LlamaIndex的QueryPipeline在实现RAG应用后,Agent应用也可以实现了(附开发示例)
发布时间:2024年10月30日
在前面文章《应用编排的未来是Pipeline,LlamaIndex开发预览版推出Query Pipeline,提升应用开发的灵活性》里,我们提到了llamaindex出了一个新的实验feature,支持通过声明式的方式定义QueryPipeline从而形成个性化的应用流程,并且给出了对于RAG类应用的实现案例。
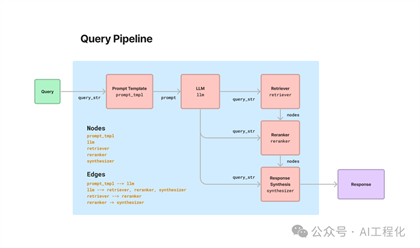
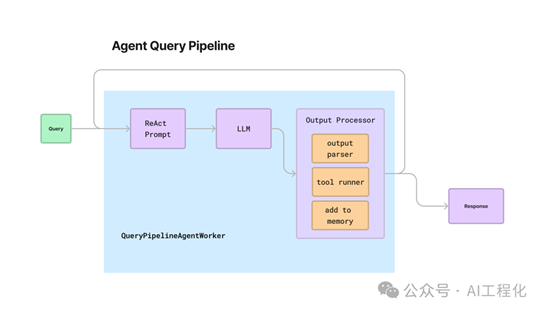
那么,Agent应用可以通过QueryPipeline的方式实现吗?如果可以,它将能统一整个应用的构建模式,对于开发者来讲,会带来一致的开发体验。这个答案是肯定的,最近官方放出了一个通过QueryPipeline构建ReAct Agent示例。实际上,实现思路很直接,就是定义了AgentWorker(类似于langchain的AgentExecutor的实现,支持ReAct模式的循环)在其上实现了一些Agent特有的组件,进而基于此实现了AgentPipeline,但langchain现在已经发现了这样设计在生产条件下的限制,推出了langgraph。
延伸阅读:LangChain 0.1.0版本正式发布,One More Thing将成了Agent落地生产的福音
本文以官方提供的“Text2SQL的ReAct Agent”为例来了解基本的开发过程。
1.导入数据,构建待查询的数据库。
·
!curl "https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip" -O ./chinook.zip!unzip ./chinook.zip
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed
100 298k 100 298k 0 0 2327k 0 --:--:-- --:--:-- --:--:-- 2387k
curl: (6) Could not resolve host: .
Archive: ./chinook.zip
inflating: chinook.db
from llama_index import SQLDatabase
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
select,
column,
)
engine = create_engine("sqlite:///chinook.db")
sql_database = SQLDatabase(engine)
2.安装可观测性工具,官方推荐使用Arize Phoenix。
·
# setup Arize Phoenix for logging/observability
import phoenix as px
import llama_index
px.launch_app()
llama_index.set_global_handler("arize_phoenix")
To view the Phoenix app in your browser, visit http://127.0.0.1:6006/
To view the Phoenix app in a notebook, run `px.active_session().view()`
For more information on how to use Phoenix, check out https://docs.arize.com/phoenix
3.构建Text2SQL工具。
·
from llama_index.query_engine import NLSQLTableQueryEngine
from llama_index.tools.query_engine import QueryEngineTool
sql_query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["albums", "tracks", "artists"],
verbose=True,
)
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
name="sql_tool",
description=(
"Useful for translating a natural language query into a SQL query"
),
)
4.构建ReAct Agent Pipeline,这是整个构建过程的关键。整个执行过程分为四步:
a)获取Agent输入b)利用ReAct Prompt 调用 LLM 生成下一个操作/工具(或返回响应)。c)如果LLM选择了工具/操作,则调用Tool Pipeline来执行工具 并收集工具执行的结果。d)直到Pipeline最终生成返回结果。在整个过程在QueryPipelineAgentWorker中执行(循环能力,未来可能会开放自定义,如LangGraph)。
·
#QueryPipelineAgentWorker的部分实现
def _get_task_step_response(
self, agent_response: AGENT_CHAT_RESPONSE_TYPE, step: TaskStep, is_done: bool
) -> TaskStepOutput:
"""Get task step response."""
