最强国产开源多模态大模型MiniCPM-V:可识别图片、视频,还可在端侧部署
发布时间:2024年08月07日
MiniCPM-V是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。
Github地址:https://github.com/OpenBMB/MiniCPM-V/
先看看我做的几个图片和视频的测试:
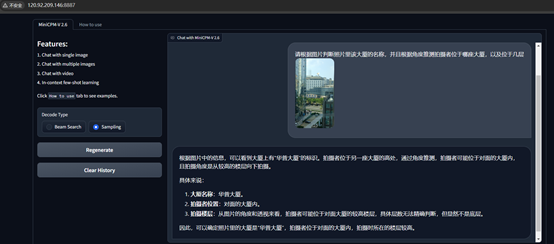

Demo地址:
http://120.92.209.146:8887/
自2024年2月以来,我们共发布了5个版本模型,旨在实现领先的性能和高效的部署,目前该系列最值得关注的模型包括:
- MiniCPM-V 2.6: 🔥🔥🔥
MiniCPM-V系列的最新、性能最佳模型。总参数量 8B,单图、多图和视频理解性能超越了 GPT-4V。在单图理解上,它取得了优于GPT-4o
mini、Gemini 1.5 Pro 和 Claude 3.5 Sonnet等商用闭源模型的表现,并进一步优化了 MiniCPM-Llama3-V 2.5 的 OCR、可信行为、多语言支持以及端侧部署等诸多特性。基于其领先的视觉 token 密度,MiniCPM-V 2.6 成为了首个支持在 iPad 等端侧设备上进行实时视频理解的多模态大模型。
- [2024.08.06] 🔥🔥🔥我们开源了 MiniCPM-V 2.6,该模型在单图、多图和视频理解方面取得了优于 GPT-4V 的表现。我们还进一步提升了 MiniCPM-Llama3-V
2.5 的多项亮点能力,并首次支持了 iPad 上的实时视频理解。欢迎试用! - [2024.08.03] MiniCPM-Llama3-V 2.5 技术报告已发布!欢迎点击这里查看。
- [2024.07.19] MiniCPM-Llama3-V 2.5 现已支持vLLM!
- [2024.05.28] 💥
MiniCPM-Llama3-V 2.5 现在在 llama.cpp 和 ollama 中完全支持其功能!请拉取我们最新的 fork 来使用:llama.cpp & ollama。我们还发布了各种大小的 GGUF 版本,请点击这里查看。请注意,目前官方仓库尚未支持 MiniCPM-Llama3-V 2.5,我们也正积极推进将这些功能合并到 llama.cpp & ollama 官方仓库,敬请关注! - [2024.05.28] 💫我们现在支持 MiniCPM-Llama3-V 2.5 的 LoRA 微调,更多内存使用统计信息可以在这里找到。
- [2024.05.23] 🔍我们添加了Phi-3-vision-128k-instruct 与
MiniCPM-Llama3-V 2.5的全面对比,包括基准测试评估、多语言能力和推理效率 🌟📊🌍🚀。点击这里查看详细信息。 - [2024.05.23] 🔥🔥🔥 MiniCPM-V 在 GitHub Trending 和 Hugging Face Trending 上登顶!MiniCPM-Llama3-V
2.5 Demo 被 Hugging Face 的
Gradio 官方账户推荐,欢迎点击这里体验!
MiniCPM-V 2.6是 MiniCPM-V 系列中最新、性能最佳的模型。该模型基于 SigLip-400M 和 Qwen2-7B 构建,共 8B 参数。与 MiniCPM-Llama3-V 2.5 相比,MiniCPM-V 2.6 性能提升显著,并引入了多图和视频理解的新功能。MiniCPM-V
2.6 的主要特点包括:
- 🔥领先的性能。 MiniCPM-V 2.6 在最新版本 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 65.2,以8B量级的大小在单图理解方面超越了 GPT-4o mini、GPT-4V、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。
- 🖼️多图理解和上下文学习。 MiniCPM-V 2.6 还支持多图对话和推理。它在 Mantis-Eval、BLINK、Mathverse mv 和 Sciverse mv 等主流多图评测基准中取得了最佳水平,并展现出了优秀的上下文学习能力。
- 🎬视频理解。 MiniCPM-V 2.6 还可以接受视频输入,进行对话和提供涵盖时序和空间信息的详细视频描述。模型在
有/无字幕 评测场景下的 Video-MME 表现均超过了GPT-4V、Claude 3.5
Sonnet 和 LLaVA-NeXT-Video-34B等商用闭源模型。 - 💪强大的 OCR 能力及其他功能。 MiniCPM-V 2.6 可以处理任意长宽比的图像,像素数可达 180 万(如 1344x1344)。在 OCRBench 上取得最佳水平,超过 GPT-4o、GPT-4V 和 Gemini 1.5 Pro 等商用闭源模型。基于最新的RLAIF-V和VisCPM技术,其具备了可信的多模态行为,在 Object HalBench 上的幻觉率显著低于 GPT-4o 和 GPT-4V,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
- 🚀卓越的效率。除了对个人用户友好的模型大小,MiniCPM-V 2.6 还表现出最先进的视觉 token 密度(即每个视觉 token 编码的像素数量)。它仅需 640 个 token 即可处理 180 万像素图像,比大多数模型少 75%。这一特性优化了模型的推理速度、首 token 延迟、内存占用和功耗。因此,MiniCPM-V 2.6 可以支持 iPad 等终端设备上的高效实时视频理解。
- 💫易于使用。 MiniCPM-V 2.6 可以通过多种方式轻松使用:(1) llama.cpp和ollama支持在本地设备上进行高效的 CPU 推理,(2) int4和GGUF格式的量化模型,有 16 种尺寸,(3) vLLM支持高吞吐量和内存高效的推理,(4) 针对新领域和任务进行微调,(5) 使用Gradio快速设置本地 WebUI 演示,(6) 在线demo即可体验。

看看他的强大之处:

Online Demo
欢迎试用 Online Demo: MiniCPM-V 2.6 | MiniCPM-Llama3-V
2.5 | MiniCPM-V
2.0。
本地 WebUI Demo
您可以使用以下命令轻松构建自己的本地 WebUI Demo。
pip install -r requirements.txt
# 对于 NVIDIA GPU,请运行:
python web_demo_2.6.py --device cuda
安装
克隆我们的仓库并跳转到相应目录
git clone
https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
创建 conda 环境
conda create -n MiniCPMV python=3.10 -y
conda activate MiniCPMV
安装依赖
pip install -r requirements.txt
模型下载地址:
MiniCPM-V 2.6:GPU版本,大小:17 GB
提供最佳的端侧单图、多图、视频理解能力。
https://huggingface.co/openbmb/MiniCPM-V-2_6
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6
MiniCPM-V 2.6 gguf:CPU版本,大小6 GB
gguf 版本,更低的内存占用和更高的推理效率
https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6-gguf
MiniCPM-V 2.6:int4版本,GPU版本,大小:7 GB
int4量化版,更低显存占用
https://huggingface.co/openbmb/MiniCPM-V-2_6-int4
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6-int4
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款先进的线上英语语法检查,文章改写润色工具,旨在增强写作过程,可为您自动检测文本各类英文语言使用错误,完成准确高效的英文校对,高效改善英文文本可读性。