手把手!做Llama3的MoE专家混合模型!底层原理怎样的?做自己的MoE模型?需要多少算力?
发布时间:2024年09月10日
AI发展太快!llama3表现爆棚!
大量的垂直领域的专家模型上线,教育组!llama3的微调!上一篇,雄哥带着大家手把手微调了Llama3!
动手微调Llama3!纯本地+手把手!ORPO偏好微调,数据集工具指南!base到chat模型微调方案!day01
llama3能力,雄哥知根知底,本地实跑+测试!还没看?这里看!
首发!Llama3纯本地部署攻略!中文方法!含秒下载通道!超越GPT4?能力如何?手把手教程!
倘若把不同领域模型,组成MoE专家混合模型呢?
本篇!彻底把MoE讲透!并且把经典技术论文(20+篇)找出来!然后,跟着雄哥动手做自己的MoE模型!
人的专注力只有10分钟!那,话不多说!
①什么是MoE模型?frankenMoE 或
MoErges?
②创建MoE模型的过程是怎样?方法是?
③跑一个实例!把Llama3和Phi-3组成MoE!
以上!同步适用自己微调的垂类大模型,例如代码生成LLM+教育专家LLM!
整个系列内容是这样的:

第一部分:什么是MoE模型?
专家混合是一种旨在提高效率和性能的架构!
使用多个专用子网,称为“专家”!与激活整个网络的密集模型不同,MoE 仅根据输入激活相对应的专家!这样可以加快训练速度,提高推理效率!
你想,让一个大模型既懂代码,又懂教育,是很难得,即使做到,项目开发周期非常长!到那时,技术早已翻篇!
MoE 模型的核心有两个组成部分:
#A 稀疏 MoE 层:这些层取代了变压器架构中的密集前馈网络层。每个
MoE 层都包含多个专家,并且只有这些专家的子集参与给定的输入。
#B Gate Network 或Router:此组件确定哪些tokens由哪些专家处理,确保输入的任务都由最合适的专家处理。
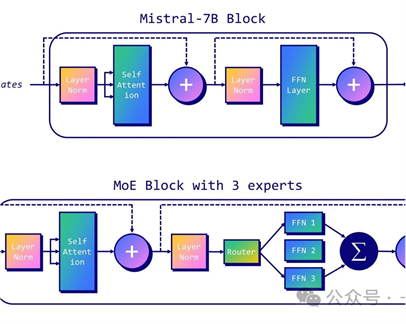
看下图!
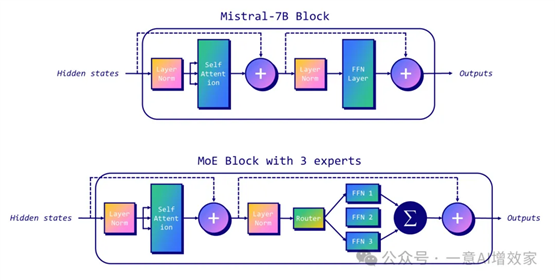
上图表示有三名专家,示意如何将
Mistral-7B 转换为具有稀疏 MoE 层(前馈网络 1、2 、 3)和路由 MoE!
不过,MoE模型本身的模型非常复杂!再想微调,很难!
难在哪?
需要在训练期间平衡专家的使用,以正确训练门控权重以选择最相关的权重。显存需求方面,即使推理过程中只使用了总参数的一部分,但整个模型(包括所有专家)都需要加载到内存中,这需要很大的VRAM!
具体来说,MoE 有两个参数:
·
专家数量(num_local_experts):这决定架构中的专家总数(例如,Mixtral 为 8)。专家数量越多,VRAM需求就越高!
·
·
专家数量/tonke (num_experts_per_tok):这决定了每个tonke和每层的专家数量(例如,Mixtral 为 2)。每个令牌的准确性(但回报递减)与快速训练和推理的专家数量较少之间存在权衡。
·
在星球的朋友就知道,MoE 其实是一项很活跃的研究!雄哥分享了大量的技术论文和实践到会员盘!之前表现落后于密集型模型的!
然而!2023 年 12 月发布的 Mixtral-8x7B ,非常震撼!此外,有传言 GPT-4 是 MoE,有道理的,因为与密集模型相比,为 OpenAI 运行和训练要便宜得多。除了这些最近出色的 MoE 之外,我们现在还有一种使用 MergeKit 创建 MoE 的新方法:frankenMoE,别称 MoErges!
