语音、视频转文字神器:开源whisper介绍
发布时间:2024年06月06日
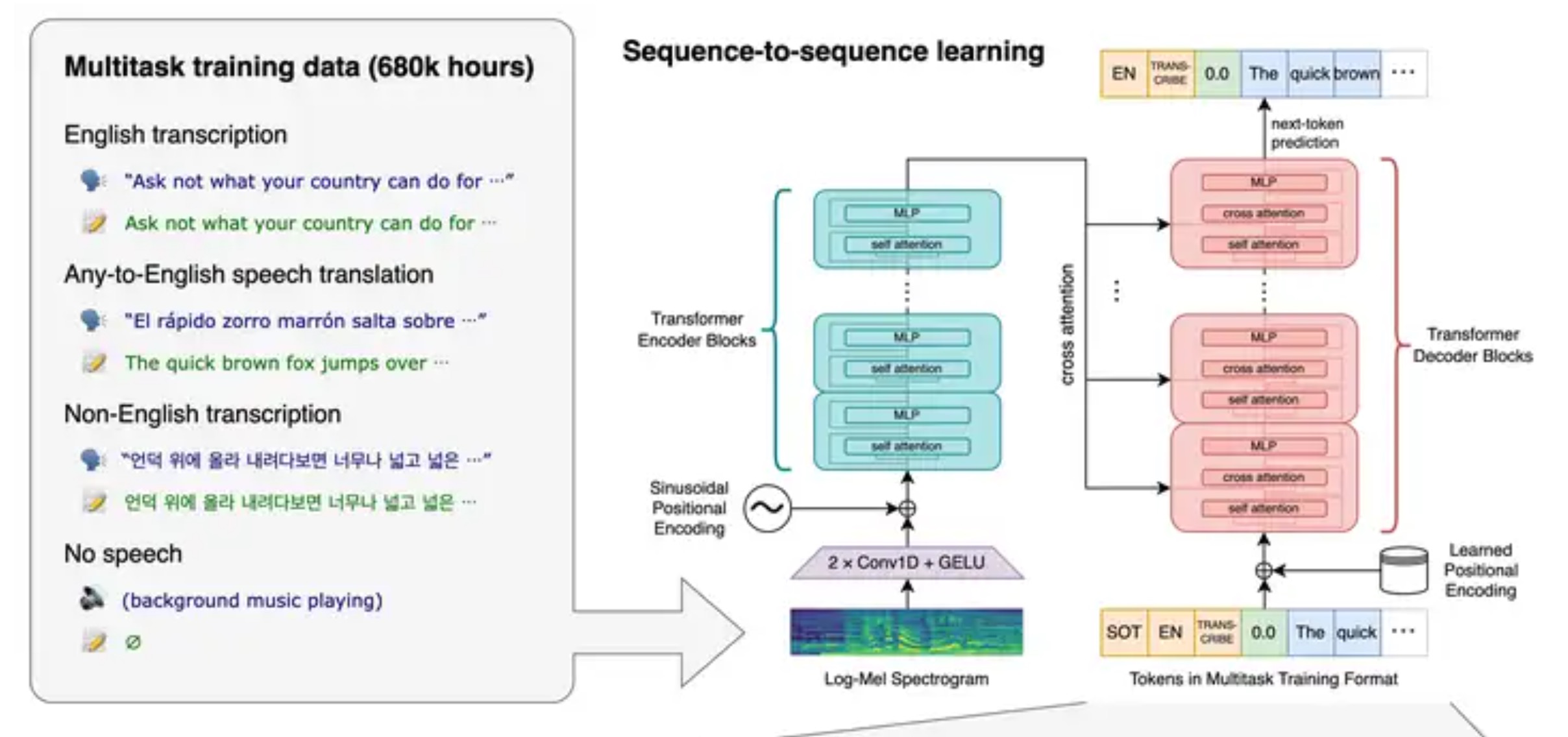
OpenAI的Whisper是一种基于深度学习的语音识别模型,它是一种通用的语音识别模型,可以用于语音识别、语音翻译和语言识别等任务。
Whisper是通过收集来自多个数据源(如YouTube、TED、Twitter等)的多语言、多任务的数据进行训练的。这些数据包含了各种语言和口音的语音样本,以及各种不同的环境噪声和干扰。
Whisper模型使用了一种称为“自注意力机制”的技术,它可以在处理不同的语音信号时,更好地捕捉到语音中的关键信息。此外,Whisper还使用了一种称为“注意力机制”的技术,它可以在处理不同的语音信号时,更好地捕捉到语音中的关键信息。
Whisper模型的训练过程非常复杂,需要大量的计算资源和时间。但是,一旦训练完成,Whisper模型可以在各种不同的应用场景中提供高质量的语音识别结果。
让我们感受一下开源语音转文字的魅力吧。
安装
使用以下指令:
pip install -U openai-whisper或者使用以下指令从源码安装最新版
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git另外需要安装ffmpeg,不同系统参考不同方式
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg模型说明
有五种模型大小可供选择,其中除了large模型外还提供了只支持英文的版本。模型越小占用显存越少,速度也更快,但精度也更低,所以在使用时需要自己在速度和准确度之间权衡。以下是可用模型的名称、近似内存需求和相对速度。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
英语模型中的.en模型(仅适用于英语应用程序)往往表现更好,特别是对于tiny.en和base.en模型。
