AIGC工具提示词技巧
发布时间:2024年08月22日
- 01-
提示词本质和写法
提示词的本质。
相信大家对于提示词已经不陌生。简单来讲,就像写出一篇好的作文或者演讲,需要过往的积累,需要一些技巧。
比如写一篇命题作文,或者回答一个政治题,用什么样的框架、什么样的方向、什么样的开场,内容如何填充,用怎样的结构性语言?这是提示词工程重要的内容。
以前,我们和软件对话用的是搜索的逻辑:把我们想要的结果、方向描述出来放到浏览器、搜索引擎做检索。而现在,给机器或者程序一个具体指令,比如背景、原因、想要的结果等,需要用结构化语言告诉模型。
提示词的写法框架。
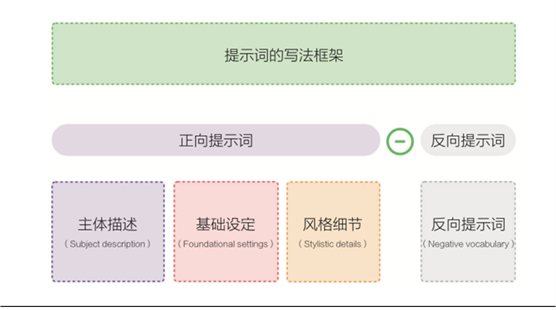 主要包括两种:正向提示词和反向提示词。
主要包括两种:正向提示词和反向提示词。
常规写法采用正向提示词,就是正常说话写文章的行文逻辑。在正常的一个语法结构里面,正向提示词是符合大多数人思维习惯的。
但在图像生成和视频生成领域,生成一个人物形象的时候,像手指是否畸形、五官是否贴切、肢体是否正常等细节方面,需要灌输一些反向提示词,让它避免出现我们不想要的效果。如果想要提高结果的正确率,降低答案、绘图、视频结果的细节误差,就需要使用反向提示词做不良效果规避。
目前,许多工具都支持正向提示词,就是把我们的想法,类似于原先搜索引擎与检索的思路,输入到输入框和工具进行交互。输入内容和我们的语法结构没有太大区别,即包括:主体描述、基础设定和风格细节。
大多数人对主体描述都能讲清楚,知道自己要什么,哪怕简短的一句话也能让工具给出一个看着像样的答案。
但是后两个要素,基础设定和风格细节方面,因为大家词汇和知识储备不同,使用的提示词不同,最终AI工具根据给定的提示词给出生成的效果也会不同。这个不同是有比较明显的等级区分的,提示词的质量会很大概率决定输出结果的质量。
比如,专业摄影师在光线、构图、主体姿态、视频转场等效果上,对细节的描述可以更具体;
比如,建筑设计师、室内设计师、材料设计师、工业设计师,会对具体的材质、工艺、流程,一些细节处理上,有更加详细的词汇表述。
与之相比,在这些专业词汇和处理流程领域,普通大众缺少必要的行业认知和know how。目前,大部分人还是用传统搜索引擎的语言或逻辑去编写提示词,就是大家想到什么就说什么,但在结果生成上会有很大差距。所以,如何写好一个优质的提示词,需要掌握一些必要的技巧。
提示词构成的写法。

1、提示词的书写要清晰,带有明确的指令:使用分隔符清楚地指示输入的不同部分,便于维护。在交互式对话中将复杂的任务分解为一系列更简单的提示。
2、英文。正反提示词。部分场景需求中英文提示词都使用,看看哪种效果更好。用简单的英语写文章/文本/段落。
3、一定的框架结构,还有测试表单。许多词汇效果需要微调,一般一组提示词我会测试3遍,然后进行词汇的调整和修饰。
4、使用不同的工具,审读平台的技术文档 产品手册,了解字段、参数配置和概念的功能定义。了解产品的不同版本和最近迭代的新功能。
5、指明固定格式输出结果:如JSON、HTML等。
6、引导chatbot,告诉他一个扮演的角色,或者具体的场景指令。
7、在书写提示词时,常用的分隔符包括但不限于以下几种:“|”:用于分隔指令和上下文,有助于模型更好地理解何时切换到不同的任务或上下文;“#”:用于分隔指令和上下文,有助于模型更好地理解何时切换到不同的任务或上下文;“::”:用于将完整的描述词分割为两个或多个单独的概念,还可以通过在“::”后添加数字,为不同的概念分配不同的权重,使生成的图像在内容上产生变化;“,”:用于分隔提示词中的多个描述性词汇,一般为英文词汇和英文逗号。
8、让模型检测条件是否被满足。
9、格式化提示时,以#Instruction#开头,然后是#Example#或#Question#(如果相关)。随后展示你的内容。使用一个或多个换行符用于分隔指令、示例、问题、上下文和输入数据。
另外,大家可以多参照OpenAI提示词官方技术文档,以及根据一些关键词,在小红书、公众号里面搜索学习行业领域先驱者的分享。
- 02 -
提示词应用范例Recognize Anything:
这张图很好,我该怎么描述它呢?
