中文OCR超越GPT-4V,参数量仅2B,面壁小钢炮拿出了第二弹
发布时间:2024年09月13日
OpenAI后,大模型新增长曲线来了。
大语言模型的效率,正在被这家「清华系」创业公司发展到新高度。

从 ChatGPT 到 Sora,生成式 AI 技术遵从《苦涩的教训》、Scaling Law 和 Emerging properties 的预言一路走来,让我们已经看到了 AGI 的冰山一角,但技术的发展的方向还不尽于此。
最近一段时间,科技公司大力投入生成式 AI,一系列新的概念正在出现:手机厂商认为「AI 手机」正在引领手机形态的第三次转变;PC 厂商认为「AI PC」可能会改变个人电脑的形态;而对于更多科技公司来说,AI 进入 2.0 时代后,所有应用「都应该重写一遍」。
这些改变游戏规则的事物,背后隐含着一个逻辑:AI 大模型需要快速覆盖大量场景。而对于算力有限的端侧而言,优化是重中之重。从应用落地的角度看,轻量级、MoE 大模型已经成为人们重要的探索方向。
面对逐渐增多的生成式 AI 落地需求,「清华系」创业公司面壁智能一直在致力于对语言模型进行优化,使其在同等成本下达到更好的效果。
今年 2 月 1 日,面壁智能发布的第一代 2B 旗舰端侧大模型 MiniCPM,不仅超越了来自「欧洲版 OpenAI」Mistral 的性能标杆之作,同时整体领先于 Google Gemma 2B 量级,还越级超越了一些业内标杆的 7B、13B 量级模型,如 LLaMa2-13B 等。
仅仅 70 天以后,端侧大模型面壁 MiniCPM 小钢炮的第二弹乘胜追击,迎来多模态、长文本、MoE 等领域模型的迭代,主打的就是「小而强,小而全」。
把大模型做小,不止是提高效率
4 月 11 日,面壁智能正式发布了新一代 MiniCPM 系列模型,包括四个模型:
·
OCR 能力惊艳,当前端侧最强多模态模型MiniCPM-V 2.0;
·
·
适配更多端侧场景,仅 1.2B 的基座模型 MiniCPM-1.2B;
·
·
最小的 128K 长文本模型
MiniCPM-2B-128K;
·
·
性能进一步增强的 MoE 架构模型
MiniCPM-MoE-8x2B。
·
oMiniCPM-V 2.0 开源地址:https://github.com/OpenBMB/MiniCPM-V
o小钢炮全家桶系列开源地址:https://github.com/OpenBMB/MiniCPM
o小钢炮全家桶技术 Blog 地址:https://openbmb.vercel.app/?category=Chinese+Blog
这些模型的具体表现如何?我们可以从真实评测数据和实际任务表现两个方面一探究竟。
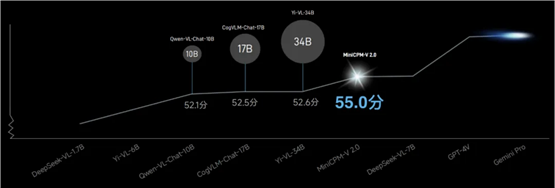
首先是近来各个大模型厂商都极力主推的多模态能力。面壁智能此次发布了能跑在手机上的「最强端侧多模态大模型」MiniCPM-V 2.0,参数规模仅为 2.8B,但在与参数远超自己的竞品模型较量中实现越级胜出。
其中在 OpenCompass 榜单中,综合 11 个主流评测基准的结果表明,MiniCPM-V 2.0 的通用多模态能力超越了 Qwen-VL-Chat-10B、CogVLM-Chat-17B 和 Yi-VL-34B,让我们看到了「小身板也能蕴藏强大能力」。
