数字人之声音克隆:无样本,1分钟样本完美克隆声音,开源
发布时间:2024年07月20日
最近在搞克隆人,发现一个很好的声音克隆项目,测试了一下,效果真不错,可以直接用,也可以微调后使用,好了废话不多说,直接上干活,哈哈~~
首先这次直接说项目:GPT-SoVITS
项目功能介绍:
1.
零样本文本到语音(TTS):输入 5 秒的声音样本,即刻体验文本到语音转换。
2.
少样本 TTS:仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
3.
跨语言支持:支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
4.
WebUI 工具:集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型
项目环境要求:
·
Python 3.9、PyTorch 2.0.1 和
CUDA 11
·
Python 3.10.13, PyTorch
2.1.2 和 CUDA 12.3
·
Python 3.9、Pytorch 2.3.0.dev20240122 和 macOS 14.3(Apple 芯片)
注意:
numba==0.56.4 需要 python<3.11
最让我欣喜的是 windows 有一键包,文末我给大家准备好了,不需要你去爬梯子下载了
注意一点下载并将ffmpeg.exe和ffprobe.exe放置在 GPT-SoVITS 根目录下。
声音克隆训练过程
这里针对win cuda 介绍,下载我给你的一键包后点击go-webui.bat,直接启动
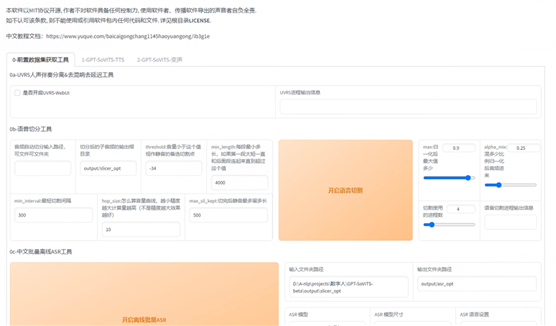
启动后界面如下:
首先从数据开始:
如果你想克隆一个人的声音,你可以找到一段这个人的演讲录音,或者视频,当然不同资源需要不同的处理
如果是视频,可以使用 人声分离,如下图,点击这个就会弹出
弹出如下界面,可以对你的视频提取人声
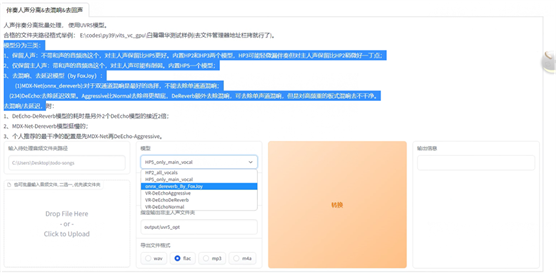
这个提取部分,作者集成了好几个模型,都可以根据需求选择,简单说一下
·
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,
我是找了一段互联网大佬的演讲声音,这里就不需要人声分离了,哈哈~
回到主界面,直接进行声音切割
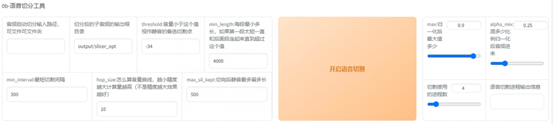
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。
接下来是,语音转文字,使用ASR,这个地方 ASR模型,你可以选中文或者多语种,多语种用的Faster Whisper,这个作者没有集成,使用时会自动下载
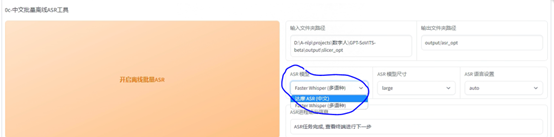
输入上一步切割的语音,直接点击启动,然后静待一会
作者还给了语音文本校对标注工具如果转换的不对,可以人工校对

选择打开后自动弹出界面,很简单这里步赘述了,哈哈~
接下来是数据格式化和微调了
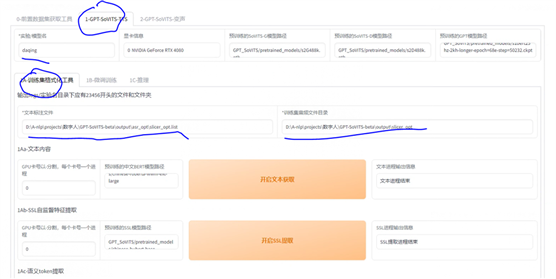
如上图,在TTS卡下,给这次训练一个名字,不要中文,不要中文,不要中文,重要的事情说三遍,训练格式化,需要输入,转换的文本和音频数据
然后进行三项处理

接下来开始微调训练

注意需要根据你的卡的大小,选择 bs和epoch,然后开启SoVITS训练,我们只克隆语音,所以没有训练GPT
训练完后,模型会保存在GPT-SoVITS-beta\logs\下,有两个模型,G和D,
测试效果
训练完当然要测试一下,哈哈~
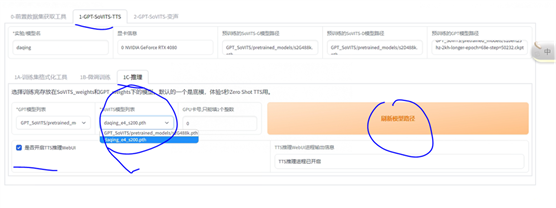
训练完后,在上图这个地方,点击【刷新模型路径】,模型列表中就会有你的新模型了,然后勾选 【是否开启TTS推理webui】,会自动弹出使用界面
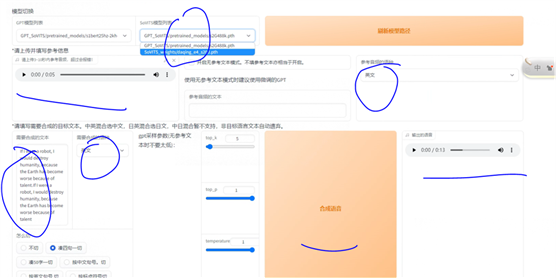
然后上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,语种也要对应。
然后上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,语种也要对应。
效果
原声音:
克隆人,世界大模型,5秒
默认模型效果:
训练前,世界大模型,13秒
训练后效果:
训练后,世界大模型,5秒
对比效果还是有一定提升的,主要是我训练轮数也不高,大家可以自己试试,哈哈,~ 效果出乎意料,中英文都可以幺~git地址:
https://github.com/RVC-Boss/GPT-SoVITS/tree/main
出自:https://mp.weixin.qq.com/s/NXqLAwcinXg6aqueaiuk1g
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
基于AI的文章改写润色工具,它可以重写文章、改写句子和解释文本。您可以使用Paraphraser.io通过先进的 AI 技术来解释您的句子、段落、文章,甚至是长博客。