if is_done:
new_steps = []
else:
new_steps = [
step.get_next_step(
step_id=str(uuid.uuid4()),
# NOTE: input is unused
input=None,
)
]
return TaskStepOutput(
output=agent_response,
task_step=step,
is_last=is_done,
next_steps=new_steps,
)
下面是一些构建Agent会用到的专门组件:
·AgentInputComponent 允许将Agent输入(任务、状态字典)转换为一组查询管道输入。
·AgentFnComponent:一个通用处理器,允许您获取当前任务、状态以及任何任意输入,并返回输出。在这个例子中,定义了一个函数组件来格式化 ReAct 提示。当然,也可以在任何地方放置它。
·CustomAgentComponent:类似于 AgentFnComponent,可以实现 _run_component 来定义自己的逻辑,并访问任务和状态。它比
AgentFnComponent 更复杂,但更灵活(例如,可以定义初始化变量,并且回调位于基类中)。请注意,传递给 AgentFnComponent 和 AgentInputComponent 的任何函数都必须包含任务和状态作为输入变量,因为这些是Ageent传递的输入。
另外,AgentQueryPipeline的输出必须是 Tuple[AgentChatResponse, bool]。
1)定义AgentInputComponent。在每个Agent步骤的开始调用。除了传递输入之外,还执行初始化/状态修改。
·
from llama_index.agent.react.types import (
ActionReasoningStep,
ObservationReasoningStep,
ResponseReasoningStep,
)
from llama_index.agent import Task, AgentChatResponse
from llama_index.query_pipeline import (
AgentInputComponent,
AgentFnComponent,
CustomAgentComponent,
ToolRunnerComponent,
QueryComponent,
)from llama_index.llms import MessageRole
from typing import Dict, Any, Optional, Tuple, List, cast
## Agent Input Component
## This is the component that produces agent inputs to the rest of the components
## Can also put initialization logic here.
def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict[str, Any]:
"""Agent input function.
Returns:
A Dictionary of output keys and values. If you are specifying
src_key when defining links between this component and other
components, make sure the src_key matches the specified output_key.
""" # initialize current_reasoning
if "current_reasoning" not in state:
state["current_reasoning"] = []
reasoning_step = ObservationReasoningStep(observation=task.input) state["current_reasoning"].append(reasoning_step)
return {"input": task.input}
agent_input_component = AgentInputComponent(fn=agent_input_fn)
2)定义Agent Prompt。定义可生成 ReAct 提示的Agent组件,并在
LLM 生成的输出后,将其解析到结构化对象中。
·
from llama_index.agent.react.formatter import ReActChatFormatter
from llama_index.query_pipeline import InputComponent, Link
from llama_index.llms import ChatMessage
from llama_index.tools import BaseTool
## define prompt function
def react_prompt_fn(
task: Task, state: Dict[str, Any], input: str, tools: List[BaseTool]) -> List[ChatMessage]:
# Add input to reasoning
chat_formatter = ReActChatFormatter()
return chat_formatter.format(
tools,
chat_history=task.memory.get() + state["memory"].get_all(), current_reasoning=state["current_reasoning"],
)
react_prompt_component = AgentFnComponent(
fn=react_prompt_fn, partial_dict={"tools": [sql_tool]}
)
3)定义Agent Output Parser 及 Tool Pipeline。Agent Output Parser整个处理过程简单归纳为两种情况。即:
·如果LLM给出了最终答案,那么只需要处理输出即可。
·如果LLM给出了工具操作,需要使用指定参数执行指定的工具,然后处理输出。
工具调用可以利用ToolRunnerComponent
模块来完成。它接收一个工具列表,并且可以使用指定的工具名称(每个工具都有一个名称)和工具操作来“执行”。它实际上是CustomAgentComponent的特定实现。同时也实现了 sub_query_components
来将更高级别的回调管理器传递给工具运行器子模块。
·
from typing import Set, Optional
from llama_index.agent.react.output_parser import ReActOutputParser
## Agent Output Component## Process reasoning step/tool outputs, and return agent responsedef finalize_fn( task: Task, state: Dict[str, Any], reasoning_step: Any, is_done: bool = False, tool_output: Optional[Any] = None,) -> Tuple[AgentChatResponse, bool]: """Finalize function.
