开源免费离线语音识别神器whisper如何安装
发布时间:2024年06月06日
whisper介绍
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供的自动语音辨识(Automatic Speech Recognition,ASR)模型是被训练来运行语音辨识与翻译任务的,它们能将各种语言的语音变成文本,也能将这些文本翻译成英文。
whisper的日常用途
whisper的核心功能语音识别,对于学生党和工作党来说,可以帮助我们更快捷的将会议、讲座、课堂录音整理成文字稿;对于影视爱好者,可以将无字幕的资源自动生成字幕,不用再苦苦等待各大字幕组的字幕资源;对于外语口语学习者,使用whisper翻译你的发音练习录音,可以很好的检验你的口语发音水平。
当然,我们知道一些商业公司提供语音识别服务,但是基本都是联网运行,个人隐私安全总是有隐患,而whisper完全不同,whisper完全在本地运行,无需联网,充分保障了个人隐私,且whisper识别准确率相当高。拿我自己录的一段音频举例,5min长度400多字,使用whisper的medium模式识别,只错了两个英文单词,那两个英文单词还是因为发音问题识别错误。
本文目的
网络上有些教程只展示了whisper使用的效果,没有介绍怎么安装,为避免大家在安装上踩坑,同时也为了避免自己以后万一哪天电脑崩溃需要重装whisper的时候再踩坑,我在这里记录下安装方法。
系统环境
官方说他们使用的是Python 3.9.9 and PyTorch 1.10.1来训练和检验的程序,但预计兼容python 3.7以后的版本和pytorch近期更新版本。 大家在安装whisper的时候请尽量保证python版本与官方一致或更新版本,或者至少是3.7版本以后,这样可以避免一些版本不同导致的莫名奇妙的错误。 本文测试系统为windows11 64位、python版本3.9.13和windows10 64位、python3.7.5版本.
安装步骤
whisper的安装不是简简单单一句命令
pip install whisper
就完事,它还需要一些依赖。比如ffmpeg、pytorch等。本文没涉及python的安装,默认读者是已经安装好python的,如果你不会安装python的话,建议去视频平台搜索安装教程,安装好后再来进行下面的步骤。
步骤1.下载ffmpeg并添加环境变量
首先我们下载ffmpeg.exe。下载地址是
找到“ffmpeg-master-latest-win64-gpl.zip”版本下载。