我们在构思一次绘画创作的时候,有两个思维方式:一种是我们自己去想提示词,让工具来实现我们的想法创意;另一种是我们看到一个图或一个东西,但是我们不知道它具体的提示词是怎么样去拆解的,就是机器怎样去理解这个图或是这个视频。
那么我们可以使用到一个反向的工具,比如说我用Hugging face一个开源的工具。我可以把我想要的一个遥感图,或者说一个自然图传上去。它能够智能提取,识别分割我们一张图里面的信息,同时能让里面的一些元素转成我们能理解的自然语言的一些代码或者是标签,或者是我们能理解的一些文字性的内容。这样我们可以把一张图,比如说未来中心的一个内生的场景设计图,我们把它丢进去之后,它能给我们去做一些拆分。项目地址:https://huggingface.co/spaces/xinyu1205/recognize-anything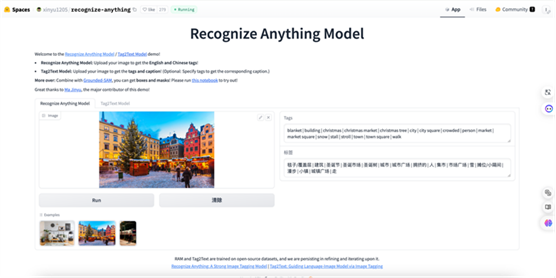 它的用处在于,当你想要一个特别好的画面效果,或者想要一个具体的表述,但是想不出这个词汇,不清楚该怎么表述主体和修饰词的时候,就可以使用recognize anything model模型把你要的图片拖拽到左侧的进行识别,右侧能实时提取出英文tags和中文标签。我们可以拿这些主体和修饰词汇自行编组,构建一条提示词放到国内外的各种工具中进行结果生成。
它的用处在于,当你想要一个特别好的画面效果,或者想要一个具体的表述,但是想不出这个词汇,不清楚该怎么表述主体和修饰词的时候,就可以使用recognize anything model模型把你要的图片拖拽到左侧的进行识别,右侧能实时提取出英文tags和中文标签。我们可以拿这些主体和修饰词汇自行编组,构建一条提示词放到国内外的各种工具中进行结果生成。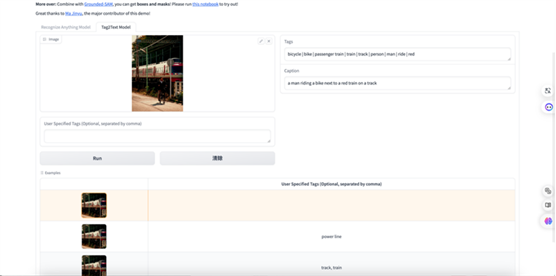 在这个平台的第二个模块中,导入你要参考使用的图片,不仅能提取出画面主体,还可以对画面内容进行解释。解释的这条基础提示词内容也可以拿来放到别的平台进行使用。Hidream.ai:结构化的提示词框架,教会你编组
在这个平台的第二个模块中,导入你要参考使用的图片,不仅能提取出画面主体,还可以对画面内容进行解释。解释的这条基础提示词内容也可以拿来放到别的平台进行使用。Hidream.ai:结构化的提示词框架,教会你编组

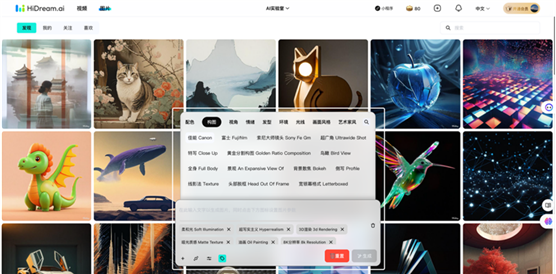
上面这个平台,是我看过的对用户最友好的AI绘画交互方式了,他给比较基础的用户提供了勾选组词的使用方式,可以让大家不用背各种专业的词汇术语,就可以利用到这些高阶的专业效果。通过点击不同的标签,我们可以快速组成想要的修饰词汇,但前提是我们仍然需要在文本输入框中输入主体描述,确定我们想要一个什么样的东西/物体/人。平台会在主体描述后面,自行理解这些随机组成的修饰词汇对应的设计效果,帮助产出高质量的画面效果。