什么是frankenMoE?
真正的 MoE 和 frankenMoE 之间!主要区别是训练方式不同!
真正的MoE,专家和路由器是一起训练的!
frankenMoE,是对现有模型进行升级改造,然后初始化路由器,组合的!
MoE=原装训练!
frankenMoE=后天组合!
换句话说,我们从基础模型中复制层范数和自注意力层的权重,然后复制在每个专家中找到的 FFN 层的权重。这意味着除了 FFN 之外,所有其他参数都是共享的。这就解释了,为什么八位专家的 Mixtral-8x7B 没有 8*7 = 56B 参数,而是 45B!
FrankenMoE是关于选择最相关的专家并正确初始化它们。MergeKit 目前实现了三种初始化路由器的方法:
1.
随机:随机权重。随机选择哪个专家来回答!
2.
嵌入向量:直接使用输入标记的原始嵌入,并在所有层中应用相同的转换。这种方法在计算上成本低廉,适合在功能较弱的硬件上执行。
3.
隐藏状态表示:它通过从
LLM 的最后一层提取正面和负面提示列表来创建它们。对它们进行平均和归一化以初始化门。
为了让大家更深入了解这些区别,雄哥分别写了三个MoE的代码示例!
#A 随机分配权重
·
if mode == "random":
return torch.randn(
(model_cfg.num_hidden_layers, len(experts), model_cfg.hidden_size)
)
这段代码是一个条件语句的一部分,用于检查变量
mode 是否等于字符串 "random"。如果条件为真,则执行以下操作:
1.
使用 torch.randn 函数生成一个张量,该张量的形状由三个维度组成:
·
第一个维度是
model_cfg.num_hidden_layers,表示模型的隐藏层数量。
·
第二个维度是 len(experts),表示专家的数量。
·
第三个维度是
model_cfg.hidden_size,表示每个隐藏层的尺寸。
2.
torch.randn 函数会创建一个张量,其中的元素是从标准正态分布(均值为0,方差为1)中随机抽取的。
3.
这个张量被用作返回值,即函数的输出。
简而言之,如果 mode 设置为 "random",这段代码将返回一个随机初始化的张量,该张量的形状由模型的隐藏层数、专家数量和隐藏层尺寸决定。
#B 嵌入向量
·
·
·
def get_cheap_embedding( embed: torch.Tensor, tokenized: Dict[str, torch.Tensor], num_layers: int, vocab_size: int,) -> torch.Tensor: onehot = torch.nn.functional.one_hot( tokenized["input_ids"], num_classes=vocab_size ) h = onehot.float() @ embed.float() embedded = ( (h * tokenized["attention_mask"].unsqueeze(-1)) .sum(dim=1) .sum(dim=0, keepdim=True) ) res = embedded / embedded.norm(dim=-1, keepdim=True).clamp( min=1e-8 ) return res.repeat(num_layers, 1)
这段代码,定义了一个函数
get_cheap_embedding,用于计算文本的嵌入向量的!
函数首先将输入文本转换为 one-hot 编码,然后与嵌入矩阵相乘得到嵌入张量。接着,将嵌入张量与注意力掩码相乘并求和,得到一个嵌入向量。最后,这个嵌入向量被归一化并重复多次,以匹配模型的层数!
#A 隐藏状态
·
·
def get_hidden_states( model: Union[MistralForCausalLM, LlamaForCausalLM], tokenized: transformers.BatchEncoding, average: bool = True,) -> List[torch.Tensor]: with torch.no_grad(): output: CausalLMOutputWithPast = model( **tokenized.to(model.device), output_hidden_states=True, return_dict=True ) hidden_states = torch.stack( output.hidden_states[:-1] ) # (num_layers, batch_size, seq_len, hidden_size) if average: hidden_states = hidden_states.sum(dim=2) / hidden_states.shape[2] else: hidden_states = hidden_states[:, :, -1, :] return hidden_states.sum(dim=1) / hidden_states.shape[1]
函数 `get_hidden_states` 用于获取语言模型在不同层对输入文本的隐藏状态表示。函数会根据输入参数决定是返回每层隐藏状态的平均值还是最后一个时间步的隐藏状态。最后,函数会计算所有层的平均,得到每个输入的最终隐藏状态表示!
以上,MoE由浅至深,已经讲得很清楚了!
第二部分:如何创建MoE模型?
方法很多!雄哥只介绍最常用的4种算法!
