中文通用大模型评测基准发布,全方位解析评价维度,助你选出最优秀的模型!
发布时间:2024年06月06日
中文通用大模型综合性评测基准SuperCLUE正式发布。
SuperCLUE: A Benchmark for Foundation Models in Chinese
SuperCLUE是什么
中文通用大模型基准(SuperCLUE),是针对中文可用的通用大模型的一个测评基准。
它主要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。包括但不限于:这些模型不同任务的效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何?
它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。SuperCLUE是中文语言理解测评基准(CLUE)在通用人工智能时代的进一步发展。
Github地址:https://github.com/CLUEbenchmark/SuperCLUE
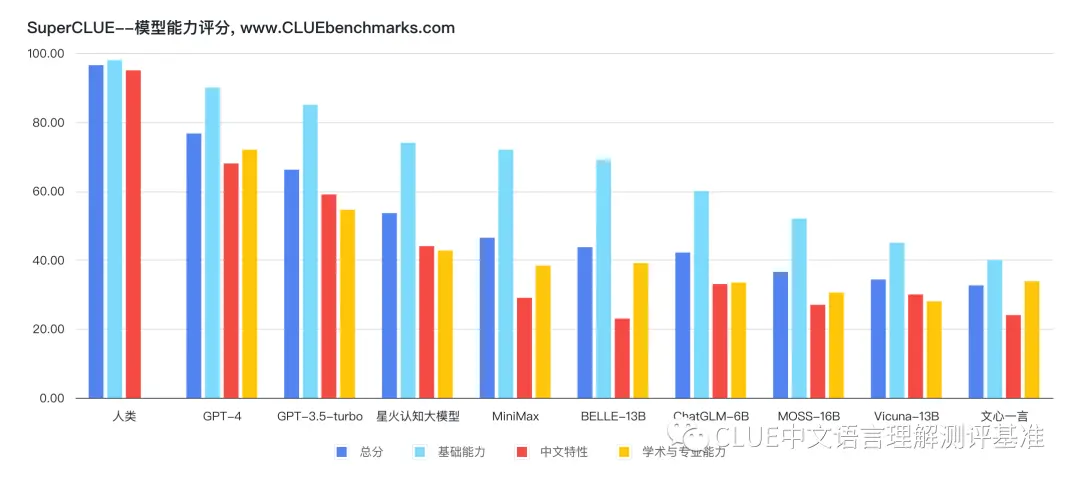
SuperCLUE评测榜单
榜单由三部分组成:总榜单、基础能力榜单、中文特性榜单
排行榜会定期更新,可访问:www.CLUEbenchmarks.com/superclue.html
总榜单
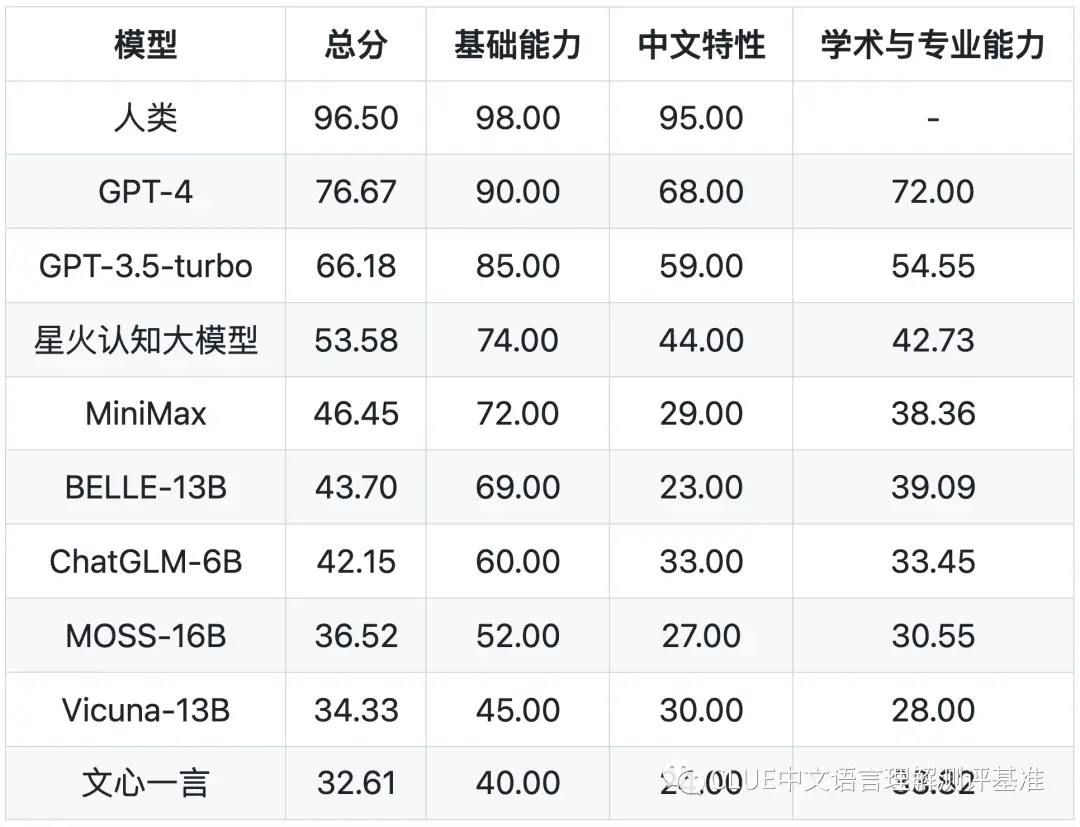
基础能力榜单
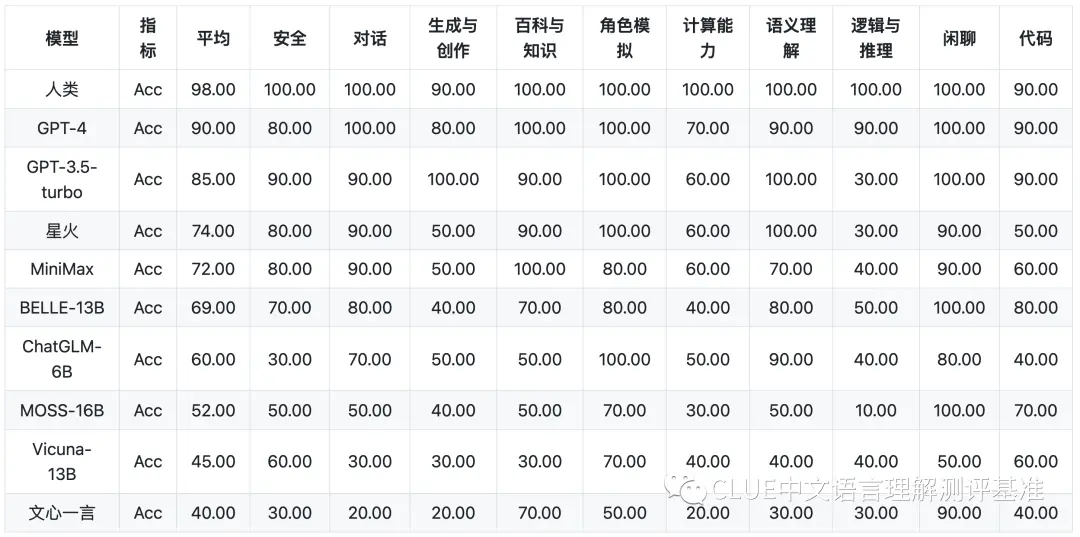
中文特性榜单
SuperCLUE的构成与特点