造梦日记:
详细的用户手册文档,帮你爱上AI绘画
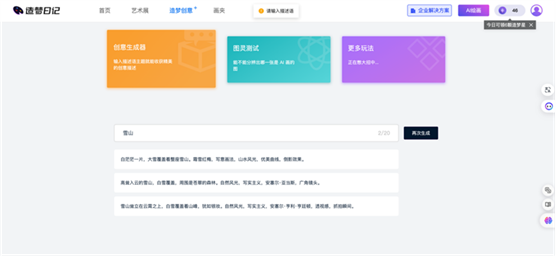
造梦日记给了一个特别详细生动的用户操作手册,不需要花费很多的时间学习,我们就可以把想要内容的提示词描述一整块结构梳理出来。

类似特别详细的提示词汇库,我们在《一本书读懂AIGC提示词》这本书里面也整理提供了特别多的修饰提示词,在中间章节部分也有引导大家使用各个平台从0到1生产的讲解内容。
 项目地址:https://fuhgh5u28j.feishu.cn/docx/doxcnPVITN5dA1CawR8ZbWYWBfh
项目地址:https://fuhgh5u28j.feishu.cn/docx/doxcnPVITN5dA1CawR8ZbWYWBfh
在大家日常使用的场景,尤其是工作中或者说自己想发个朋友圈,想做一个复杂的效果图时,我们还可以去小红书,搜到许多Midjourney词典。它会对这些词有一个画面效果非常直观的解释,我们如果不太理解纯文本的内容,比如说玻璃状或者说水晶状,还是说其他一个词汇,我们可以在网上找到公开的一些资料,它会给你一些不同的图的效果,帮助你去更好的使用这个工具。
百度千帆社区:提示词模板
像百度智能云的千帆社区,提供了许多文本类型,调用大模型能力的模板。目前来讲许多大模型的平台,因为他们要增强用户的使用和调用的次数,避免大家上来用一用之后就不会再用了,所以它提供了许多的创意模板。缺点在于,百度的平台老做各种调整,许多好用的模块经常就找不见了。
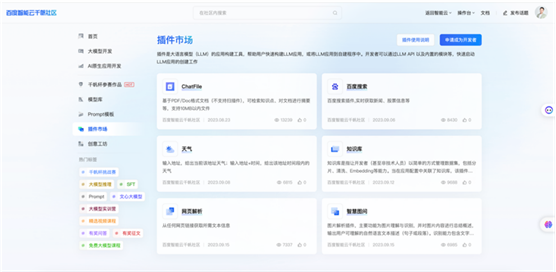
项目地址:https://cloud.baidu.com/qianfandev/prompt
AI视频重大突破:Sora
去年我们在编写书时,大家用的更多的还是文生文和文生图这个领域,而文生视频在去年做的都比较糙。我使用了主流的几个工具,像Runway,Pika ,PixVerse,StableVideo,Dreamina,都使用这些平台做了一些视频。但是我们对Sora的评价是,它对于物理细节或者说是质感的理解还是更深的。
我们可以看到像Sora,在我们使用一些文生视频工具时,它提示词也没有那么复杂。在网上、公众号上可以搜索sora提示词,有许多公众号的作者做了系统的收集。目前为止OpenAI放出来的sora的一些视频片段,他们都有对应的提示词,有的特别多。
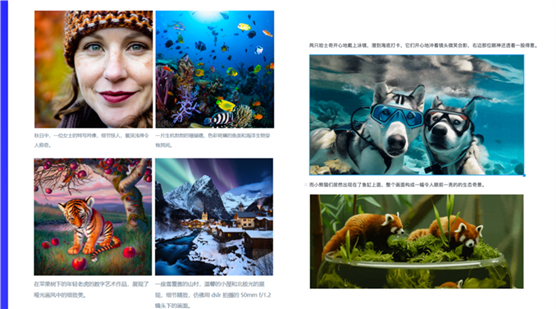
像这块中英文提示词都有,目前许多国内的用户更多的一个使用习惯是我自己先想个中文,然后丢到翻译软件里面,去转换成英文。因为像国外的一些工具,他们对于英文的理解会更加细致一些,会减少一些不必要的泛化,或者说一些胡言乱语。
