Ollama最新更新v0.1.33,实现了多并发可同时与多个模型聊天对话!
发布时间:2024年07月30日
Hello,大家好!上周,Ollama进行了v0.1.33版本更新,为本地部署的开源大型语言模型(LLMs)带来了重大改进。现在,多用户可以在同一台宿主机上与LLMs进行互动,实现同时聊天对话。这一更新对于企业或团队用户是一个非常好的消息,它提高了本地协作效率还优化了用户体验。
新版本更新如下
增加了多个新的LLM型号:
·
Llama 3:由Meta推出的新模型,迄今为止最强大的公开可用的大型语言模型(LLM)。
·
Phi 3 Mini:由微软推出的新型3.8B参数、轻量级、尖端开放模型。
·
Moondream:专为在边缘设备上高效运行而设计的一款小型视觉语言模型。
·
Llama 3 Gradient 1048K:由Gradient微调的Llama 3模型,支持高达100万个令牌的上下文窗口。
·
Dolphin Llama 3:基于Llama 3的无审查Dolphin模型,由Eric Hartford训练,具备多种指令、对话和编码技能。
·
Qwen 110B:首个超过100B参数大小的Qwen模型,在评估中表现出色。
·
Llama 3 Gradient:对Llama 3的微调,支持高达100万个令牌的上下文窗口。
·
修复内容:
·
修复了模型不会终止导致API挂起的问题。
·
修复了在Apple Silicon Mac上出现的一系列内存溢出错误。
·
修复了运行Mixtral架构模型时出现的内存溢出错误。
·
实验性并发特性:
新的并发特性即将推出到Ollama。
·
OLLAMA_NUM_PARALLEL:为单个模型同时处理多个请求。
·
OLLAMA_MAX_LOADED_MODELS:同时加载多个模型。要启用这些特性,请为ollama
serve设置环境变量。
·
如何设置并发及加载多个模型
Windows11为例(本地电脑)
1. 任务栏中退出ollama;
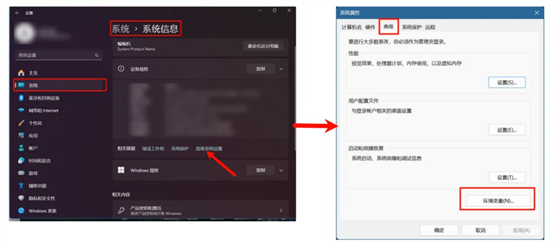
2. 在Windows11搜索栏中搜索设置>系统>系统信息>高级系统设置>环境变量
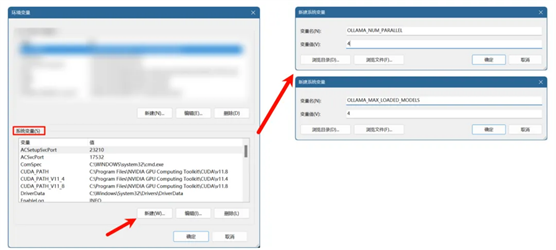
3. 在“系统变量”区域“新建变量“,以下为说明:
·
变量名:OLLAMA_NUM_PARALLEL,变量值:0-4 #并行处理请求的数量
·
变量名:OLLAMA_MAX_LOADED_MODELS,变量值0-4 #同时加载的模型数量
·
变量名:OLLAMA_HOST,变量值:127.0.0.1:11434。这一项是公开本地IP暴露在局域网内,非必要。
·
4. 全部确定后即可启动Ollama。
Linux为例
1.
通过调用 编辑 systemd 服务systemctleditollama.service 这将打开一个编辑器。
2.
Environment对于每个环境变量,在部分下添加一行[Service]:
3.
·
#示例
[Service]
Environment="OLLAMA_HOST=0.0.0.0" #设置服务监听的主机地址
Environment="OLLAMA_NUM_PARALLEL=4" #并行处理请求的数量
Environment="OLLAMA_MAX_LOADED_MODELS=4" #同时加载的模型数量
3. 保存并退出。
4. 重新加载systemd并重新启动 Olama:
·
·
sudo systemctl daemon-reloads
udo systemctl restart ollama
tips:以上的变量值官方给出为4,并没有详细说明最大可以设置到多少。
测试
在多模型运行功能未启用之前,多个用户与单一模型的对话是以队列形式进行的。启用此功能后,对话将能够并行处理,从而显著提升了内网环境下多用户协同与一个或多个模型进行对话的效率。
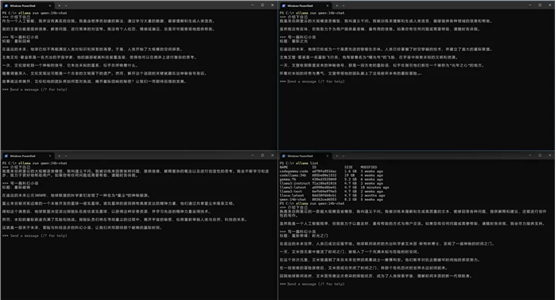
运行一个模型
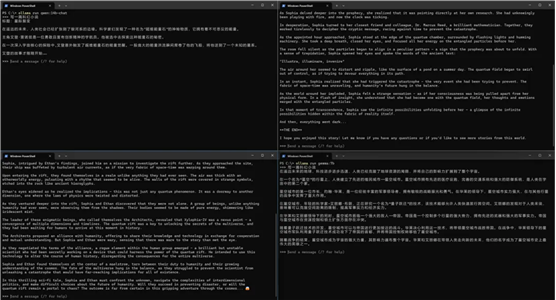
运行多个模型
出自:https://mp.weixin.qq.com/s/ed5wu19XM1pEMtB3rW5I6A
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
WPS智能写作是金山办公推出的一款免费的在线智能写作产品,支持文本自动生成,快速输出大量文章。