ViTPose+:迈向通用身体姿态估计的视觉Transformer基础模型
发布时间:2024年07月12日
身体姿态估计旨在识别出给定图像中人或者动物实例身体的关键点,除了典型的身体骨骼关键点,还可以包括手、脚、脸部等关键点,是计算机视觉领域的基本任务之一。目前,视觉transformer已经在识别、检测、分割等多个视觉任务上展现出来很好的性能。在身体姿态估计任务上,使用CNN提取的特征,结合定制化的transformer模块进行特征增强,视觉transformer取得了很好的效果。然而,简单的视觉transformer本身在姿态估计任务上是否能有很好的表现呢?
京东探索研究院联合悉尼大学在这方面做出了探索,提出了基于简单视觉transformer的姿态估计模型ViTPose和改进版本ViTPose+。ViTPose系列模型在MS COCO多个人体姿态估计数据集上达到了新的SOTA和帕累托前沿。其中,ViTPose已收录于Neurips 2022。ViTPose+进一步拓展到多种不同类型的身体姿态估计任务,涵盖动物、人体以及典型的身体骨骼、手、脚、脸部等关键点类型,在不增加推理阶段模型复杂度和计算复杂度的情况下,实现了多个数据集上的最佳性能。
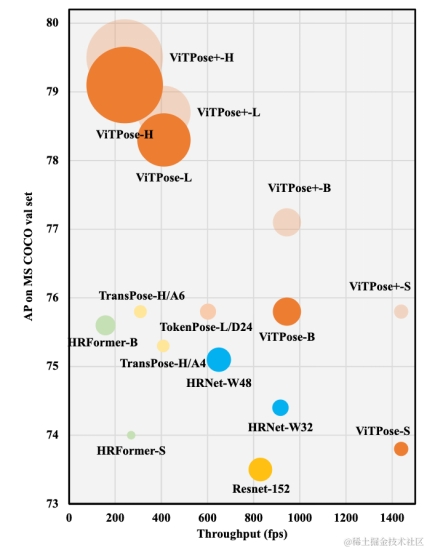
ViTPose和ViTPose+的性能和速度对比图,圆圈大小代表了模型大小
近年来,视觉transformer在多个视觉领域展现出了极佳的性能。在姿态估计领域,也涌现出许多基于transformer的方案,并取得了很好的效果。如TokenPose等工作,使用CNN进行特征提取,并使用transformer作为后处理模块来建模多个关键点之间的关系。尽管他们展现了很好的效果,但是仍然依赖CNN提取特征,很难充分挖掘transformer在姿态估计领域的潜力。
为了减少CNN的影响,HRFormer等工作仅使用transformer来进行特征提取和建模人体关键点。为了提升模型性能,模型采用了一些特殊的设计,如多尺度建模、多层级结构等方式。这些结构在CNN模型设计和transformer模型设计中都表现出很好的结果。然而,我们是否需要为姿态估计任务定制化的设计Transformer网络结构呢?为此,京东探索研究院联合悉尼大学提出了基于简单视觉transformer的姿态估计基线ViTPose,充分挖掘transformer在姿态估计领域的潜力。基于常见的无监督预训练技术并结合非常简单的解码器,ViTPose展示了视觉transformer在姿态估计方面的简单性,可扩展性,灵活性,和可迁移性,并在人体,动物,全身关键点检测等方面达到SOTA性能。
二、ViTPose方法
2.1 ViTPose结构简介
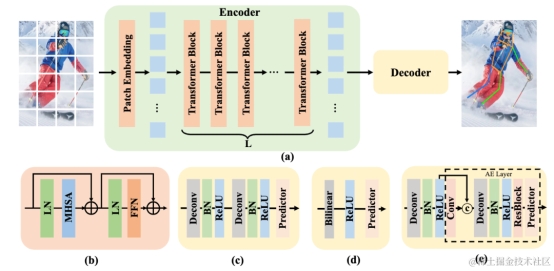
图1 ViTPose结构
为了尽可能避免复杂的设计,ViTPose采用了最简单的方式来应用简单的视觉transformer。具体来说,ViTPose使用了简单的视觉transformer作为编码器对输入图像进行特征提取。提取得到的特征会作为解码器的输入来得到最终的关键点预测。带有transposed卷积上采样和预测层的标准解码器(c)和直接使用双线性插值的简单解码器(d)被用于评估简单视觉transformer的简单性;用于Bottom-up预测的解码器(e)也被采用来衡量ViTPose对于不同关键点检测范式的灵活性。
此外,得益于采用了最简单的编码器-解码器设计,ViTPose可以很容易的兼容更大规模的简单视觉transformer模型,并得到性能提升,展示出良好的扩展性;此外,通过使用不同的预训练方式,和不同大小模型的迁移,ViTPose展现出优秀的灵活性和可迁移性。尽管没有复杂的模型设计,ViTPose在人体,动物,全身关键点估计等多个设置下达到或超过了SOTA的模型,充分展示了简单视觉transformer在姿态估计领域的潜力。
2.2 简单性和扩展性