SLERP》TIES》DARE》Passthrough

2.1 SLERP
球面线性插值 (SLERP) 是一种用于在两个向量之间平滑插值的方法!
保持恒定的变化率,保留矢量所在的球形空间的几何属性!
看不懂没关系,一定保持求真!马上去查,坚持下去!知识面就拓宽!
与传统的线性插值相比,首选 SLERP 有几个原因:
在高维空间,线性插值可以导致插值向量的幅度减小(减小了权重刻度)
此外,权重方向的变化通常代表比变化幅度更有意义的信息(如特征学习和表示)。
SLERP 的实现步骤如下:
① 将输入向量归一化为单位长度
② 使用它们的点积计算这些向量之间的角度。
SLERP 是目前最流行的合并方法,但它仅限于一次仅合并两个模型!
配置示例:
·
·
·
slices: - sources: - model: OpenPipe/mistral-ft-optimized-1218 layer_range: [0, 32] - model: mlabonne/NeuralHermes-2.5-Mistral-7B layer_range: [0, 32]merge_method: slerpbase_model: OpenPipe/mistral-ft-optimized-1218parameters: t: - filter: self_attn value: [0, 0.5, 0.3, 0.7, 1] - filter: mlp value: [1, 0.5, 0.7, 0.3, 0] - value: 0.5dtype: bfloat16
2.2 TIES
旨在有效地将多个特定于任务的模型合并到单个多任务模型中!它解决了模型合并中的两个主要挑战:
·
模型参数中的冗余:它识别并消除特定于任务的模型中的冗余参数。通过关注微调期间所做的更改,确定前 k% 最重要的更改并丢弃其余更改,来实现!
·
参数符号之间的分歧:当不同的模型建议对同一参数进行相反的调整时,就会发生冲突。TIES-Merging 通过创建统一的符号向量来解决这些冲突,该向量表示所有模型中最主要的变化方向。
TIES-合并分为以下三个步骤:
1.
修剪:通过仅保留最重要参数(密度参数)的一小部分并将其余参数重置为零来减少特定于任务的模型中的冗余。
2.
选择符号:通过创建基于累积幅度方面最主要方向(正或负)的统一符号向量来解决不同模型之间的符号冲突。
3.
不相交合并:平均与统一符号向量对齐的参数值,不包括零值。
与SLERP不同,TIES可以一次合并多个模型。
配置示例:
·
·
models: - model: mistralai/Mistral-7B-v0.1 # no parameters necessary for base model - model: OpenPipe/mistral-ft-optimized-1218 parameters: density: 0.5 weight: 0.5 - model: mlabonne/NeuralHermes-2.5-Mistral-7B parameters: density: 0.5 weight: 0.3merge_method: tiesbase_model: mistralai/Mistral-7B-v0.1parameters: normalize: truedtype: float16
2.3 DARE
类似于TIES的方法,但有两个主要区别:
·
修剪:DARE 将微调的权重随机重置为其原始值(基本模型的值)。
·
重新缩放:DARE 重新缩放权重,以保持模型输出的预期大致不变。它将两个(或多个)模型的重新缩放权重添加到具有比例因子的基本模型的权重中。
·
配置示例:
·
·
models: - model: mistralai/Mistral-7B-v0.1 # No parameters necessary for base model - model: samir-fama/SamirGPT-v1 parameters: density: 0.53 weight: 0.4 - model: abacusai/Slerp-CM-mist-dpo parameters: density: 0.53 weight: 0.3 - model: EmbeddedLLM/Mistral-7B-Merge-14-v0.2 parameters: density: 0.53 weight: 0.3merge_method: dare_tiesbase_model: mistralai/Mistral-7B-v0.1parameters: int8_mask: truedtype: bfloat16
2.4 Passthrough
与上面方法,完全不一样!它通过连接来自不同 LLM 的层,它可以生成诡异参数的模型(例如,9B 具有两个 7B 参数模型)
现在这项技术,非常好玩,但它设法创建了令人印象深刻的模型,例如!两个 Llama 120B 模型的 goliath-2 70b。最近发布的 SOLAR-10.7B-v1.0 也使用了同样的想法!
配置示例:
·
·
slices: - sources: - model: OpenPipe/mistral-ft-optimized-1218 layer_range: [0, 32] - sources: - model: mlabonne/NeuralHermes-2.5-Mistral-7B layer_range: [24, 32]merge_method: passthroughdtype: bfloat16
第三部分:跑一个实例!把Llama3和Phi-3组成MoE!