解压后,找到bin文件夹下的“ffmpeg.exe”,将它复制到一个文件夹中,假设这个文件夹的路径是"D:\software\ffmpeg",如下图
然后将"D:/software/ffmpeg"添加到系统环境变量。
添加方法:
键盘win+r,调出运行窗口
输入Sysdm.cpl后,点击确定。弹出系统属性窗口,先后点击高级、环境变量。
弹出新窗口后,双击Path
在空白行添加刚刚ffmpeg.exe所在的路径,点击确定。
至此,ffmpeg设置完成。
步骤2.下载git并添加环境变量
官方网站下载git安装包,安装过程中的选项全都默认,一直点next到安装完成。 打开命令行窗口,输入git,回车,如果命令成功运行,如下图所示,则git的安装到此结束,可以进行下一步pytorch的安装。
如果在命令行输入git并回车后,命令没有成功运行,返回的结果如下:
“git”不是内部或外部命令,也不是可运行的程序或批处理文件则需要将git添加到环境变量中。
具体操作步骤如下:
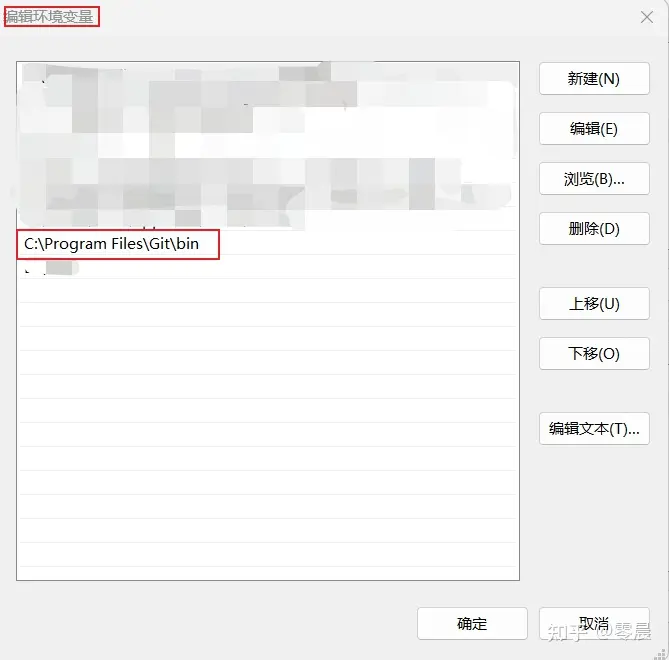
使用“everything”搜索git.exe,找到它位于我电脑上的路径是“C:\Program Files\Git\bin”,如下图。
将其添加到环境变量,如下图。
步骤3.pytorch的安装
这里我们使用pip安装。
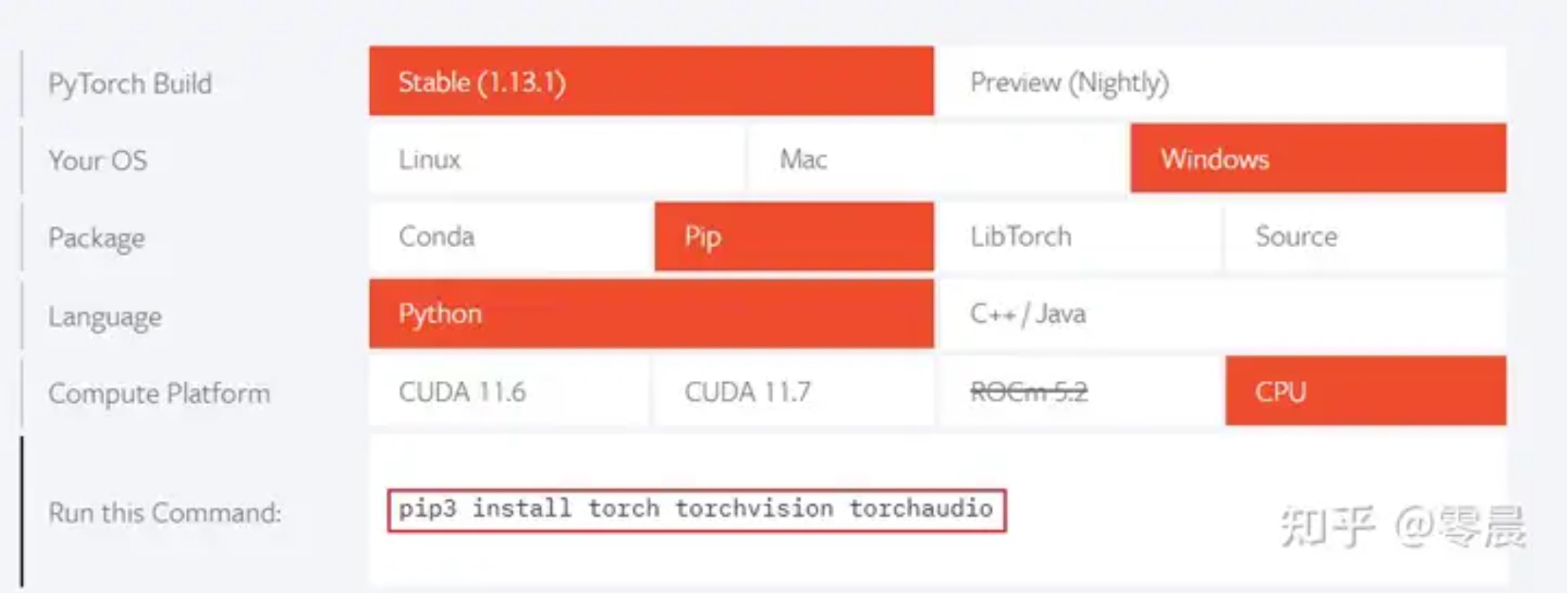
打开pytorch.org,下拉页面。
按照下图选择要安装的版本。我选择的是稳定版,windows系统,pip安装方式,python语言、cpu版本的软件。
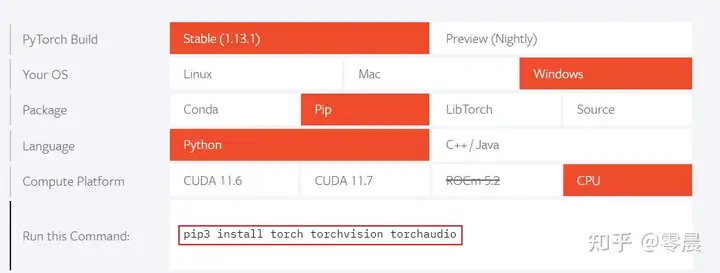
选择好后上图中框选的那行代码就是使用pip安装pytorch的命令。 在命令行界面运行
pip3 install torch torchvision torchaudio
安装pytorch,安装好后这一步也就完成了。
补充说明: 上图中CUDA 11.6和CUDA 11.7都是gpu版本的软件,我一开始下载的也是gpu版本的,但是因为我的电脑显卡的显存比较低,运行whisper模型的时候大模型运行不了。下图是whisper官方给出的运行模型所需显存。
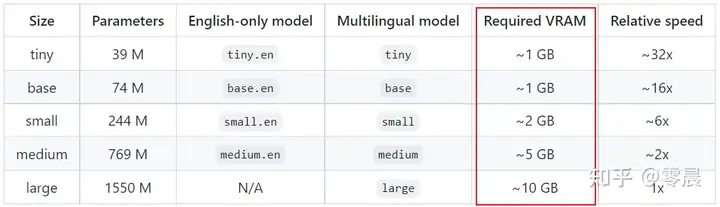
我的显存是4GB,一旦使用whisper运行small模式以上的模型就会报显存不足的错误。为了能运行更大的模型以保证语音识别较高的准确率,我最终只能选择安装cpu版本。