表1 使用不同decoder的ViTPose在MS COCO的性能对比
为了验证ViTPose的简单性和可扩展性,研究者使用了不同的解码器和不同尺寸的编码器,结果如表1所示。相比于使用经典的反卷积解码器,使用简单双线性解码器的CNN模型出现了极大的性能下降,如ResNet-50和ResNet-152有接近20平均准确度的下降。然而,视觉transformer模型则表现出了很强的竞争力:使用简单的解码器和经典解码器的性能差距不到0.3平均准确度,充分说明由于视觉transformer的强表征能力,它可以学习到线性可分性极强的特征表示,从而仅需要简单的线性解码器即可以达到很好的效果。此外,使用更大规模的编码器,ViTPose的性能持续上升,展示了ViTPose良好的扩展性。
2.3 ViTPose的数据灵活性

同预训练数据的ViTPose在MS COCO的性能对比
在过往的实验中,使用ImageNet对编码器进行预训练已经成为了一种默认设置。然而,对于姿态估计任务来说,这引入了额外的数据需求。为了探索使用ImageNet数据进行预训练是否是不可避免的,ViTPose探索了能否只使用姿态估计数据 (MS COCO和AI Challenger数据)进行预训练。结果如表2所示,无论是否使用人体的位置(人体实例的检测框标注)进行裁剪操作,只使用姿态估计的数据进行预训练的ViTPose在使用更少的数据量的情况下达到了和使用ImageNet数据进行预训练的ViTPose相当的效果。
2.4 ViTPose的结构灵活性
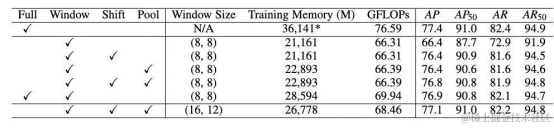
表3 使用不同注意力方式的ViTPose性能
由于使用全注意力方式的计算复杂度,在使用大尺寸特征图进行训练时,ViTPose模型的显存消耗会大幅度增长。为此,ViTPose也探索了能否在微调阶段使用不同的注意力方式进行计算。如表3所示,使用窗口注意力机制的ViTPose在占用更少显存消耗的情况下可以达到和使用全注意力机制的ViTPose相当的效果。
2.5 ViTPose的训练灵活性
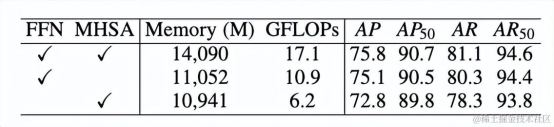
表4 使用不同模块进行训练的ViTPose性能
为了充分探索ViTPose中各个模块对于姿态估计任务的贡献,ViTPose进一步探索了仅使用FFN模块或者MHSA模块进行训练而保持其他模块不动的训练方式。结果如表4所示。仅调整FFN模块可以达到和全部可训练相当的效果,而只训练MHSA模块则会带来较大的性能下降,说明FFN模块负责更多特定任务相关的建模,在下游任务迁移学习中发挥更大作用。
2.6 ViTPose+使用MoE机制扩展多数据集
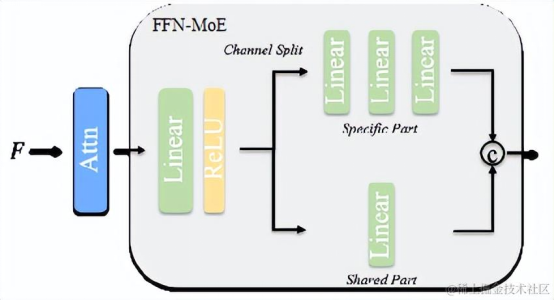
图2 ViTPose+中的FFN-MoE结构
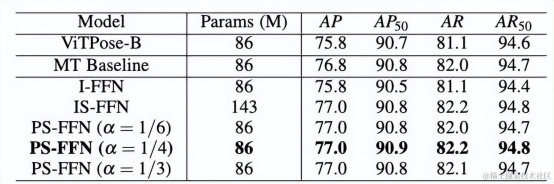
表5 ViTPose+性能比较
然而,不同的姿态估计数据集有不同的分布,简单通过单一模型来建模不同的姿态估计数据集会因为数据集之间的冲突造成各个数据集上的性能下降。例如,使用动物数据集和人体数据集进行联合训练会影响人体姿态估计性能(如表5中I-FFN所示)。为解决这一问题,ViTPose+模型探索了使用MoE机制来解决数据集冲突的问题,如图2所示,经过注意力机制处理后的特征会分块输入FFN模块中进行处理。经过自己数据集独有的部分和各个数据集共享的部分处理后的FFN模块会拼接起来输入到之后的模块中。如表5所示,这一机制超过了多任务学习的基线方法(MT Baseline),并与使用独立和共享FFN模块(IS-FFN)取得了相当的效果,但节省了更多的参数量。
三、实验结果
3.1 客观结果
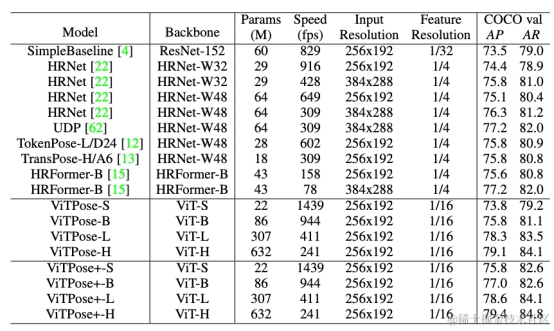
表6 在MS COCO数据集上不同模型采用Top-down检测范式的性能
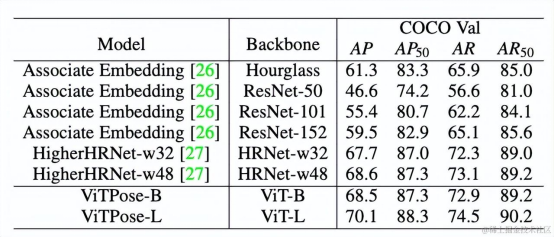
表7 在MS COCO数据集上不同模型采用Bottom-up检测范式的性能
如表6和表7所示,ViTPose在top-down和bottom-up两种检测方式下达到了和之前模型相当或者更好的效果。使用更多数据集联合训练的ViTPose+系列模型达到了更好的速度和性能的平衡,如ViTPose±S模型在22M的参数量下达到了1439fps的速度和75.8 AP的准确度。这展示了使用简单视觉transformer在姿态估计任务上的潜力和可能性。
3.2 主观结果