国内大模型工具测试
我们可以看到中国长发美女照片这个提示词,这是我在朋友圈看到有人发了一下,然后我就试着去把这些东西做了一些缩减和技术新增。

我们可以看到在这方面,把他想要的一个效果图写的特别丰富的话,有些词大家能够理解,然后像广角效果、镜头、近逆光、脸部特写,真人摄影效果等等,就比较偏专业一些了。我这块是拿一段提示词,做了各种改写,在通义、文心、kimi以及智谱清言,国内许多的大模型工具上都做过测试。
目前文心一言的效果是比较符合大家对于一个很好的照片或者是图片的理解的。大家只需要拿同样提示词放到不同的工具里面去做一些测试,就可以看到文心一言对于生成这块的理解,是比较好的。
然后像大模型工具,不管是国内的还是国外的,比如我用Midjourney去做一些扑克牌或者是文字、符号的设定时,他在这种符号细节上,他能理解你的意思,但在生成最终的图案时,会出现细节做的不是很精细的情况。包括我在做一些文生视频时,我想要一个文字或者说一个文本,但是它最后出来的是一些奇怪的符号,不太符合我们想要的一个结果。
目前我了解到的文生视频或者是做的比较好的一个图片,都是前期我先用Midjourney把我想要的一个效果图先做出来,再把那个图导入到我们不同的视频工具里面,比如说字节的Dreamina,Runway和PixVerse里面生成视频片段,最后再用工具去做后期的处理,把想要的文字P上去。
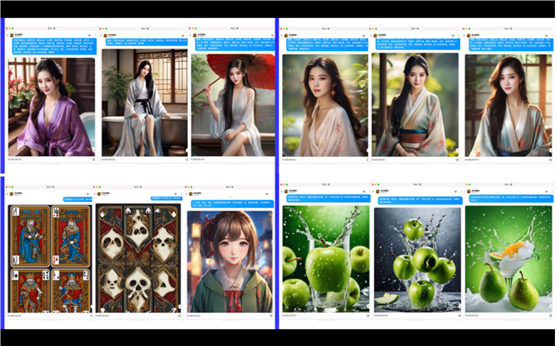
这是一个广告摄影的效果图。一般大家很少会想到说我要去生成一个这样的东西。这是我朋友做的一个效果图,他们输入了不同的一个提示词,去产出不同的效果。像这种效果我去实拍需要花特别多的时间。因为我要布景,我要去把这些设备架好,光要调好,一些物料我要弄好。而以后对于摄影领域来讲,我们可以大量使用这种提示词,生成我们想要的一些摄影的图。目前接触到的在阿里、拼多多以及小红书的朋友,他们已经在开发这样的东西,同时有新的一些算法模型支持把这些静态图导入进去,去做成动图的Gif和特效。
- 03 -
提示词编写技巧
1.编写清晰的指令——提供细节和背景
对于一些具体的编写提示词的技巧,我觉得最好还是先把OpenAI的技术文档理解好。因为大家在后续做提示词的结构化处理或者是延伸时,都是基于技术文档的理解开展。首先想要编写一个提示词,大模型为了满足大家的一个需求,其实会给大家一句简短的话,会给大家提供一个答复,但是最终想要落地,你具体想要的,想解决一个具体问题时,你这一句话是不太够的。那么就需要帮我分析一下当前环境哪些有前景等等,然后告诉它。
2.编写清晰的指令——角色扮演
就是请你以一个专家,比如说刚刚的高总,以一个医疗行业专家的角度帮我去分析一下怎么样。
3. 使用分隔符清晰标示输入的不同部分
