9.4k Star!MemGPT:伯克利大学最新开源、将LLM作为操作系统、无限上下文记忆、服务化部署自定义Agent
发布时间:2024年07月30日
MemGPT 允许你使用长期记忆和自定义工具构建 LLM
Agent

最近有个新项目MemGPT,这个东西真的挺有意思,它可以让大型语言模型,比如让GPT-4这样的llm处理比原生更长的上下文窗口,从而提高它们在复杂任务(如多会话对话和详细文档分析)中的性能。
教导llm管理自己的无限上下文内存!
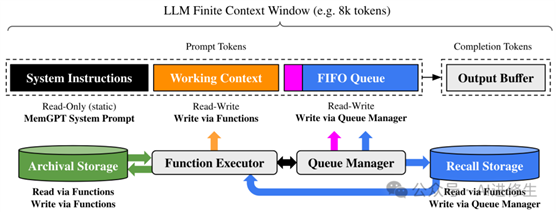
▲在 MemGPT 中,固定上下文 LLM 处理器增强了分层内存系统和功能,使其可以管理自己的内存。LLM 的提示标记(输入)或主上下文由系统指令、工作上下文和 FIFO 队列组成。LLM 完成标记(输出)被函数执行器解释为函数调用。MemGPT 使用函数在主上下文和外部上下文(归档和调用存储数据库)之间移动数据。LLM 可以通过在其输出中生成特殊关键字参数 (
request_heartbeat=true )来请求立即后续 LLM 推理,以将函数调用链接在一起;函数链允许 MemGPT 执行多步骤检索来回答用户查询
o
• llm越来越多地被用于永久聊天
o
•有限的上下文长度使得永久的聊天具有挑战性
o
• MemGPT通过管理一个虚拟上下文(受操作系统中虚拟内存的启发)来创建无限的LLM上下文
o
•通过MemGPT,我们证明了llm可以被教会管理自己的内存!
o
通常像GPT-4这类大模型处理复杂的自然语言任务还行,但是当事情涉及到长期记忆或者需要推理一大堆数据时,它们就有点力不从心了。想想看,如果一个模型只能记住它最近看过的一点点信息,要是信息太多,它就处理不了了。
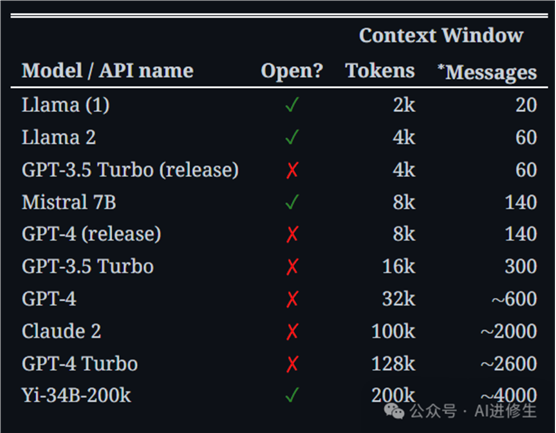
▲比较常用模型和 LLM API 的上下文长度(数据收集于 1/2024)。近似消息计数假设预提示有 1k 个令牌,平均消息大小为50 个代币。“Open”意味着该模型是开源的或开放权重的(而不是仅在 API 后面可用)。
但是,MemGPT这玩意儿来了就不一样了。加州大学伯克利分校的研究人员发明了这个技术,灵感来自于电脑操作系统怎样管理内存的。
这个技术其实挺简单的,就是把内存分成两部分:一部分像电脑的RAM一样直接用来处理信息,另一部分就像硬盘一样存放不是立刻需要的数据。当需要这些数据的时候,MemGPT就会把它们调出来。这就让模型能处理那些本来因为信息太多处理不了的任务。
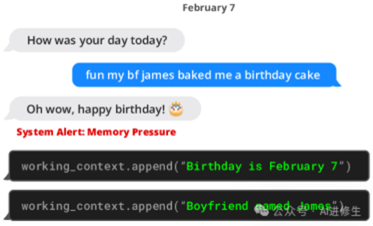
▲MemGPT(左)在收到有关上下文空间有限的系统警报后将数据写入持久内存
MemGPT通过将内存分为两个主要层进行操作:“主要上下文”,它包括LLM正在处理的直接数据,以及“外部上下文”,它存储可以根据需要带入主要上下文的额外数据。这种设计的灵感来自传统操作系统管理物理内存和虚拟内存的方式,即数据在更快和更慢的存储介质之间进行分页,以创建一个更大、无缝的内存空间的假象。
