颠覆数据存储方式:向量数据库的威力
发布时间:2024年06月06日
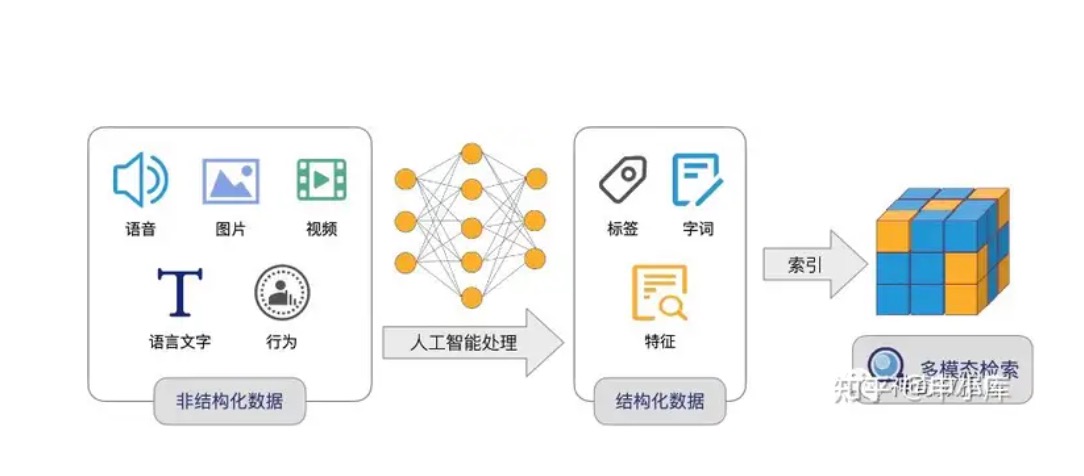
向量数据库是一种新型的数据库类型,它与传统的关系型数据库和文档型数据库不同。它主要基于向量相似度搜索,可以更快速地处理大规模的高维数据。在向量数据库中,数据被表示为向量形式,每个向量具有多个维度,每个维度对应着不同的特征。向量数据库通过计算向量之间的相似度来搜索数据,因此它特别适用于人脸识别、语音识别、推荐系统等需要高维度数据处理的领域。与传统的数据库相比,向量数据库能够更快速地处理大规模的数据,并且能够快速地进行向量相似度搜索,因此在大数据时代中,向量数据库具有巨大的应用潜力和发展前景。
什么是向量数据
向量数据是一种数学表示,用一组有序的数值(通常是浮点数)表示一个对象或数据点。向量通常用于在多维空间中表示数据点的位置、特征或属性。
[0.12, 0.32, -0.5]
在计算机视觉中,图像可以通过一组数值(即像素值)表示,这组数值构成一个向量。每个数值对应于图像中一个像素的颜色强度。例如,一个 8x8 的灰度图像可以表示为一个包含 64 个数值的向量
在推荐系统中,用户和物品可以用向量表示,以捕捉其特征和属性。例如,用户可能对电影类型、导演、演员等方面有偏好,这些偏好可以用一个数值向量表示。通过计算用户向量与物品向量之间的相似度,可以实现个性化的推荐。
在自然语言处理中,词嵌入是一种将文本数据转换为向量数据的方法。例如,使用 Word2Vec 或 GloVe 算法,可以将单词表示为一个包含多个数值的向量。这些数值捕捉了单词的语义特征,使得相似含义的单词在向量空间中彼此靠近。
示例:假设有两个句子:
"这部电影很好看,值得一看。"
"这是一部非常精彩的电影,推荐观看。"
将这两个句子转换为向量表示后,计算它们之间的余弦相似度。如果相似度较高,说明两句子在语义上相似;如果相似度较低,说明它们在语义上不相似。
向量数据的结构
向量数据的典型结构是一个一维数组,其中的元素是数值(通常是浮点数)。这些数值表示对象或数据点在多维空间中的位置、特征或属性。向量数据的长度取决于所表示的特征维度。下面是一个简单的例子:
假设我们有三个水果:苹果、香蕉和葡萄。我们想用向量数据表示它们的颜色和大小特征。我们可以将颜色分为红、绿、蓝三个通道,将大小分为小、中、大三个类别。因此,我们可以用一个包含 6 个数值的向量表示每个水果的特征。
苹果(红色,中等大小):[1, 0, 0, 0, 1, 0]
香蕉(黄色,大):[0, 1, 0, 0, 0, 1]
葡萄(紫色,小):[0.5, 0, 0.5, 1, 0, 0]
在这个例子中,每个水果都被表示为一个 6 维向量。前三个数值表示颜色信息(红、绿、蓝通道),后三个数值表示大小信息(小、中、大)。
细心的你可能会发现,紫色的向量表示是 [0.5, 0, 0.5],没错,这代表紫色是由红色和蓝色组成。
这种数组结构是典型的向量数据表示。
向量数据的计算
有了向量数据,怎么用呢?这里面有没有一些通用的计算模式?