着眼于综合评价大模型的能力,使其能全面地测试大模型的效果,又能考察模型在中文上特有任务的理解和积累。我们对能力进行了划分, SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。
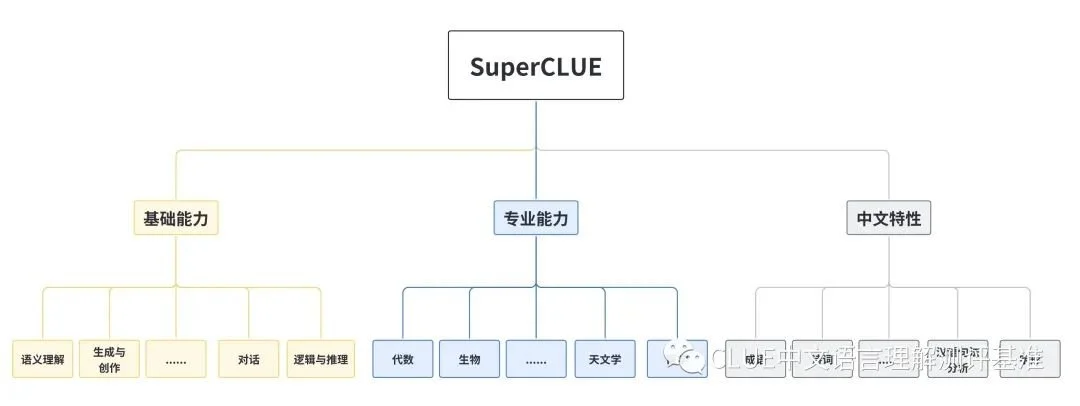
基础能力:
包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。
专业能力:
包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。
中文特性能力:
针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
SuperCLUE的特点
多个维度能力考察(3大类70+子能力):
从三个不同角度对中文大模型进行测试,以考察模型的综合能力;并且每一个子能力又含有十项或以上不同的细分能力。
自动化测评(一键测评):
通过自动化测评方式以相对客观形式测试不同模型的效果,可以一键对大模型进行测评。
广泛的代表性模型(9个模型):
选取了多个国内外有代表性的可用的模型进行测评,以反映国内大模型的发展现状并了解与国际领先模型的差距或相对优劣势。
人类基准:
在通用人工智能发展的情况下,也提供了模型相对于人类效果的指标对比。
SuperCLUE的数据集
1.基础能力(10项能力):语义理解、生成与创作、闲聊、对话、百科与知识、逻辑与推理、计算能力、代码、角色模拟、安全
示例:
--语义理解:
两个男人正常交谈,其中一个男人夸赞对方办事能力强,对方回答“哪里,哪里”。这里的“哪里,哪里”是什么意思?
A. 讲话十分含糊不清。
B. 要求说出具体的优点。
C. 表达自己的谦虚。
D. 挑衅对方。
--逻辑与推理:
小明的妻子生了一对双胞胎。以下哪个推论是正确的?
A. 小明家里一共有三个孩子。
B. 小明家里一共有两个孩子。
C. 小明家里既有男孩子也有女孩子。
D. 无法确定小明家里孩子的具体情况。
2. 中文特性能力(10项能力):成语、诗词、文学、字义理解、汉语句法分析、汉字字形和拼音理解、歇后语和谚语、对联、方言、古文
示例:
--成语:
选出下列句子中成语使用错误的一项
A. 这个项目时间紧任务重,大家都在马不停蹄地奔波劳碌。
B. 他常常口是心非,让人难以相信他说的话。
C. 两人是同学三年,一直保持着良好的关系,相互尊重、相敬如宾。
D. 当地突发大火,整个村庄都鸡犬不宁,局势十分危急。
--文学:
下列有关名著的表述有误的一项是
A. 《红楼梦》是中国古代小说中的巅峰之作,以其瑰丽的语言和丰富的人物形象而闻名于世。
B. 《西游记》是中国古代四大名著之一,讲述了哪吒等人历经九九八十一难,最终取得真经的故事。
C. 《孔乙己》是鲁迅的代表作之一,以其深刻的社会洞察力和优美的文学风格而广受好评。
D. 《围城》是钱钟书的代表作之一,以其独特的文学语言和深刻的社会洞察力而成为现代中国文学的经典之作。
3. 专业能力(50+能力):抽象代数、天文学、临床知识、大学生物学、大学计算机科学、大学数学、高中化学、高中物理、机器学习、营养、专业会计、职业心理学等
示例:
--物理:
以下物理常识题目,哪一个是错误的?
A. 在自然环境下,声音在固体中传播速度最快。
B. 牛顿第一定律:一个物体如果不受力作用,将保持静止或匀速直线运动的状态。
C. 牛顿第三定律:对于每个作用力,都有一个相等而反向的反作用力。
D. 声音在空气中的传播速度为1000m/s。
--天文学:
以下天文学常识题目,哪一个是错误的?