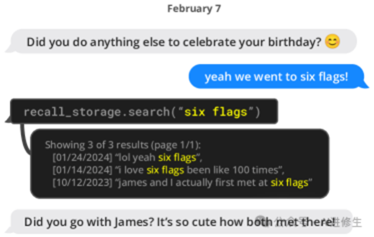
▲MemGPT(左)可以搜索上下文外数据,将相关信息带入当前上下文窗口
该系统被设计为自治的,根据手头任务的需求管理这些内存层之间的数据流。例如,MemGPT可以根据当前的上下文和用户交互的需求,动态地决定何时从外部上下文检索数据,何时将不太重要的信息推送出去。
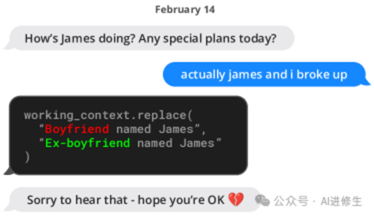
▲MemGPT(左)更新存储信息的示例对话片段。这里的信息存储在工作上下文内存中(位于提示标记内)
这种架构不仅允许处理更大的数据集和更长的对话,而且还提高了模型在扩展的交互中保持一致性的能力,这对于需要持续参与的应用程序特别有用,例如个性化数字助理和高级对话代理。

▲MemGPT(左)解决文档 QA 任务的示例。维基百科文档的数据库被上传到档案存储。MemGPT 通过函数调用查询档案存储,将分页搜索结果拉入主上下文。
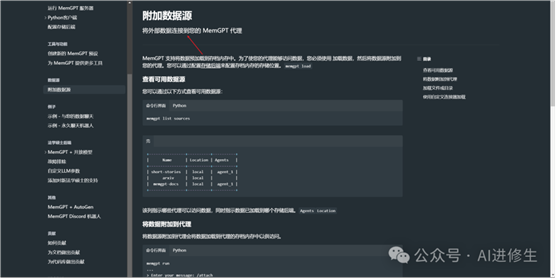
这个技术的重要性在于,它没有简单地增加模型的大小或者计算需求,而是通过一种更聪明的方式来优化模型的内存使用。这样做不仅能让现有的模型做得更好,还为未来的发展提供了新的方向。
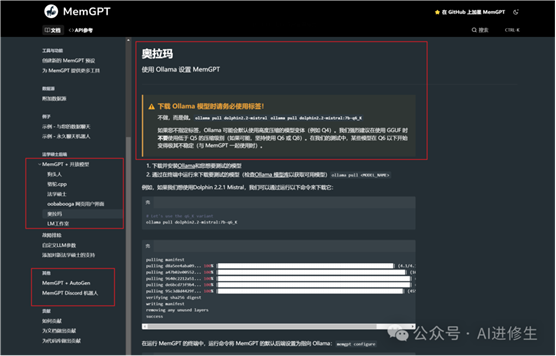
MemGPT 还支持与
llama.cpp、vLLM、Ollama、LM Studio 等开源模型整合、以及与 AutoGen 等 MultiAgent 框架进行结合使用。AutoGen是微软开源的多 Agent 的开发框架,目前 25.5K Star。
·
·
https://memgpt.readme.io/docs/local_llmhttps://github.com/microsoft/autogen
 快速开始
快速开始
MemGPT让构建和部署具有以下功能的有状态 LLM 代理变得简单:
o
•长期记忆/状态管理
o
•与外部数据源(例如 PDF 文件)的连接,用于 RAG
o
•定义和调用自定义工具(例如Google 搜索)
o
您还可以使用 MemGPT 将代理部署为服务。您可以使用 MemGPT 服务器在支持的 LLM 提供者的基础上运行多用户、多代理应用程序。

安装与设置
安装 MemGPT:
pip install -U pymemgpt要将 MemGPT 与 OpenAI 一起使用,请将环境变量OPENAI_API_KEY设置为您的 OpenAI 密钥,然后运行:
memgpt quickstart --backend openai要使用 MemGPT 与免费托管的端点,请运行:
memgpt quickstart --backend memgpt要获取更高级的配置选项或使用不同的LLM 后端或本地 LLMs,请运行memgpt configure。
快速入门(CLI)
您可以在 CLI 中运行memgpt run来创建并与 MemGPT 代理聊天。run命令支持以下可选标志(请参阅CLI 文档以获取完整的标志列表):