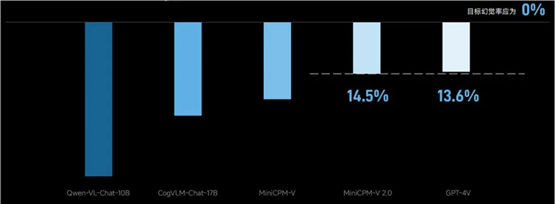
模型通用能力越强,意味着幻觉水平越低,事实准确性越高。因此,MiniCPM-V 2.0 大大降低了自身幻觉水平。
在评估大模型幻觉的 Object HalBench 榜单中,幻觉水平与 GPT-4V 持平(见图上)。下面是实测的一次看图说话任务,MiniCPM-V 2.0
出现了 3 处幻觉,GPT-4V 出现了 6 处幻觉(见图下高亮红字):

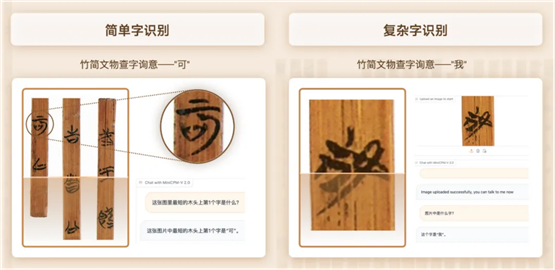
除了越来越强大的通用能力,在 OCR(光学字符识别)这一多模态识别与推理能力的硬性指标上,MiniCPM-V 2.0 更有亮眼的表现,在精准识别图片中物体的同时,对包括古文字在内的文字符号的识别迎来了史诗级加强。
比如让该模型识别清华大学收藏的「清华简」竹简上的古文字,它轻松搞定了简单字(下图左)和复杂字(下图右)的识别。
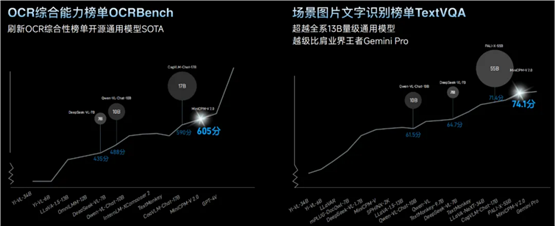
此外,MiniCPM-V 2.0 在 OCR 综合能力榜单 OCRBench 上刷新开源模型 SOTA 表现;还在场景图片文字识别榜单 TextVQA 上超越全系 13B 量级通用模型,其中文字理解表现越级比肩了业界王者谷歌 Gemini Pro,让我们惊叹它的进化之快。
评测数据如此之强,让
MiniCPM-V 2.0 面对一系列 OCR 场景经典难题时毫无压力。传统大模型只能处理 448×448 像素固定的小图,对于包含海量信息的更精细图片识别则力有不逮。对于构图繁复、细节丰富的街景识别,MiniCPM-V 2.0 模型抓全景、抓细节、抓重点的能力显然更胜一筹。

此外还有传统大模型往往表现不佳的长图识别,其中包含的大量文本信息对模型构成了巨大挑战。而 MiniCPM-V
2.0 能够更稳、更准地捕获长图重点信息,进行摘要总结,这是之前的模型无法做到的。

当然,在中文 OCR 场景任务的表现上,MiniCPM-V
2.0 超越了 GPT-4V,能后者之所不能。

面壁智能将「小」做到极致,推出了一款体量更小的模型 ——MiniCPM-1.2B,号称「小小钢炮」。模型参数虽然较上一代
2.4B 模型减少了一半,但仍保留了其 87% 的综合性能。
同样用数据说话,在 C-Eval、CMMLU、MMLU 等多个公开权威评测榜单上,综合性能越级超越了 Qwen1.8 B、LLaMa2-7B 甚至是 LLaMa2-13B,展现出了更小模型击败大模型的巨大潜力。
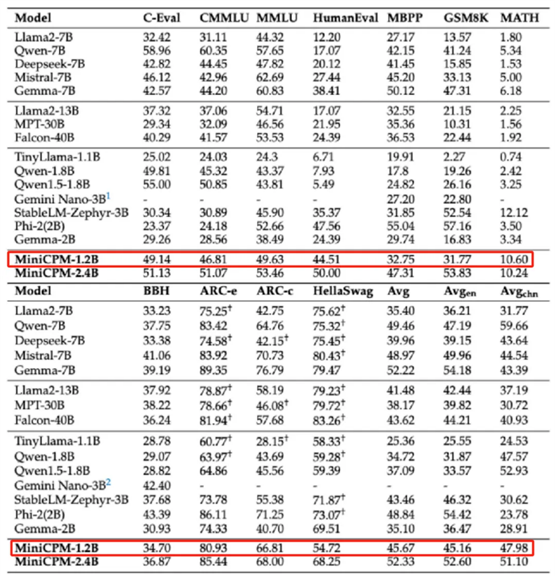
更小参数意味着更有利于手机等端侧设备上部署和运行。活动现场,面壁智能演示了 MiniCPM-1.2B 在 iPhone 15 上流畅的运行效果,推理速度提升 38%,达到了 25 token/s,是人说话速度的 15 到 25 倍。
当然,模型尺寸减小不仅有利于端侧落地,内存成本也得到显著降低。在 iOS 系统端,MiniCPM-1.2B 的内存用量(1.01G)比 MiniCPM-2.4B 量化模型(2.1G)减少了 51.9%,折算成本下降了 60%(1
