企业如何更好的使用大模型?都有哪些框架和方案
发布时间:2024年06月06日
2022年底,OpenAI基于大语言模型发布了聊天应用ChatGPT,推出仅一个月活跃用户破亿,吸引全球范围的广泛关注。ChatGPT的出现将人工智能推向全球关注的中心舞台,大语言模型带动的新一轮人工智能浪潮,正以前所未有的速度席卷全球。据统计,目前全球大型语言模型相关的创业公司已超过200家,投资总额达到70亿美元。
TechCrunch的数据显示,2022年前三个季度全球人工智能的投资已达到560亿美元,创下历史新高。其中,融资较高的创业公司包括Anthropic、Cohere、AI21 Labs等,这些公司的技术都建立在大型语言模型的基础之上。
大模型落地的挑战
对于个人用户,大语言模型带来了前所未有的高度个性化体验。它能够与用户进行流畅的对话,并提供即时且针对性的回应。借助基于大型语言模型的AI写作助手,用户能够快速生成高质量的文章草稿,其风格与用户贴合,极大提高了内容创作效率。然而,大模型要在企业侧真正落地仍然面临很大挑战,总结为下面四个方面:
-
大模型专业深度不够,数据更新不及时,缺乏与真实世界的连接。例如,在法律政策解读、电商客服、投资研报等专业领域中,由于大型模型缺乏足够的专业领域数据,用户在使用过程中经常会感觉大模型在一本正经地“胡说八道”。
-
大模型有Token的限制,记忆能力有限。大家之所以惊艳于ChatGPT流畅丝滑的对话能力,有很大一部分原因是其支持多轮对话。用户提问时,ChatGPT不但能理解意图,而且还能够基于之前的问答做综合推理。然而,大模型由于Token的限制,只能记忆部分的上下文。比如ChatGPT 3.5只能记忆4096个Token,无法实现长期记忆。
-
用户对于数据安全的担忧。大模型的出现让AI成为一种普惠技术,人人都可以基于大模型构建AI的应用。AI技术本身不再是商业壁垒,数据才是。而企业要想利用大模型构建商业,必须将自己的数据全部输送给大模型,以进行推理和表达。如何在数据安全可控的情况下使用大模型技术,成为一个亟待解决的问题。
-
使用大模型的成本问题。目前有两种模式可以使用大模型,一是将大模型本地化,用于再训练形成企业专有的模型。二是利用公有云模型,按照请求的Token数量付费。第一种方式成本极高,大模型由于有数千亿的模型参数,光部署计算资源的投资就得上亿。重新训练一次模型也需要近千万的投入,非常烧钱。这对于一般的中小企业是完全无法承受的。第二种方式企业构建的AI应用可以按照Token数量付费,虽然无需一次性的大额投入,但成本依然不低。以OpenAI为例,如果对通用模型进行微调(Fine-tuning)后,每使用1000个token(约600汉字)需要0.12美金。
企业级解决方案
针对上述问题,目前主要有三个解决方案:
-
第一是将大模型部署到企业本地,结合企业私有数据进行训练,打造垂直领域专有模型。
-