其实,你可以选用自己的模型或者用其他Hugging Face上的其他模型来组合!具体配置,自己去找!建议按以下来选配!也可根据自己任务!
聊天模型:用于大多数交互的通用模型!
代码模型:能够生成良好代码的模型!
数学模型:数学对于LLM来说是棘手的,要一个专门研究数学的模型,要看MMLU + GMS8K分数!
角色扮演模型:该模型的目标是编写高质量的故事和对话!
这次,雄哥为了跑这个示例,选用的是这两个!
cognitivecomputations/dolphin-2.9-llama3-8b
shenzhi-wang/Llama3-8B-Chinese-Chat
当然!如果你自己有做垂直微调!替换!很方便!
建议用Linux,确保兼容!本次雄哥使用wsl系统!
雄哥本地已经搭建了AI环境,如果你还未搭建,在这里搭建!
第四天!0基础微调大模型+知识库,部署在微信!手把手安装AI必备环境!4/45
然后!下载雄哥传到会员盘的代码!价值内容仅会员专享!
如果你还不是知识星球会员,在这里申请加入!我们是一个专注动手学AI的组织,会有工程师始终在你副驾,帮助你学习AI!每月组队学习活动!
先创建一个conda环境吧!
·
conda create -n yiyiai python=3.10
激活并进入环境!
·
conda activate yiyiai
进入刚刚下载的代码目录!
·
cd moe
安装依赖!
·
pip install -q -e .
安装最新版本transformers!
·
pip install -U transformers
本次演示,模型不在雄哥电脑里,所以要去hugging face下载!
这里我们要改一下他的国内镜像源,这样,不用魔法,都可以下载模型!
先安装依赖!
·
pip install -U huggingface_hub
把huggingface的下载源改为国内镜像!
·
export HF_ENDPOINT=https://hf-mirror.com
到这里!一切搞掂!
打开合并的配置文件!
config.yaml
雄哥这里简单讲讲配置文件作用!
·
·
slices: - sources: - model: cognitivecomputations/dolphin-2.9-llama3-8b layer_range: [0, 32] - model: shenzhi-wang/Llama3-8B-Chinese-Chat layer_range: [0, 32] merge_method: slerp base_model: shenzhi-wang/Llama3-8B-Chinese-Chat parameters: t: - filter: self_attn value: [0, 0.5, 0.3, 0.7, 1] - filter: mlp value: [1, 0.5, 0.7, 0.3, 0] - value: 0.5 dtype: bfloat16
1.
slices: 这个部分指定了要使用的模型和模型的层范围。这里列出了两个模型,分别是cognitivecomputations/dolphin-2.9-llama3-8b和shenzhi-wang/Llama3-8B-Chinese-Chat,每个模型都指定了一个层范围[0, 32],意味着只使用每个模型的前32层。
2.
merge_method: 这个部分指定了如何合并slices部分指定的多个模型。这里使用的是slerp方法,即球面线性插值方法。
3.
base_model: 这个部分指定了基础模型,即shenzhi-wang/Llama3-8B-Chinese-Chat。
4.
parameters: 这个部分指定了模型的参数。这里包含了三个参数,分别是self_attn、mlp和一个没有指定名称的参数。每个参数都有一个filter和一个value。filter指定了参数的作用范围,value指定了参数的值。例如,self_attn参数的值是一个列表[0, 0.5, 0.3, 0.7, 1],mlp参数的值是一个列表[1, 0.5, 0.7, 0.3, 0],而没有指定名称的参数的值是0.5。
5.
dtype: 这个部分指定了模型的数据类型,这里是bfloat16,即16位浮点数。
要改其他模型?直接改上面的配置文件!替换成huggingface的路径!
现在!直接运行!他会自动加载配置文件!
·
mergekit-yaml config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle --trust-remote-code

他会自动去下载!
如果你有模型,也可以自己放到这里!会自动调用!
root\.cache\huggingface\hub
没有太多VRAM!要好好修改配置文件,换其他方法创建,这里,雄哥也把说明文件,都上传了!
出自:https://mp.weixin.qq.com/s/AJVIFSt6LA34bsdyXf2jOw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
flomo浮墨笔记,像发微博一样记笔记不仅能帮你快速记录,还能帮你更好回顾。全平台覆盖,还支持微信服务号输入。