元 = 4150000 tokens)。
1.2B 的体量让语言模型的应用范围不在仅限于旗舰手机,极致的优化让模型的体量更小,使用场景却大大增多了。尤其对于想要在端侧部署大模型的手机厂商来说,MiniCPM-1.2B 是个不错的选择。
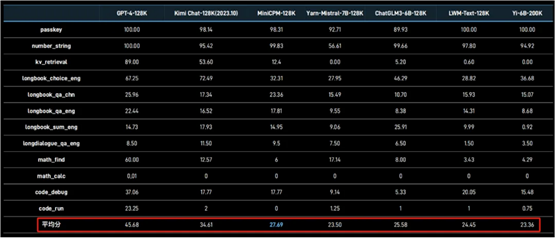
MiniCPM「小钢炮」同样强化了长文本理解能力。此次推出的 MiniCPM-2B-128K 成为了支持 128K 上下文窗口的最小体量模型。
其中在 InfiniteBench 榜单的平均成绩较量中,MiniCPM-2B-128K
以 2B 的「小身躯」超越一众 6B、7B 量级模型,比如 Yi-6B-200K、Yarn-Mistral-7B-128K,实实在在做到了「量小质高」。
关于长文本模型的下一步探索方向,面壁智能表示,同样会在端侧的部署和运行上发力。
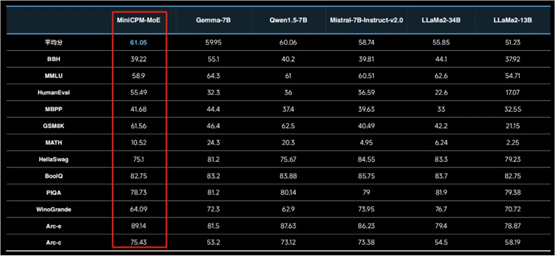
多模态和长文本保证了 MiniCPM 模型能力的基本盘,而混合专家模型(MoE)架构的引入让该系列模型的能力更上一层楼。全新 MiniCPM-MoE-8x2B 模型将第一代 2B 模型的平均性能提升了 4.5 个百分点,并且相较于完全从头开始训练,训练成本大大降低。
该模型的平均激活参数虽然只有 4B,但在 BBH、MMLU 等 12 个权威评测基准上的平均成绩取得了第一,甚至击败了 LLaMa-34B,而推理成本仅仅为 Gemma-7B 的 69.7%。
至此,面壁智能将覆盖多模态、长文本、MoE 架构的新四「小」模型一一铺开,充分挖掘小体量大模型的全方位能力,在一众更大参数规模的竞品模型中成功突围。
能力突围背后,藏着一系列独门技术
今年 2 月 MiniCPM 第一代的发布会上,面壁智能联合创始人刘知远曾表示:「我们会在春节之后不断发布 MiniCPM 的新版本,性能还会进一步提升。我们要给大家春节的休息时间。」几十天后,面壁智能果然拿出了亮眼的成绩。
当然,这一切离不开面壁智能厚积薄发的独门技术实力。
先以 MiniCPM-V 2.0 展现的超强多模态能力来说,该模型面对一系列 OCR 场景的经典难题都给出对应的高效技术解决方案。
比如上文展示的更精细图片识别和长图识别,都要得益于高清图片、高效编码和任意宽高比图像无损识别,使得对小物体和光学字符等细腻视觉信息的感知能力大大增强,可以处理最大 180 万像素高清大图,甚至 1:9 极限宽高比的高清图片,对它们进行高效编码和无损识别。
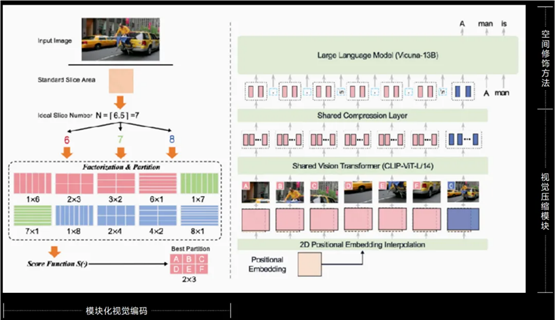
做到这些靠的是面壁智能的一项独门技术 —— LLaVA-UHD,它包含了三大重要组件,即模块化视觉编码、视觉压缩模块和空间修饰方法,它们发挥的作用分别如下:
·
模块化视觉编码负责将原始分辨率图像划分为可变大小切片,并且无需像素填充或图像变形即可实现对原始分辨率的完全适应;
·
·
视觉压缩模块使用共享感知器重采样层压缩图像切片的视觉 tokens,无论分辨率多少 token 数量皆可负担,计算量更低的同时支持任意宽高比图像编码;
·
·
空间修饰方法则使用自然语言符号的简单模式,有效告知图像切片的相对位置。
