【Stable Diffusion操作升级】Stable Diffusion 常用模型下载与说明
发布时间:2024年06月06日
相比于Midjourney,Stable Diffusion最大的优势就是开源。相比于Midjourney靠开发人员开发的少数模型,SD则每时每刻都有人在世界各地训练自己的模型并免费公开共享给全世界的使用者。(当然你可以通过训练自己的专有模型而专门用于某一用途,这也将成为你作为AI绘画者的最重要的核心竞争力之一)
因此,学会使用各类模型对于学习使用Stable Diffusion非常重要。
常用模型下载网址推荐
目前,模型数量最多的两个网站是https://civitai.com/和https://huggingface.co/。civitai又称c站,有非常多精彩纷呈的模型,有了这些模型,我们分分钟就可以变成绘画大师,用AI画出各种我们想要的效果。
C站长这样:
你会看到很多模型的预览图被屏蔽了,需要你认证为成人才能浏览。至于为什么要成人才能浏览,想必大家也是懂的都懂。
也正是如此,该网站在国内是被屏蔽的。登录需要科学上网。
Huggingface则相对朴实无华一些,对模型的审核也会更加严格一些。但是好处在于不需要科学上网,而且网速很快。
Huggingface界面如上。
它是一个综合性的网站,如果我们需要下载模型的话,选择Models。
进入之后,选择Text-to-Image,出来的就都是SD可以用的模型了。
除了C站和huggingface,其他的模型网站还有:
https://cyberes.github.io/stable-diffusion-models/
(SD的基础模型,不用科学上网,但是这些模型都一般般,意义不大)
(模型很多,但是界面没有C站友好,需要科学上网)
(国内的网站,很多都是搬运的C站的模型,合规性未知,通过百度网盘下载)
LiblibAI,号称是国内最大的原创AI模型分享网站,但其实很多都是搬运的C站的模型,不过确实也有不少人气原创模型发布者入驻了该网站。
不同模型的说明
如果你去自己下载模型,就会发现有各种不同类型的模型。
具体模型类型有checkpoint、Textual lnversion、Hypernetwork、Aesthetic Gradient、LoRA、LyCORIS、Controlnet、Poses、wildcards等等,看得人眼花缭乱。这些都是什么意思呢?
Checkpoint/大模型/底模型/主模型
Checkpoint模型是SD能够绘图的基础模型,因此被称为大模型、底模型或者主模型,WebUI上就叫它Stable Diffusion模型。安装完SD软件后,必须搭配主模型才能使用。不同的主模型,其画风和擅长的领域会有侧重。
checkpoint模型包含生成图像所需的一切,不需要额外的文件。但是它们体积很大,通常为2G-7G。
常见文件模式:尾缀ckpt、safetensors(如果都有提供的话建议下载safetensors,下同)
存放路径: \sd-webui-aki-v4\models\Stable-diffusion
模型的切换界面:

目前比较流行和常见的checkpoint模型有Anything系列(v3、v4.5、v5.0)、AbyssOrangeMix3、ChilloutMix、Deliberate、国风系列等等。这些checkpoint模型是从Stable Diffusion基本模型训练而来的,相当于基于原生安卓系统进行的二次开发。目前,大多数模型都是从 v1.4 或 v1.5 训练的。它们使用其他数据进行训练,以生成特定风格或对象的图像。这个我们后面还会专门开一个专题进行讲解。
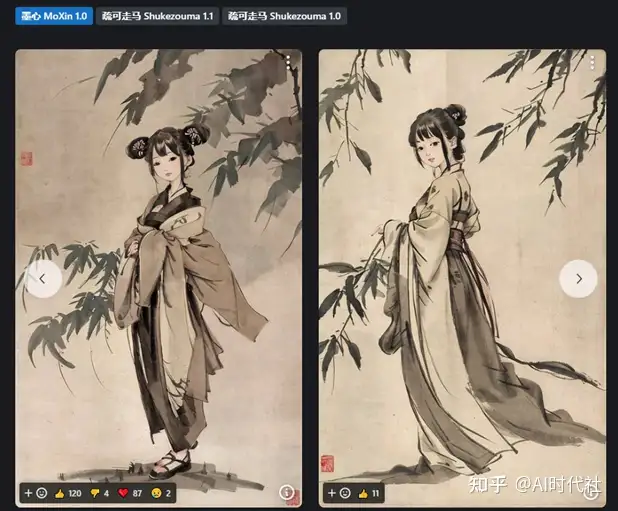
不同模型在同一参数下的表现有时候可以用天差地别来形容,下面是个例子:

LoRA
当下最火的微调模型,可以将某一类型的人物或者事物的风格固定下来。它们通常为10-200 MB。必须与checkpoint模型一起使用。
现在比较火的Korean Doll Likeness、Taiwan Doll Likenes、Cute Girl mix都是真人美女LoRA模型,效果很惊艳。还有一些特定风格的LoRA也非常受欢迎,最著名的有墨心等。这个我们后面也会再开一个专题讲解。
常见文件模式:尾缀ckpt、safetensors、pt
存放路径: \sd-webui-aki-v4\models\Lora
有多个方式可以使用
方法1是在生成界面调取选用。这个的好处是可以自己设置预览图,从而有直观的感受。
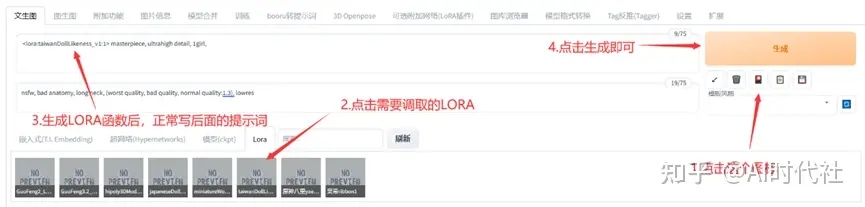
而且部分LORA只支持这种方式使用(不过AI绘画日新月异,说不定哪天规则又变了~)
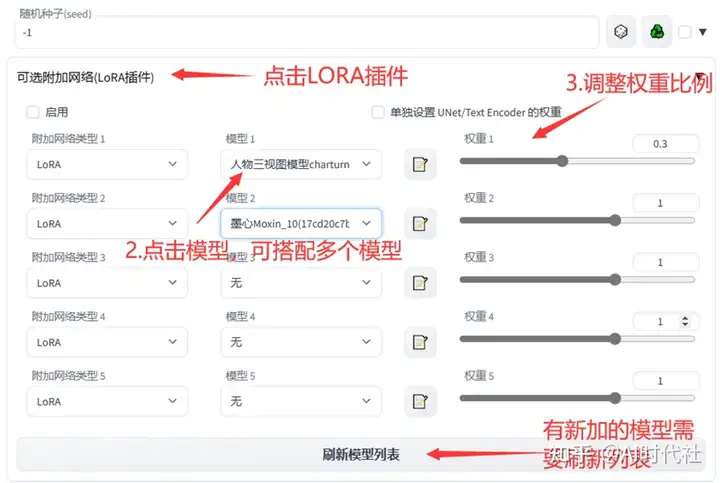
方法2是以插件形式使用。好处是可以很方便的灵活调用多个LORA,并对他们按着不同比例进行混合。

在启动器界面选择模型管理,点击LoRA模型(插件),点击添加模型,选择你要添加的LoRA模型,重启启动器。然后在WebUI界面选择相应的插件和权重比例即可。
VAE美化模型/变分自编码器
VAE,全名Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。
有的大模型是会自带VAE的,比如Chilloutmix。如果再加VAE则可能画面效果不会更好,甚至适得其反。
顺便说一句,系统自带的VAE是animevae,效果一般,建议可以使用kl-f8-anime2或者vae-ft-mse-840000-ema-pruned。anime2适合画二次元,840000适合画写实人物。
常见文件模式: 尾缀ckpt、pt
存放路径: \sd-webui-aki-v4\ models\ VAE
模型的切换:

Embedding/Textual lnversion/文本反转模型和Hypernetworks
Embeddings 和 Hypernetworks 都属于微调模型,但目前Hypernetworks已经不太用了。
Embeddings/Textual lnversion中文翻译过来叫文本反转,通过仅使用的几张图像,就可以向模型教授新的概念。用于个性化图像生成。Embeddings是定义新关键字以生成新人物或图片风格的小文件。它们很小,通常为10-100 KB。必须将它们与checkpoint模型一起使用。
Embeddings 由于训练简单,文件小,因此一度很受大家欢迎。而且Embeddings 使用方法很简单,在安装之后,只要在提示词中提到它就相当于调用了,很方便。但由于Embeddings使用的训练集较小,因此出来的图片常常只是神似,做不到”形似“,所以目前很多人还是喜欢使用LORA模型。而且Embeddings 是一级目录,每次打开webui时都要加载一遍,太多了会影响webui的“开机速度”(但是不影响运行速度)。
不过有一些Embeddings 还是值得安装,比如EasyNegative这个Embeddings,里面包含了大量的负面词,可以减少你每次打一堆负面词的痛苦。
Embedding
常见文件模式: 尾缀pt
存放路径: \sd-webui-aki-v4\ embeddings
模型的切换通过文件名称来触发
Hypernetworks
常见文件模式: 尾缀pt
存放路径: \sd-webui-aki-v4\ models\ Hypernetworks
模型的切换通过文件名称来触发
DreamBooth模型
DreamBooth,可用于训练预调模型用的。是使用指定主题的图像进行演算,训练后可以让模型产生更精细和个性化的输出图像。
常见模式:尾缀ckpt、safetensors
常见大小:2G-7G
最新版本的DreamBooth是可以把那个Lora算法然后融合进来的
可以训练角色、画风、物件等,使用方法和主模型相同
训练路径:
LyCORIS模型
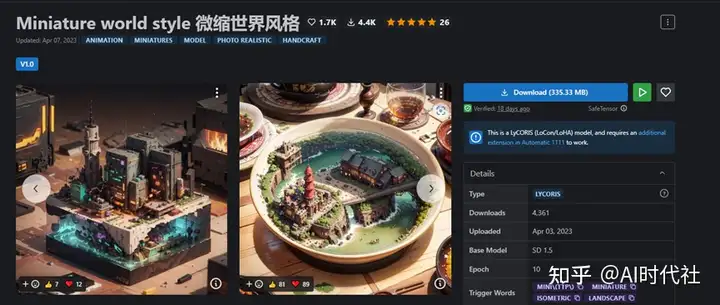
此类模型也可以归为Lora模型,也是属于微调模型的一种。一般文件大小在340M左右。不同的是训练方式与常见的lora不同,但效果似乎会更好不少。
其中本人较喜欢的“Miniature world style 微缩世界风格”就属于这类模型。
但要使用此类微调模型,需要先安装一个locon插件,直接将压缩包解压后放到StableDiffusion目录的extensions目录里。
插件地址
https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
下载后直接解压缩在extensions中。
使用时注意,除了要将lora调入,还要在正向tag开头添加触发词
例如:这个微缩世界风格的lyCORIS的调用,正向描述语如下
mini\(ttp\), (8k, RAW photo, best quality, masterpiece:1.2), island, cinematic lighting,UHD,miniature, landscape, Crystal ball,on rock, <lora:miniatureWorldStyle_v10:0.8>
小技巧
如果你下载了一个模型,却不知道怎么安装,打开这个网站
把你下载的模型拖进去,立马就会帮你解析,告诉你应该放在那里。
不过,由于AI绘画日新月异,有的模型,网站可能还来不及收集和解析,会无法解读。

如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
智绘设计,多场景智能设计服务商,是腾讯推出的面向创作者以及企业的素材智能化设计生产平台,其聚焦于泛内容领域,提供用户在线工具以创作各种形态的素材,可用于传统行业和新媒体等运营工作。