样时如何选择温度
较低的温度意味着较少的随机性;温度为 0 将始终产生相同的输出。执行具有“正确”答案的任务(如问题回答或总结)时,较低的温度(小于 1)更合适。如果模型开始自我重复,则表明温度过低。
高温意味着更多的随机性,这可以帮助模型给出更有创意的输出。如果模型开始偏离主题或给出无意义的输出,则表明温度过高。
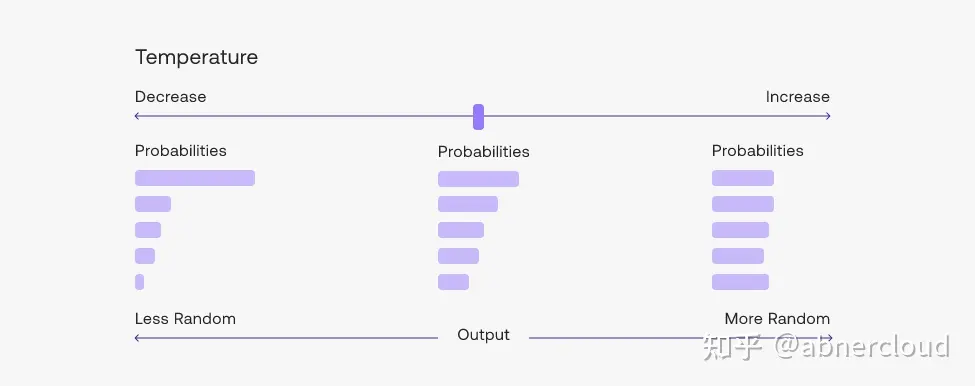
可以针对不同的问题调整温度,但大多数人会发现温度 1 是一个很好的起点。
随着序列变长,模型自然会对其预测更有信心,因此您可以在不偏离主题的情况下为长提示提高温度。相反,在短提示上使用高温会导致输出非常不稳定。
Likelihood
我们的模型通过阅读从互联网上抓取的文本来学习建模语言。 给定一个句子,例如 I like to bake cookies,要求模型重复预测下一个标记 [?] 是什么:
I [?]
I like [?]
I like to [?]
I like to bake [?]
I like to bake cookies该模型了解到单词 to 很可能跟在英语中的 like 之后,而 cookies 很可能跟在 bake 之后。
Intuition
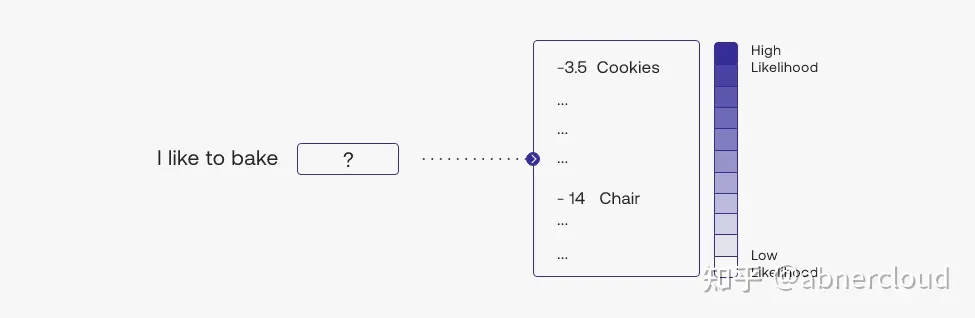
token的可能性可以被认为是一个数字(通常在 -15 和 0 之间),它量化模型对句子中使用该token的意外程度。 如果token的可能性很低,则意味着模型不希望使用该token。 相反,如果token具有很高的可能性,则该模型有信心使用它。 例如,使用我们的 Large 模型,句子“I like to”中出现“to”的可能性大约为 -1.5。 这是相当高的,这意味着模型相当有信心 I like 的标记后面会跟着标记 to.. 同样,从句子 I like to bake cookies 中出现 cookies 的可能性大约为 -3.5,略低于 前面的例子(这很直观:brownies 或 cake也是合理的选择),但仍然很高。 但是,如果我们将句子更改为 I like to bake chairs ,那么token chairs 的可能性就会大大降低,大约为 -14。 这意味着该模型对其在句子中的使用感到非常意外。
Number of Generations
当您调用 Generate endpoint 时,您可以选择在一次调用中生成多个结果。 这是通过设置 num_generations 参数来完成的。
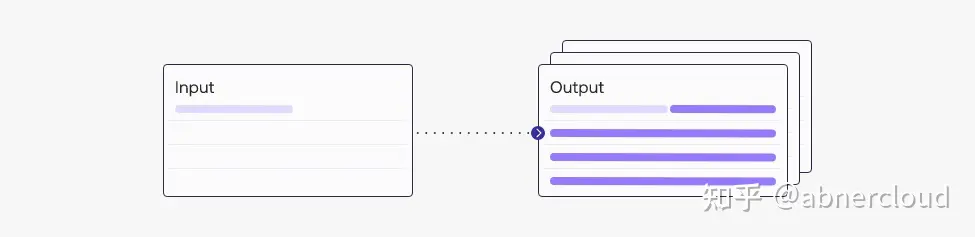
模型的输出将根据您指定的生成设置而有所不同,例如温度、top-k 和 top-p。
每一个生成结果都有其一组似然值,其中包括:
- 每个生成的 token 的可能性
- 所有生成的标记的平均可能性。
Example
此示例使用输入:“This curved gaming monitor delivers ...”
使用最大token集为 4 生成并按平均标记似然排序的输出为:
Likelihood Text
-0.96 a truly immersive experience
-1.11 a virtually seamless view
-1.70 the ultimate viewing experience
-2.15 a 144Hz rapid
-2.44 a comfortable and stylish您可以通过多种方式使用这些输出,例如,选择可能性最高的输出作为最终输出,或者将这些作为选项呈现在您的应用程序中。
From: Top-k & Top-p , Temperature
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款利用AI训练的艺术和写实模型生成独特惊艳的图像的AI图像生成器。它能够将想象力变成现实,帮助用户将他们的想法变成美丽的艺术品。