体验完阿里的EMO模型,我emo了
发布时间:2024年08月29日
一、唠嗑
近日,阿里宣布通义千问研发的AI模型—EMO模型正式上线通义千问App,并开放给所有用户免费使用。
简单来说,EMO(Emote Portrait Alive)是一个AI肖像视频生成系统,能够通过输入单一的参考图像,生成具有一定表现力的面部标签和各种头部姿态。
(话说,是不是开发人员搞AI模型太痛苦了,所以才取了这个名字,哈哈
二、如何体验
首先是需要先下载通义千问App,但这个功能并没有在界面展示出来,需要手动输入 “EMO” 关键词出发
![]()
![]()
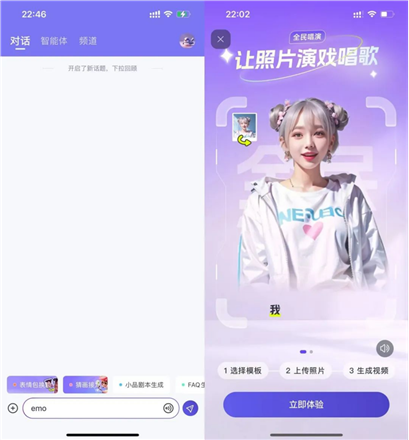
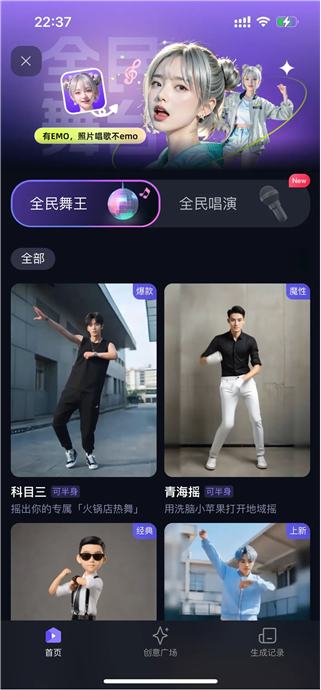
进入主页面后,可以发现目前主要有两个功能,一是全民舞王,二是全民唱演
![]()
三、全民舞王体验
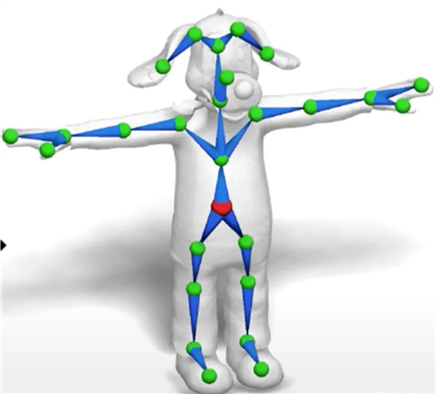
全民舞王利用的是一种AI生成3D骨骼的技术。这种技术能够自动学习3D模型的形状和动作,并根据学习到的模型参数实现动画骨骼控制。
简单来说,比如你有这样一个模型
![]()

通过这种技术,能够自动给它画上骨架,这样AI就能控制它做一些动作了
目前看得话,全民舞王生成的效果还是比较逼真的,比如看这个真人女孩:
,时长00:10
注:本视频来源于通义千问EMO首页视频,侵权删
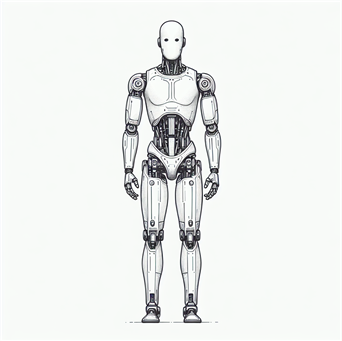
我体验的时候,为了避免侵权,使用的是AI生成的一个全身机器人,最终的效果如下,感觉还是不错的,这是照片:
![]()
这是视频(你就说跳得好不好
,时长00:12
四、全民唱演体验
全民舞王利用的是一种口唇同步的技术,这是一种让画面人物的口型与所配的语音或文字信息精确匹配的技术。这项技术能够使画面人物在说话时,其嘴唇的动作与发出的声音同步,从而在视觉和听觉上为观众提供一种更加自然和逼真的体验。
目前在开源界,比较出名的口唇同步框架是 wav2lip[1],如果是自己部署的话,会比较麻烦,搭环境估计都得折腾个几个小时,很容易在
opencv的版本上踩坑。
wav2lip支持两种模式,第一种是根据 视频+音频 的方式生成口唇同步的视频,第二种就是根据 图片+音频 的方式生成口唇同步的视频,也就是全民唱演这种方式。
从理论上来说,视频+音频 的方式肯定是比图片+音频 的效果要更好,因为他相当于是每一帧画面都进行了口唇调整,所以整体效果肯定更好(需要注意的是,使用wav2lip需要保证视频里面的每一帧都是人脸)
下面看看全民唱演的效果(我看到EMO模型脑子第一个想到的就是这个):
,时长00:06
注:本视频来源于通义千问EMO首页视频,侵权删
可以看到,全民唱演的效果目前还不是很理想,还是很容易就看出是AI生成的,因为你可以看到只有嘴巴周围的部位在动,其他地方是几乎没动的。
不过我也发现一个效果稍微好点的(因为这个身体姿态也在动):
,时长00:04
注:本视频来源于通义千问EMO首页视频,侵权删
五、潜在的风险
虽然科技能带来进步,但它带来的风险同样不可忽视!
第一就是散布虚假信息,因为通过这些技术,可以创建看似真实的视频,但其中的人物或角色说出他们实际上并未说过的话,这可能被用于误导公众、诽谤个人或散布虚假新闻,即所谓的“深度伪造”。
第二就是普通人被诈骗的可能性提高,之前在B站看过一个视频,讲述就是一对母女通过微信视频通话,但是与之通话的女儿其实不是真实的,大家感兴趣可以看看https://www.bilibili.com/video/BV1bQ4y1t7rc/
第三就是侵犯他人的隐私,比如之前沸沸扬扬的数字人复活”已逝亲人”,特别是有些人在未经允许的情况下“复活”了一些明星,给他们的家人又带来了痛苦。
总之,技术是一把双刃剑,希望我们每个人都能利用它好的部分!(也请大家多多点赞哈)
出自:https://mp.weixin.qq.com/s/zIB91lAChNlNQlZpv6n_ZA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
造梦日记Ai,凭借在AI领域多年的深耕以及西湖大学实验室的成熟算力,用户输入一些关键词或者一段描述某场景的文字,便可在几秒内生成一张独创的、版权归属于自己的图片。