·
三位一体、相辅相成,让高清图像、高效编码成为可能。
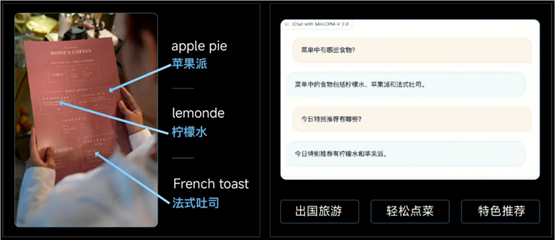
此外,MiniCPM-V 2.0 还具备了独家的跨语言多模态泛化技术,让大模型可以用中文解读英文菜单并给出推荐。
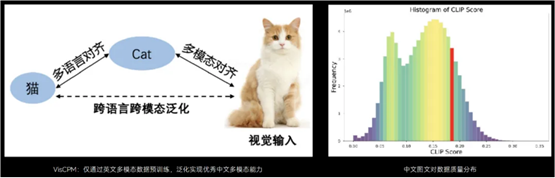
不仅如此,跨模态跨语言泛化技术还解决了中文领域缺乏高质量、大规模多模态数据的挑战。团队提出的 VisCPM 可以通过英文多模态数据的预训练,进而泛化实现优秀的中文多模态能力。
VisCPM 论文地址:https://arxiv.org/pdf/2308.12038.pdf
与此同时,在 MiniCPM-2B-128K 上,团队通过多阶段训练方法,在训练过程中使用课程学习、动态调整数据配比等技术,组合使用多种长文本扩展方式,成功将模型的上下文长度扩展至 128K。这一过程既提高了训练效率,又尽可能减少了对短文本处理性能的损失。面壁智能表示,未来还将进一步扩展模型的上下文长度。
MiniCPM-MoE-8x2B 模型采用了最前沿的 MoE (混合专家模型)架构,这一架构能在不增加推理成本的情况下为大模型带来性能激增。
MiniCPM-MoE-8x2B 模型总共包含 8 个 expert,全参数量(non-embedding)为 13.6B,每个 token 激活其中的 2 个
expert,激活参数量(non-embedding)为 4B。
掌握新的
Scaling Law
在众多投身大语言模型的创业公司中,专注于「小模型」方向的面壁智能,早已总结出了自己的一套打法。
2020 年,OpenAI 一篇论文《Scaling Laws for Neural Language Models》对于
transformers 架构的大模型表现与训练时间、上下文长度、数据集大小、模型参数量和计算量的关系进行了讨论。其提出模型的表现与规模存在强相关,这就是「Scaling Law」。
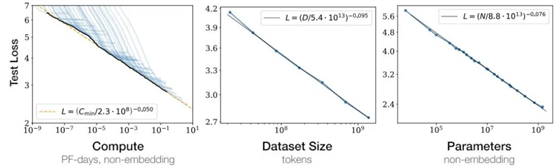
随着我们增加模型体量、数据集大小和训练算力,语言建模的性能平稳提高。为了获得最佳性能,所有三个因素必须同时扩大。当其中一个因素受限时,模型表现随另外一个因素增加变好,但效果会逐渐衰减。(图片来自 OpenAI)
随着之后 GPT-3、GPT-4 的推出,OpenAI 遵循着这样的规律进行探索,为生成式 AI 带来了突破性的进展。众多科技公司、创业公司也纷纷入局,投入构建千亿级,甚至万亿级参数大模型的行列中。
但在大模型的世界中,参数量大,并不一定等于性能更好。今年 3 月 17 日,马斯克的 xAI 正式开源了
3140 亿参数的混合专家(MoE)大模型 Grok-1,成为了当前参数量最大的开源大语言模型。然而仅过去不到两个星期,Databricks 开源的 1320 亿参数通用大模型 DBRX 就在多个基准上打败了它。
今年初的 AI 顶会 ICLR 2024 上,面壁智能等机构被接收的论文《Predicting Emergent Abilities with Infinite Resolution Evaluation》引发了人们对 Scaling Law 的新理解。