Here we take the latest reasoning step, and a tool output (if provided), and return the agent output (and decide if agent is done).
This function returns an `AgentChatResponse` and `is_done` tuple. and is the last component of the query pipeline. This is the expected return type for any query pipeline passed to `QueryPipelineAgentWorker`.
""" current_reasoning = state["current_reasoning"] current_reasoning.append(reasoning_step) # if tool_output is not None, add to current reasoning if tool_output is not None: observation_step = ObservationReasoningStep( observation=str(tool_output) ) current_reasoning.append(observation_step) if isinstance(current_reasoning[-1], ResponseReasoningStep): response_step = cast(ResponseReasoningStep, current_reasoning[-1]) response_str = response_step.response else: response_str = current_reasoning[-1].get_content()
# if is_done, add to memory # NOTE: memory is a reserved keyword in `state`, but you can add your own too if is_done: state["memory"].put( ChatMessage(content=task.input, role=MessageRole.USER) ) state["memory"].put( ChatMessage(content=response_str, role=MessageRole.ASSISTANT) )
return AgentChatResponse(response=response_str), is_done
class OutputAgentComponent(CustomAgentComponent): """Output agent component."""
tool_runner_component: ToolRunnerComponent output_parser: ReActOutputParser
def __init__(self, tools, **kwargs): tool_runner_component = ToolRunnerComponent(tools) super().__init__( tool_runner_component=tool_runner_component, output_parser=ReActOutputParser(), **kwargs )
def _run_component(self, **kwargs: Any) -> Any: """Run component.""" chat_response = kwargs["chat_response"] task = kwargs["task"] state = kwargs["state"] reasoning_step = self.output_parser.parse( chat_response.message.content ) if reasoning_step.is_done: return { "output": finalize_fn( task, state, reasoning_step, is_done=True ) } else: tool_output = self.tool_runner_component.run_component( tool_name=reasoning_step.action, tool_input=reasoning_step.action_input, ) return { "output": finalize_fn( task, state, reasoning_step, is_done=False, tool_output=tool_output, ) }
@property def _input_keys(self) -> Set[str]: return {"chat_response"}
@property def _optional_input_keys(self) -> Set[str]: return {"is_done", "tool_output"}
@property def _output_keys(self) -> Set[str]: return {"output"}
@property def sub_query_components(self) -> List[QueryComponent]: return [self.tool_runner_component]
react_output_component = OutputAgentComponent([sql_tool])
4)构建Pipeline流程,形成agent_input -> react_prompt -> llm -> react_output这样执行流程,注:对于简单的顺序流程,在QueryPipeline中可以直接写为Chain的形式。
·
from llama_index.query_pipeline import QueryPipeline as QPfrom llama_index.llms import OpenAI
qp = QP( modules={ "agent_input": agent_input_component, "react_prompt": react_prompt_component, "llm": OpenAI(model="gpt-4-1106-preview"), "react_output": react_output_component, }, verbose=True,)qp.add_chain(["agent_input", "react_prompt", "llm", "react_output"])
这里还可以使用pyvis来可视化Pipeline拓扑。
·
rom pyvis.network import Network
net = Network(notebook=True, cdn_resources="in_line", directed=True)net.from_nx(qp.dag)net.show("agent_dag.html")
5)装载pipeline。
·
from llama_index.agent import QueryPipelineAgentWorker, AgentRunnerfrom llama_index.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)agent = AgentRunner(agent_worker, callback_manager=CallbackManager([]))
6)运行Pipeline。
·
# start tasktask = agent.create_task( "What are some tracks from the artist AC/DC? Limit it to 3")
step_output = agent.run_step(task.task_id) #单步输出
step_output.is_last #检查是否完成
response = agent.finalize_response(task.task_id)print(str(response))
The top 3 tracks by AC/DC are "For Those About To Rock (We Salute You)", "Put The Finger On You", and "Let's Get It Up".