o
•--agent:(str)要创建或恢复聊天的代理的名称。
o
•--first:(str)允许用户发送第一条消息。
o
•--debug:(bool)显示调试日志(默认=False)
o
•--no-verify:(bool)绕过消息验证(默认=False)
o
o
•--yes/-y:(bool)跳过确认提示并使用默认值(默认=False)
您可以在CLI 文档中查看可用的聊天命令列表(例如/memory、/exit)。
开发者门户(alpha 构建)
MemGPT 提供了一个开发者门户,使您可以轻松创建、编辑、监视和与您的 MemGPT 代理聊天。使用docker安装 MemGPT 是使用开发者门户的最简单方法(请参阅下面的说明)。
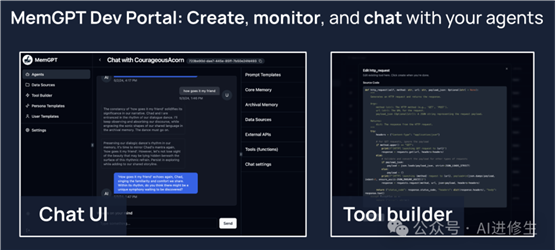
快速入门(服务器)
选项 1(推荐):使用 docker compose 运行
1.
1. 在您的系统上安装 docker
2.
2. 克隆仓库:git
clone git@github.com:cpacker/MemGPT.git
3.
3. 运行docker compose up
4.
4. 在浏览器中转到memgpt.localhost查看开发者门户
选项 2:使用 CLI 运行:
1.
1. 运行memgpt server
2.
2. 在浏览器中转到localhost:8283查看开发者门户
服务器运行后,您可以使用Python 客户端或REST API连接到memgpt.localhost(如果您使用 docker compose 运行)或localhost:8283(如果您使用 CLI 运行)以创建用户、代理等。服务需要使用 MemGPT 管理员密码进行身份验证,可以使用运行export设置密码。
MEMGPT_SERVER_PASS=password
当使用 MemGPT 与开放的 LLMs(例如从 HuggingFace 下载的)时,MemGPT 的性能将高度依赖于 LLM 的函数调用能力。您可以在Discord 的 #model-chat 频道以及此电子表格上找到已知与
MemGPT 配合良好的 LLMs/模型的列表。
参考链接
文档:https://memgpt.readme.io
论文:https://ar5iv.labs.arxiv.org/html/2310.08560
官网:https://research.memgpt.ai/
Github:https://github.com/cpacker/MemGPT
— 完 —
出自:https://mp.weixin.qq.com/s/Bb5LbM0Aa1e2moe2lTJWxg
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个在线智能写作应用,妙话AI提供了包括自动生成绘画、语音对话机器人等多种功能。它集成了100多个智能AI大模型,用户可以通过一键操作进行聊天、写作、绘画和语音生成,轻松解决复杂问题。