第二是在大模型基础上进行参数微调,改变部分参数,让其能够掌握深度的企业知识。
-
第三种是围绕向量数据库打造企业的知识库,基于大模型和企业知识库再配合Prompt打造企业专属AI应用。
从实用性和经济性的角度考虑,第三种是最为有效的解决方案。该方案大致实现方式如下所示。
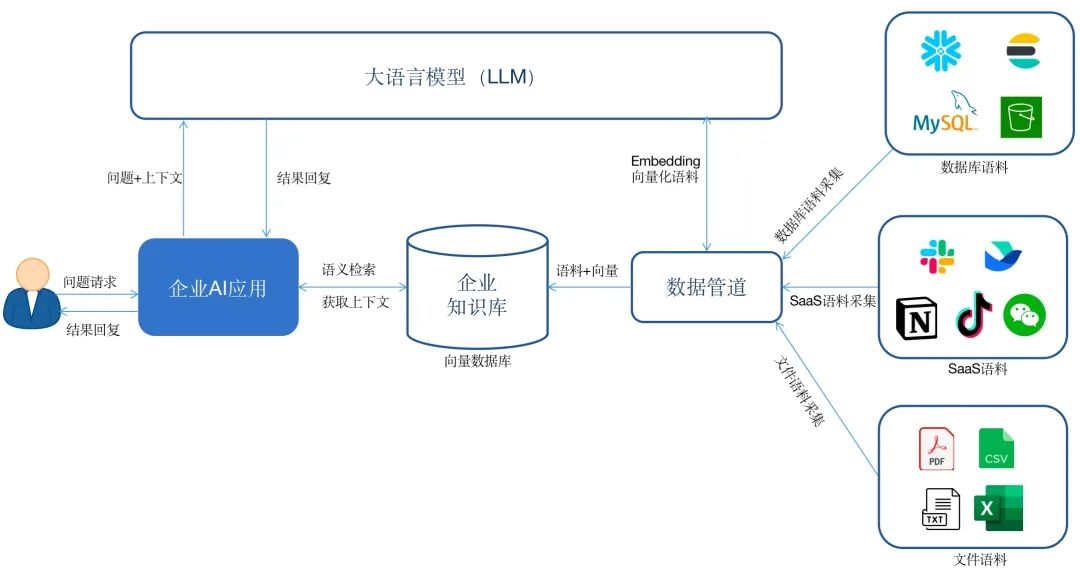
企业首先基于私有数据构建一个知识库。通过数据管道将来自数据库、SaaS软件或者云服务中的数据实时同步到向量数据库中,形成自己的知识库。
在这个过程中需要调用大模型的Embedding接口,将语料进行向量化,然后存储到向量数据库。当用户与企业AI应用对话时,AI应用首先会将用户的问题在企业知识库中做语义检索,然后将检索的相关答案和问题以及配合一定的prompt一并发给大模型,获得最终的答案之后回复给用户。
该方案有如下优势:
-
充分利用大模型和企业优势:既可以充分利用企业已有知识,又可以利用大模型强大的表达和推理能力,二者完美融合。
-
使AI应用具备长期记忆:Token的限制使大模型只能有短暂的记忆,无法将企业所有知识全部记住。利用外置的知识库,可以将企业拥有的海量数据资产全部整合,帮助企业AI应用构建长期记忆。
-
企业数据相对安全可控:企业可以在本地构建自己的知识库,避免核心数据资产外泄。
-
落地成本低:通过该方案落地AI应用,企业不需要投入大量资源建设自己的本地大模型,帮助企业节省动辄千万的训练费用。
大模型中间件
企业要落地该知识库方案仍然有一些具体问题需要解决,总结下来主要涉及三个方面。
第一方面是知识库的构建。企业需要将存在现有系统中的语料汇总到向量数据库,形成企业自有的知识空间,这个过程涉及数据采集、清洗、转换和Embedding等工作。语料来源比较多样,可能是一些PDF、CSV等文档,也可能需要接入企业现有业务系统涉及比如Mongodb、ElasticSearch等数据库,或者来自抖音、Shopify、Twitter等第三方应用。在完成数据的获取后,通常需要对数据进行过滤或者转化。这个过程中,从数据源实时地获取数据非常重要,比如电商机器人需要实时了解用户下单的情况,政策解读机器人需要了解最新政策信息。另外,对于数据Embedding的过程中涉及到数据的切块,数据切块的大小会直接影响到后面语义搜索的效果,这个工作也需要非常专业的NLP工程师才能做好。
其次是AI应用的集成。AI应用需要服务的用户可能存在于微信、飞书、Slack或者企业自有的业务系统。如何将AI应用与第三方SaaS软件进行无缝集成,直接决定用户的体验和效果。
第三是数据安全性的问题。这个方案没有完全解决数据安全性的问题,虽然企业的知识库存储在本地,但是由于企业数据向量化的过程中需要调用公有云大模型Embedding接口。这个过程需要将企业数据切块之后发送给大模型,一样有数据安全的隐患。
对于上述大模型落地问题的解决,大模型中间件是其中的关键。