图3 MS COCO主观结果展示

图4 AI Challenger主观结果展示

图5 OCHuman主观结果展示

图6 MPII主观结果展示

图7 WholeBody主观结果展示

图8 动物主观结果展示
如图3-8所示,ViTPose+在多个姿态估计数据集和多种姿态估计任务上均可以得到优异的结果,较好的应对遮挡、截断等多种富有挑战性的场景。这充分展现了简单的视觉transformer作为姿态估计基础模型的潜力。
四、结论
本文提出了ViTPose,通过使用简单的视觉transformer进行特征提取和简单的解码器的方式,在姿态估计任务上展现了简单视觉transformer的简单性,可扩展性,灵活性和可迁移性。通过使用MoE的机制解决数据集之间的冲突,ViTPose+系列模型在多个姿态估计数据集上刷新了之前方法的最好结果,达到了新的SOTA和帕累托前沿。我们希望这个工作可以启发更多基于简单视觉transformer的工作来探索简单视觉transformer在更多视觉任务上的可能性,并建立统一多个姿态估计任务的视觉基础模型。
【文章】ViTPose:https://arxiv.org/abs/2204.12484或https://openreview.net/pdf?id=6H2pBoPtm0s
ViTPose+:https://arxiv.org/abs/2212.04246
【代码】https://github.com/ViTAE-Transformer/ViTPose
参考文献:
[1] Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. “ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation.” Neurips 2022.
[2] Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. “ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation.” arXiv preprint arXiv:2212.04246 (2022). [3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep residual learning for image recognition.” CVPR 2016.
[4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. “Imagenet: A large-scale hierarchical image database.” CVPR 2009.
[5] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. “Microsoft coco: Common objects in context.” ECCV 2014.
[6] Yuhui Yuan, Rao Fu, Lang Huang, Weihong Lin, Chao Zhang, Xilin Chen, and Jingdong Wang. “Hrformer: High-resolution vision transformer for dense predict.” Neurips 2021.
[7] Yanjie Li, Shoukui Zhang, Zhicheng Wang, Sen Yang, Wankou Yang, Shu-Tao Xia, and Erjin Zhou. “Tokenpose: Learning keypoint tokens for human pose estimation.” ICCV 2021.
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/JDDTechTalk/article/details/132734847
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Blackink AI纹身助手是一个基于人工智能技术的AI纹身设计助手,可以帮助用户生成高质量的纹身效果。