RAG 2.0来了,它能成为生产落地的福音吗?
发布时间:2024年08月22日
RAG作为当前最流行、相对成熟的的LLM应用架构,受到了开发者的广泛关注,相关围绕RAG优化的技术层出不穷,但依旧难逃达不到生产应用要求的尴尬。
在典型的RAG系统中,通常会采用现成的通用嵌入模型来实现数据的嵌入处理,利用向量数据库进行高效的信息检索,并结合大型的黑盒语言模型来完成内容的生成。这些独立的技术组件通过提示或编排框架被整合在一起,形成了一个看似完整的系统。然而,这种方法往往会导致所谓的“科学怪人效应”(Frankenstein’s monster),即尽管每个部分在技术上都能独立运行,但整合后的整体性能却远未达到理想状态。这样的系统不仅脆弱,缺乏对特定部署领域的机器学习和专业化调整,而且对大量的提示高度依赖,这使得系统在运行过程中容易出现连锁性的误差。参看:大模型也有“漂移(Drift)”现象?应引起AI应用开发者警惕。因此,RAG 系统很少能通过生产测试,投入生产的寥寥。
现在,RAG最初的发明者现任Contextual AI 的CEO Douwe Kiela等人对外发布了RAG 2.0。该方法将所有组件作为单个集成系统进行预训练、微调和对齐,通过语言模型和检索器进行反向传播以最大化性能:对齐为一个集成的系统,通过语言模型和检索器进行反向传播以最大化性能。这一点类似于我们优化推荐系统,并非简单的优化精排模型,而是需要端到端的从召回,粗排,精排,重排环节作为整体来优化,避免形成错配,如图出现不对齐现象,不管精排模型如何优化都难以达到好的优化目标。
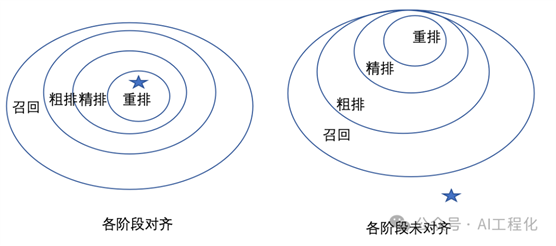
RAG 2.0方法就是克服这样的局部优化办法,通过将预训练、微调和对齐所有组件形成一个统一系统,通过反向传播同时优化语言模型和检索器,以最大化系统性能。

某种意义上讲,相比较传统的分阶段的优化手段,大模型的效果能够获得突破也得益于端到端的黑盒优化。
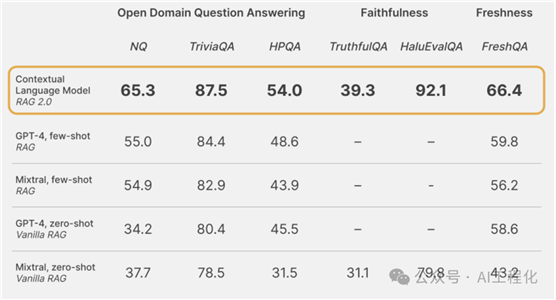
Contextual AI 针对他们提出的RAG2.0设计了一个基准测试,从多个维度比较了上下文语言模型(CLMs)与固定RAG系统:
·
开放域问答:使用标准的Natural
Questions(NQ)和TriviaQA数据集来测试每个模型正确检索相关知识并准确生成答案的能力。我们还评估了模型在HotpotQA(HPQA)数据集上单步检索设置下的表现。所有数据集均使用完全匹配(EM)指标。
·
忠实度:HaluEvalQA和TruthfulQA被用来衡量每个模型保持基于检索证据的忠实度以及避免产生幻觉的能力。
·
新颖度:通过使用网络搜索索引来衡量每个RAG系统对快速变化的世界知识的泛化能力,并展示了在最近的FreshQA基准测试中的准确性。
·
这些维度中的每一个对于构建生产级别的RAG系统都至关重要。下图展示了CLMs在多个强大的固定RAG系统上显著提高了性能,这些RAG系统是使用GPT-4或像Mixtral这样的最先进的开源模型构建的。
在真实数据集下的效果也表现优异。即使在特定于金融的开卷问答任务上,CLMs也超越了固定的RAG系统——并且在法律和硬件工程等其他专业领域也有类似的提升。

他们也做了RAG 2.0与具有长上下文窗口的最新模型的比较。专门进行了大海捞针实验(了解:超长上下文窗口大模型的“照妖镜”——大海捞针实验,大模型“打假”必知必会)创建一个不重复的200万token的“大海”,使用包含100多个问题的测试集,评估了CLM、固定-RAG和GPT-4-Turbo(仅限于最多32K 窗口)在从2K到2M窗口不等的“大海”上的表现。
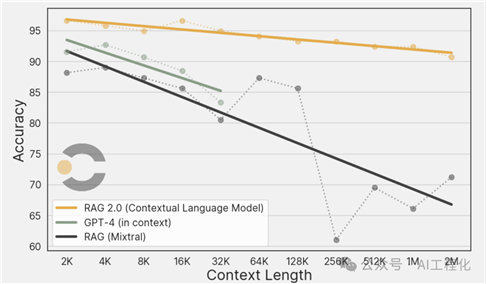
显而易见的是,在寻求扩展上下文窗口的能力方面,RAG 2.0展现了显著的优势。与长上下文语言模型相比,RAG 2.0不仅在准确度上有所提升,而且在计算资源的消耗上也有显著减少。这种差异在实际的生产应用中显得尤为重要。
从优化思路和最终效果上看,RAG 2.0确实能够给开发者一些启发,端到端地进行优化,值得一提的是Contextual
AI 不仅有上下文语言模型(CLMs)还有微调和对齐技术(例如GRIT、KTO和LENS),感兴趣的可以了解。
出自:https://mp.weixin.qq.com/s/ct9ev0qF0OGA60ow_JHSBw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款由GPT4驱动的人工智能网页设计主题生成工具,使用 ThemeAI 释放您的创造力并轻松重新定义网页设计!利用人工智能的力量为您的网站制作和策划有意义的网页模板主题。