Whisper的表现在不同语言下会有很大差异。下图展示了使用large-v2模型对Fleurs数据集进行的WER(词误率)语言拆解。数值越小,表示表现越好。
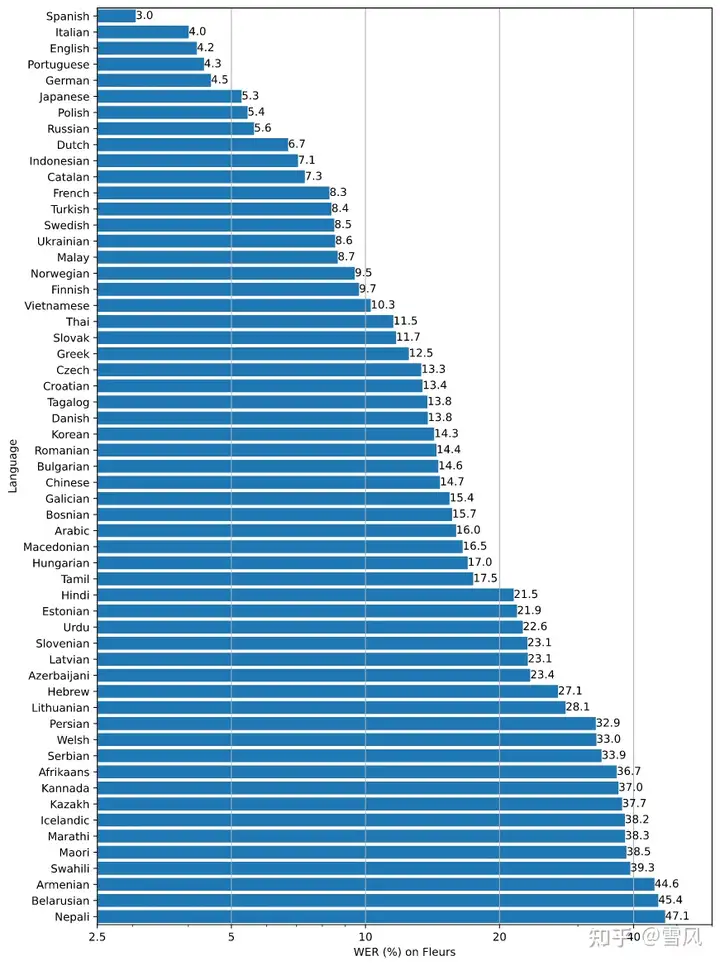
简单的说,目前whisper最擅长的6种语言是西班牙语、意大利语、英语、葡萄牙语、德语和日语。中文的WER达到14.7,处于中等水平,所以表现不是那么好,但可用,后面会测试。
用法
直接使用whisper指令识别音频和视频文件为文本,如:
whisper video.mp4这里需要重点说明的是,默认会生成5个文件,文件名和你的源文件一样,但扩展名分别是:.json、.srt、.tsv、.txt、.vtt。除了普通文本,也可以直接生成电影字幕,还可以调json格式做开发处理。
前面介绍了whisper有多种模型,默认使用的是small模型,占用显存少,识别速度快,但准确率没大模型高,以下--model medium命令将使用medium模型转录音频文件中的语音:
whisper audio.flac audio.mp3 audio.wav --model medium默认设置(选用小型模型)在转录英语时表现良好。如果要转录包含非英语言的音频文件,则可以使用--language选项指定语言,当然也可以不指定语言,模型可以做到自动识别:
whisper japanese.wav --language Japanese添加--task translate选项将把语音翻译成英语,这在需要为非英文电影生成英文字幕的场景非常方便:
whisper chinese.mp4 --language Chinese --task translate运行以下命令查看所有可用选项:
whisper --help除了使用whisper指令,也可以使用python开发使用,这很方便,但这里不多做介绍,以下是Python示例:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
商汤日日新垂直领域场景落地应用丰富。