步骤4.whisper的安装
以上步骤都完成后。 按照官方文档,先运行
pip install git+https://github.com/openai/whisper.git
然后再运行
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
完成whisper的安装。
whisper的简单使用
最基本的语音识别
我们准备一段音频,使用whisper将其转换成文字。 以此音频为例:
在音频所在文件夹中右键打开cmd窗口。 (如果是win10的话就在文件夹的空白处按住shift,然后鼠标右键单击,打开powershell窗口)
输入whisper audio.mp3,回车运行。
在命令行窗口中显示的是转写结果,同时在当前文件夹下生成三个字幕文件。以下是三种格式的对比。
更换转写模型
以上whisper audio.mp3的命令形式是最简单的一种,它默认使用的是small模式的模型转写,我们还可以使用更高等级的模型来提高正确率。 比如
whisper audio.mp3 --model medium
上图是使用small模型和medium模型的对比,medium模型耗费时间更长,但也更精准。一般而言,综合权衡速度与精准度,选择small也够用了,如果你对语言识别的精准度高可以使用medium,medium的精准度已经相当高了,如我文章开头所说,我用medium模式识别了我读的一段5min的音频,400多字。正确率基本百分百,只错了2个英文单词,还是因为我发音不准,尴尬。
当然还有其他的模型可供选择,可以在命令行运行whisper --help查看帮助。 有以下11种模式可供选择。
[--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}]
结语
本文简单介绍了whisper的用途、在windows系统下安装部署whisper的方法以及whisper的简单用法。
关于whisper的使用部分仅介绍了命令行模式的使用方法,如果你会使用python,也可以使用以下代码来运行whisper。
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
了解更多请参考官方文档。
或者如果你想要在网页上运行whisper,可以安装Whisper Webui。 可以参考:
觉得本文有帮助的小伙伴,点个赞再走呗~
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
开源的使用JVM部署和训练深度学习模型的套件