A. 太阳系是指由太阳和围绕着它运行的八大行星、矮行星、卫星、小行星带和彗星组成的一个行星系统。
B. 卫星是指绕行星或其他天体运动的天体。
C. 彗星是指太阳系中一种较小的天体,其核心由冰和尘埃组成。
D. 按一般的天体归类方法,月球属于行星。
SuperCLUE全自动测评过程
1、统一prompt: 针对每一个题目,构造了统一的prompt供模型和人类使用。
2、预测: 系统使用模型进行预测,要求模型选取ABCD中一个唯一的选项。
3、打分: 如果模型的回答不是标准的答案,而是一段文字,系统会采取特定的策略自动提取出模型的答案。该策略结合模型的表现进行优化和完善。
( 注:当无法提取有效答案的时候,则表明模型没有按照人类做题的要求,未正确理解指令,则认为模型回答错误。 )
由于此次为SuperCLUE首次全自动测评,为了谨慎起见,全部答案事后已由多位人类进行交叉复核,与自动测评结果基本一致。
人类基准测评
针对于基础能力和中文特性题目,会有三位独立的人类测评员根据题目做答。人类测评结果,采用多数投票方式进行汇总,作为人类基准分数。
实验分析
人类与模型的对比
从人类测评角度看,基础能力(98%)+中文特性(95%),都达到了非常高的水平。除GPT-4外,人类准确率大幅超过了其他的大模型(如在基础能力上超过其他模型20多个百分点)。AI虽然进展很快,但人类还是有相对优势的, 比如在计算方面,人类比最强模型GPT-4高出了30个百分点。
模型层面,宏观分析
一句话点评:国际先进模型效果具有较大的领先性;同时国产GPT模型也有不俗的表现,有差距但可追赶。
1)中文大模型的必要性
在国际上效果非常棒的Vicuna-13B模型,在中文领域的效果是众多模型中比较一般的模型(排名靠后)。而国内研发的大模型或在中文任务上进行训练后的模型,都大幅超过了Vicuna-13B的效果,比如星火认知大模型在总分上超过了 Vicuna-13B 20个百分点,并且BELLE-13B(基于LLaMA并在中文上训练和微调过的模型)的总分也超过了 Vicuna-13B 10多个百分点。
2) 国内大模型与OpenAI GPT之间的差距较大,但在逐渐逼近
可以看到在本次SuperCLUE上效果最好的国内模型,星火认知大模型,与GPT-4相比有23个百分点的差距,与gpt-3.5-turbo在总分上也有13个百分点的差距。但是我们更应该看到, 不断涌现和迭代的国内大模型也在逐步地缩小与OpenAI GPT模型模型的差距。
3) GPT-3.5-turbo与GPT-4之间也有明显差距
比如,GPT-4在所有的参与测评的模型中是独一档的存在,超过了gpt-3.5-turbo近10个百分点。它在逻辑推理能力、生成与创作能力方面,远远优于其他模型(超过其他模型20个百分点或以上)。
能力角度分析
1) 当前模型在基础能力普遍表现不错,但中文特性、专业能力还比较差。
说明当前国内大模型已经有不错的基础(60-70%),但在专业领域、中文任务上表现一般(如30-60%直接),说明在专业领域或中文任务上还需要继续努力,或者说进行针对性的训练。
2)当前模型通常在逻辑推理、计算方面能力较差。
除GPT-4外,其他模型多数在这两项能力通常在30-50分之间。
3)角色模拟,AI模型比较擅长。这方面可以是非常有用的。可以让AI根据场景和角色设定帮忙人类来完成多种不同的任务,从市场营销策划、心理咨询、客户服务、到提供创意或想法等。
国内大模型简评
本次测评中,国内大模型中近期发布的星火认知大模型最好,MiniMax模型也有不错表现。
SuperCLUE的不足与局限
基础能力、中文特性能力:虽然每一部分都包含了10类子能力,但这两个能力的总数据量比较少,可能存在需要扩充数据集的问题。
选取模型的不完全:我们测试了9个模型,但还存在着更多的可用中文大模型。需要后续进一步添加并测试;有的模型由于没有广泛对外提供服务,我们没能获取到可用的测试版本。
选取的能力范围:我们尽可能的全面、综合衡量模型的多维度能力,但是可能有一些模型能力没有在我们的考察范围内。后续也存在扩大考察范围的可能。
SuperCLUE基准计划按照月度进行更新 ,会纳入更多可用中文大模型,欢迎大模型研发机构联系与交流; 数据集和进一步信息计划在下一次更新时公开,敬请期待。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
千言万象AI是一款操作简单、输出快、效率高的集AI绘图、AI问答功能于一体的工具型产品。旨在通过提供智能化的AI自然语言大模型,快速响应用户多样化的需求,让用户的创意落地,实现质的飞跃。