向量数据的结构非常简单,但针对不同的场景,衍生出了多种计算方法。
比如最常见的有向量相似度计算:衡量两个向量之间的相似程度。常用的相似度度量方法包括余弦相似度、欧几里得距离、曼哈顿距离等。
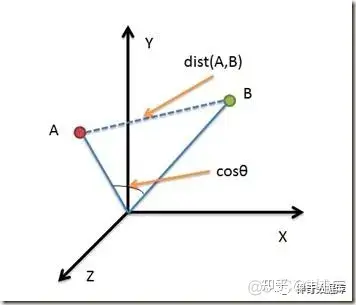
这种计算模式非常普及,在推荐系统中评估用户和物品的相似度,以及在自然语言处理中评估文本或单词的相似度时非常有用。
其他计算模式,还包括加权平均、向量内积、外积、矩阵乘法、池化、归一化等等,这里就不再一一赘述了。
每一种计算模式,都可以映射到数学理论中关于向量、矩阵运算,而背后的应用场景大多集中在计算机视觉、图像处理、文本处理、自然语言处理、神经网络等多模型通用人工智能领域。
支持向量数据的数据库
ChatGPT被誉为 AGI 领域的『iPhone时刻』,越来越多人关注自然语言处理与通用人工智能在自己领域内的应用。
向量是 AI 世界对世间万物的表示形式,随着大模型等AI技术的发展和普及,向量数据的存算需求一定会得到极大的释放。
现阶段,大量的向量数据可能还散落在各种文件中,并没有使用标准的向量数据库去存。
但未来,专业的事一定是要交给专业的人。有严谨的数学理论支撑的向量数据,也一定会逐渐下沉到标准的专业的向量数据库中,这样才能使得整个社会的IT成本更低,效率更高。
回顾过去,从2019年开始,一些通用的数据库,开始增加对向量数据库的支持,比如ElasticSearch、Redis、PostgreSQL。
Elasticsearch 本身是一个分布式全文搜索和分析引擎,但增加支持了dense_vector数据类型来存储稠密向量。通过使用内置的向量函数,如cosineSimilarity、dotProduct和l2norm等,可以实现一些基本的向量计算。
Redis 可通过一些扩展模块,如RedisAI和RediSearch,实现一定程度的向量数据处理和计算功能。RedisAI 偏深度学习模型,支持TensorFlow、PyTorch和ONNX运行时。RediSearch 偏全文检索,支持一些基本的文本相似度度量,如TF-IDF和Levenshtein距离等。
PostgreSQL 可通过扩展 pgvector 实现一些简单的向量计算。
这些通用数据库虽然有一定的向量计算的能力,但它们的主要关注点和优化目标并不在此。针对这些计算模式,专门为向量数据设计的数据库(如Milvus、Pinecone等)可能提供更好的性能和支持。
Milvus 是一个开源的向量搜索引擎,zilliz 是他们的Cloud云服务,已经在海外上线,支持AWS,Azure,GCP,国内基于阿里云的版本也即将在5月份对外发布。
Pinecone 的定位是做AI的持久化存储,提供 Cloud 云服务,基于GCP和AWS。
Milvus和Pinecone都是专为向量数据设计的数据库,它们在处理大规模、多维度向量数据和计算模式方面具有较强的能力,特别是在向量搜索和相似度计算方面,具有更低的查询延迟和更高的准确性,支持丰富的距离度量方法,如欧几里得距离、余弦相似度、汉明距离、曼哈顿距离等。
对于其他类型的向量计算任务,Milvus和Pinecone都可以与其他工具(如 NumPy、TensorFlow 等)结合使用。
类似的产品还有Weaviate ,它是一个开源的知识图谱和语义搜索引擎,支持向量数据的存储和检索。除了向量搜索功能外,Weaviate 还提供了丰富的知识图谱操作和查询功能,如 GraphQL 查询。Weaviate 集成了模型训练和转换功能,可以自动生成和优化向量表示。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Wized.AI是一个通过AI技术自动生成个性化简历的网站。他们利用自然语言处理和机器学习等技术,帮助用户快速创建出符合自己特点和需求的简历。