在这项研究中,研究人员发现小模型虽然性能有限,但表现出关键且有一致性的任务性能改进趋势,而由于测量分辨率不足,传统的评估策略无法捕获这些改进。在新的评估策略支持下,人们发现了一种加速涌现,其标度曲线不能用标准标度律函数拟合,并且具有递增的速度。
面壁智能 CTO 曾国洋表示,其团队从 2020 年 GPT-3 发布后开始训练大模型,逐渐认识到「提升模型效果是大模型训练的根本目标,但这并不意味着一定要通过扩大参数量规模和燃烧高昂的算力成本来实现。」相反,让每一个参数发挥最大作用,在同等参数量上实现更好的性能,才是解决大模型效率问题的核心。
面壁智能的语言模型探索,也是一直围绕着小体量、高性能的目标展开的。
今年 2 月发布的「性能小钢炮」MiniCPM,作为全球领先的轻量高性能大模型,标志着面壁大模型高效训练模式的彻底跑通。独特的面壁「模型沙盒实验」,通过对大模型训练过程进行环境建、并对最佳模型训练结果进行精准模拟预测,成功打造出高效 Scaling Law 曲线 —— 同等参数量条件下性能更优、同等性能情况下参数更小。
2 月发布的
MiniCPM 2B 在更小参数量的基础上可以实现媲美 Mistral-7B 的性能,进一步验证了其「低参数、高性能」的方法论。
而在最近,面壁智能的技术已经可以做到把中文 OCR 水平媲美
GPT-4V 的模型塞进手机,新 Scaling Law 的路线已经逐渐清晰。
面壁智能在探索「高效」这件事的过程中,以源源不断的世界级前瞻研究成果,布局了贯彻高效训练、高效落地与高效推理的大模型全栈技术生产线。
从清华自然语言处理实验室(THUNLP)走来,务实,但专注于有引领性方向的研究,是面壁大模型团队的标签。
实际上,这个团队多年来对于 AI 技术路线作出了很多次精准的预言式判断:从 2018 年投入 BERT 技术路线,2020
年率先拥抱大模型,2023 年初对 AI 智能体(Agent)的超前探索,千亿多模态大模型 CPM-Cricket 的发布,再到对大模型端云协同的前瞻布局。在竞争激烈的生成式 AI 领域,面壁超前的 Al 技术研判策略,逐渐收获了业内的认知与认同。
结语
目前,面壁智能已经组建起 100 余人的科研团队,其中 80%
人才来自清北,平均年龄 28 岁。
MiniCPM 新的探索,也在引领大模型领域的下一阶段发展。如果从效率的角度来看,面壁或许会是速度更快的那一个。
在昨天的发布会上,面壁智能正式宣布完成了新一轮数亿元人民币的融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。新一轮融资,将被用于加快推动大模型的高效训练、快步应用落地。
面壁把大模型做小,不仅是为了端侧的快速落地:通过 MiniCPM 系列模型 等工作,能够实现 AGI 的通用基座大模型已有了更深厚的基础。基于 Scaling Law 的科学方法论,通过把大模型做小验证出高效大模型的框架,更加强大的 AI 正在路上。
出自:https://mp.weixin.qq.com/s/WPsU5lprg0JSvdBVmMx_Vg
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Voice.AI,实时AI变声工具。