腾讯出品!开源AI数字人框架!号称可以不限时长
发布时间:2024年09月15日
如今数字媒体和虚拟现实技术飞速发展,对数字人的需求不断增加!
今天,介绍一个开源创新的虚拟人视频生成框架:MuseV
MuseV是由腾讯音乐娱乐的天琴实验室开源,MuseV专注于生成高质量的虚拟人视频和口型同步,能够制作出具有高度一致性和自然表情的长视频内容。据说可以不限时长!
话不多说,我们先看看效果!下面是由图片生成的数字人视频
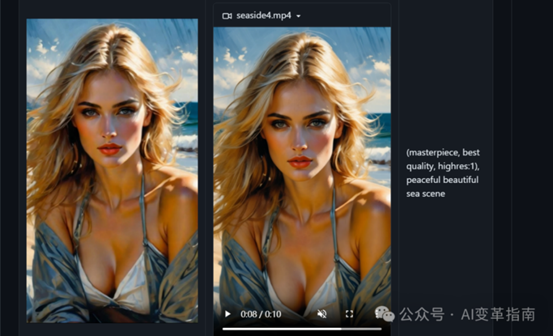
下面是生成效果
,时长00:06
,时长00:10
,时长00:10
,时长00:09
,时长00:39
技术亮点
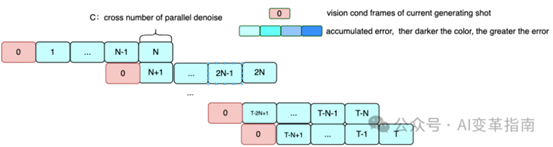
无限视频长度:MuseV采用了视觉条件并行去噪方案,支持生成理论上无限长度的视频。
多样化生成方式:支持从图像到视频、文本到图像到视频、视频到视频的多种生成方式。
稳定扩散生态系统兼容:与基础模型、lora、controlnet等稳定扩散生态系统兼容,增强了用户的创作自由度。
多参考图像技术:支持IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID等多参考图像技术,提升了视频生成的质量和多样性1。
如何做到的?
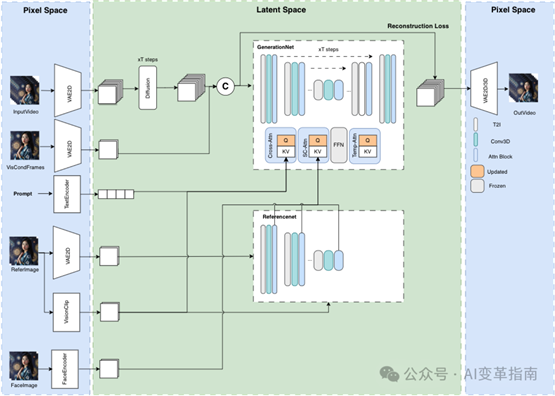
MuseV利用了一种新颖的视觉条件并行去噪方案,支持无限长度的视频生成。这意味着理论上,MuseV可以生成任意长度的视频,而不受传统技术限制。它还提供了在人类数据集上训练的检查点,支持从图像到视频、文本到图像到视频、视频到视频的多样化生成方式。
下面是模型结构示意图
下面是并行去噪算法示意图
MuseTalk:实时高质量口型同步模型
值得一提的是,MuseV团队最近发布了MuseTalk,这是一个实时高质量的口型同步模型,可以与MuseV结合使用,提供完整的虚拟人生成解决方案。
如何使用?
准备 Python 环境并安装额外的包,如 diffusers、controlnet_aux、mmcm。然后按照下图所示,自行安装部署。
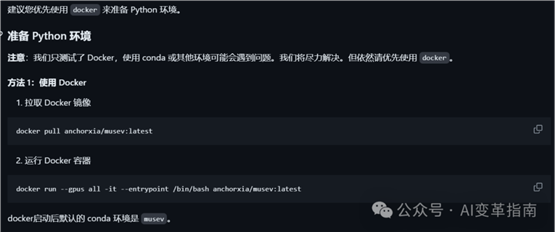
MuseV不仅仅是一个技术产品,它代表了虚拟人技术的未来方向。随着技术的不断进步,我们有理由相信,MuseV将在娱乐、教育、会议等多个领域发挥重要作用,为我们带来更加丰富和真实的虚拟体验。
项目地址:
https://github.com/TMElyralab/MuseV
AI变革往期回顾:
0、【零基础入门AI】ChatGPT4.0+机器学习+深度学习!一站式掌握科研利器!助力论文写作、数据分析、科研使用!
1、让照片变逼真的真人视频!腾讯推出开源AI框架:AniPortrait
2、开源、可本地部署的AI知识问答库来了!有道出品:QAnything
3、输入文本生成网页!一个开源的AI网页生成项目: OpenUI
5、想一想,就能生成图片!Stability
AI 推出 MindEye
6、一张照片!生成逼真的3D头像!头发丝都能看清!Meta推出RGCA技术
7、目前世界最好的小语言AI模型:Phi-2!可部署在手机使用!
8、AnyText:一种能够生成和编辑多语言文本图像的神奇模型
9、通过声音生成逼真的全身形象?!Meta开源AI工具:audio2photoreal
10、AI“同声传译”新进展!Google发布,无监督,语音识别:Translatotron 3!
11、火爆全网!斯坦福研究了一个能做家务的机器人!叠被子、煎牛排、扫地都不在话下!
12、AI视频生成王炸更新!Pika和Runway的强大对手来了!一个可通过文字生成视频的AI模型:DynamiCrafter
好了,今天的内容就分享到这里希望你们喜欢!
出自:https://mp.weixin.qq.com/s/auACBlvwpjl54fGeKsB3mA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
谷灵AI,能够提升你的写作效率和创作灵感,专业提供各种AI应用,包括:AI聊天,AI文案创作,AI编程,AI写简历,AI写剧本,AI翻译。