提示词的一个切割,让它生成一个有条理的markdown的结果。
4. 指定任务所需步骤
这在agent里面又会用的比较多。我们在使用字节的扣子或者阿里的魔搭时,我们自己搭建agent智能体会先给他一个角色设定,同时也会给他一个初始化的语言。然后告诉它说我需要让你扮演一个什么样的角色,同时要给我完成一个什么样的任务,会像教我自己的一个下属,告诉他12345怎样去落地
5.提供样例
需要给大模型提供一个demo,告诉它我最终想要的结果是什么样的,避免它在生成内容时有特别多的一些偏差。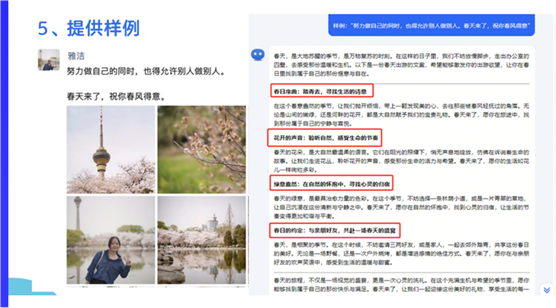
6. 指定输出长度
一般就是在结尾时加一个“需要多少字”。
- 04 -
好用的AI工具推荐目前来讲,我的办公桌面上,如果想要一个什么样的结果,我可以把智谱清言、讯飞星火、通义,字节豆包,百度文心,月之暗面的kimi,昆仑万维的天工,把这些东西挨个拿出来。因为在Mac端有个好处,就是这些大模型都做了APP。推荐几个好用的工具。
通义听悟。
是我目前日常生活中使用最多的一个工具。比如说今天这样一个场景分享,或者是我去参加一些行业大会时,我基本上就是电脑或者说手机放那录音,然后我拿相机去拍他的PPT,或者是整个的场景。这样我一边听人家嘉宾的分享,同时等我活动结束,一键就可以转成我们智能的会议纪要,而且能够区分多人的语言发音。
为什么我不用腾讯会议呢?因为腾讯会议它有各种各样的一些限制,不太方便,其他的一些软件,像讯飞它的限制也会比较多。而阿里你只要每天登录它都会给你10小时,然后最多可以给你400小时的一个免费时长。
Suno。
是目前AI生成音乐里面做的比较好的。他之前的版本其实也有许多人使用,但在今年三月份,就是上个月的时候,Suno做了它最新版本的更新。现在在AI生成音乐上的话,已经达到了比较好的效果。
Runway。
Runway支持视频,图像,3D以及其他的一些生成。像文本生成图像,我们可以看到在右边它可以选不同的尺寸大小,有些工具会有不同的模型的选择、比例,以及单次生成图像的数量。
PixVerse。
则是做了反向提示词这一特别明显的功能。上面写自己想要的一段结构化的提示词,下面把不想要的一些效果去掉,然后选择一个你想要的风格。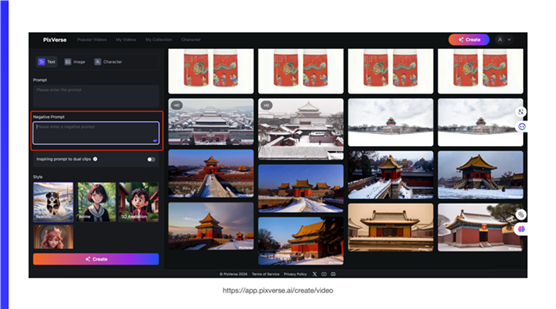
(全文经录音整理,受篇幅限制,部分文字、图片有所删减)
出自:https://mp.weixin.qq.com/s/a285J5wWJ8XpGlCTTUpSCw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
基于讯飞星火知识库方案,高效检索文档信息,准确回答专业问题提供Al分析、阅读、问答工具,让大模型助你高效了解文档内容