什么是大模型中间件?大模型中间件是位于AI应用与大模型之间的中间层基础软件,它主要解决大模型落地过程中数据集成、应用集成、知识库与大模型融合等问题。
下图给出了企业AI应用的典型软件架构,一共分为大语言模型、向量数据库、大模型中间件以及AI应用四层。
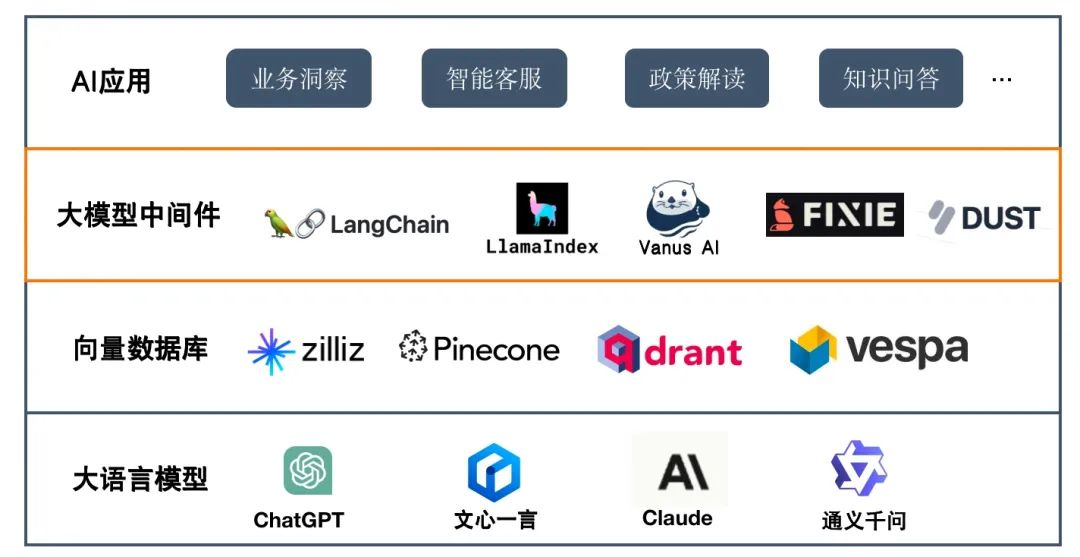
大语言模型为AI应用提供基础的语义理解、推理、计算能力,向量数据库主要提供企业知识的存储和语义搜索。而大模型中间件解决大模型落地的最后一公里,提供语料的实时采集、数据清洗、过滤、embedding。同时,为上层应用提供访问大模型与知识库的入口,提供大模型与知识库的融合、应用部署、应用执行。
常见的大模型中间件
自去年ChatGPT发布以来,短短几个月内就涌现出了不少新的大模型中间件项目。例如,面向AI应用的编程框架Langchain在GitHub上短短几个月内收获了超过4万个Star。Langchain旨在简化开发者基于大型语言模型构建AI应用的过程。它为开发者提供了多模型访问、Prompt的封装、多数据源加载等多种接口,让开发者构建AI应用更简单。Llamaindex是另一个备受关注的开源项目,它目标是为大型模型提供统一的接口来访问外部数据。比如Llamaindex的Routing为开发者语义检索、基于事实混合查找、访问总结数据可以提供统一索引。Vanus AI 是一个无代码构建AI应用的中间件,用户通过Vanus AI可以分钟级构建出生产可用的AI应用。它同时提供了实时知识库构建、AI应用集成、大模型插件等能力。Fixie是一家初创公司,近期刚刚融资1200万美金,该公司的目标是构建、部署和管理大型模型代理平台,以更好地响应用户的意图。
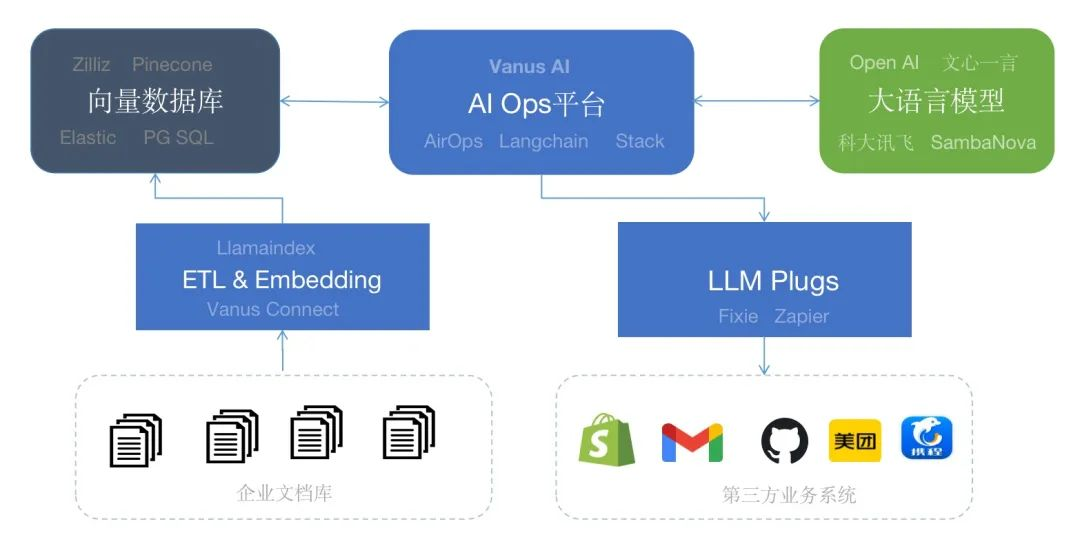
对近期项目进行了梳理,形成下图的AI Stack。企业的私有业务数据通过 Embedding组件转化成向量后可以存储到Milvus、Pinecone等向量数据库中。目前通过Llamaindex、Vanus Connect可以批量获取PDF、CSV等文件并Embedding并存储到向量数据库中。AirOps、Vanus AI等AI Ops平台可以连接大模型和企业知识库帮助用户一站式构建AI的应用。如果AI应用需要连接第三方的应用执行操作可以通过Fixie或者Zapier等提供了插件。
总结
本文围绕大模型在企业落地所面临的挑战展开,提出了大模型中间件的概念。大模型中间件是基于AI应用与大模型之间的中间层基础软件,它可以打通企业AI应用落地的最后一公里,是构建AI应用的必备软件。本文提出了企业AI应用软件的典型架构,并指出了大模型中间件在AI软件中的定位以及核心作用。最后,文章介绍了目前较为流行的大模型中间件,并阐述了不同的大模型中间件在落地应用过程中具体作用。
作者简介:厉启鹏,vanus.cn CEO,北京大学硕士。曾就职于阿里云,Apache RocketMQ PMC 。长期专注于AI基础设施软件及中间件, 技术交流可加微信kdliqipeng。
参考文献:
1. Augmented language models https://drive.google.com/file/d/1A5RcMETecn6Aa4nNzpVx9kTKdyeErqrI/view
2. So you want to build an AI application powered by LLM: Let’s talk about Embedding and Semantic Search https://blog.devgenius.io/so-you-want-to-build-an-ai-application-that-utilizes-llm-lets-talk-about-embedding-and-semantic-166acfc013a6
3. So you want to build an AI application powered by LLM: Let’s talk about Data Pre-Processing https://blog.devgenius.io/so-you-want-to-build-an-ai-application-that-utilizes-llm-lets-talk-about-data-pre-processing-7fc7cf871d08
4. Chunking Strategies for LLM Applications https://blog.devgenius.io/so-you-want-to-build-an-ai-application-that-utilizes-llm-lets-talk-about-embedding-and-semantic-166acfc013a6
5. Unifying LLM-powered QA Techniques with Routing Abstractions https://betterprogramming.pub/unifying-llm-powered-qa-techniques-with-routing-abstractions-438e2499a0d0
6. Build a Chatbot on Your CSV Data With LangChain and OpenAI https://betterprogramming.pub/build-a-chatbot-on-your-csv-data-with-langchain-and-openai-ed121f85f0cd
原文出处:https://mp.weixin.qq.com/s/nERvhYUd4_dO6Z9N2cQVqg
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
提供各类字体免费下载和预览