另外,官方还给了一个简化实现,无需选择工具,直接执行text2sql,并支持根据正确性多次重试生成的Agent Pipeline。
1.构造Pipeline。
·
from llama_index.llms import OpenAI
# llm = OpenAI(model="gpt-3.5-turbo")llm = OpenAI(model="gpt-4-1106-preview")from llama_index.agent import Task, AgentChatResponsefrom typing import Dict, Anyfrom llama_index.query_pipeline import AgentInputComponent, AgentFnComponent
def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict: """Agent input function.""" # initialize current_reasoning if "convo_history" not in state: state["convo_history"] = [] state["count"] = 0 state["convo_history"].append(f"User: {task.input}") convo_history_str = "\n".join(state["convo_history"]) or "None" return {"input": task.input, "convo_history": convo_history_str}
agent_input_component = AgentInputComponent(fn=agent_input_fn)from llama_index.prompts import PromptTemplate
retry_prompt_str = """\You are trying to generate a proper natural language query given a user input.
This query will then be interpreted by a downstream text-to-SQL agent whichwill convert the query to a SQL statement. If the agent triggers an error,then that will be reflected in the current conversation history (see below).
If the conversation history is None, use the user input. If its not None,generate a new SQL query that avoids the problems of the previous SQL query.
Input: {input}Convo history (failed attempts): {convo_history}
New input: """retry_prompt = PromptTemplate(retry_prompt_str)from llama_index.response import Responsefrom typing import Tuple
validate_prompt_str = """\Given the user query, validate whether the inferred SQL query and response from executing the query is correct and answers the query.
Answer with YES or NO.
Query: {input}Inferred SQL query: {sql_query}SQL Response: {sql_response}
Result: """validate_prompt = PromptTemplate(validate_prompt_str)
MAX_ITER = 3
def agent_output_fn( task: Task, state: Dict[str, Any], output: Response) -> Tuple[AgentChatResponse, bool]: """Agent output component.""" print(f"> Inferred SQL Query: {output.metadata['sql_query']}") print(f"> SQL Response: {str(output)}") state["convo_history"].append( f"Assistant (inferred SQL query): {output.metadata['sql_query']}" ) state["convo_history"].append(f"Assistant (response): {str(output)}")
# run a mini chain to get response validate_prompt_partial = validate_prompt.as_query_component( partial={ "sql_query": output.metadata["sql_query"], "sql_response": str(output), } ) qp = QP(chain=[validate_prompt_partial, llm]) validate_output = qp.run(input=task.input)
state["count"] += 1 is_done = False if state["count"] >= MAX_ITER: is_done = True if "YES" in validate_output.message.content: is_done = True
return AgentChatResponse(response=str(output)), is_done
agent_output_component = AgentFnComponent(fn=agent_output_fn)from llama_index.query_pipeline import ( QueryPipeline as QP, Link, InputComponent,)
qp = QP( modules={ "input": agent_input_component, "retry_prompt": retry_prompt, "llm": llm, "sql_query_engine": sql_query_engine, "output_component": agent_output_component, }, verbose=True,)qp.add_link("input", "retry_prompt", src_key="input", dest_key="input")qp.add_link( "input", "retry_prompt", src_key="convo_history", dest_key="convo_history")qp.add_chain(["retry_prompt", "llm", "sql_query_engine", "output_component"])
2.装载执行:
·
from llama_index.agent import QueryPipelineAgentWorker, AgentRunner
from llama_index.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)
agent = AgentRunner(agent_worker, callback_manager=CallbackManager([]))
response = agent.chat(
"How many albums did the artist who wrote 'Restless and Wild' release? (answer should be non-zero)?"
)
print(str(response))
小结
由于该特性仍处于研发预览状态,无官方详细的解读,单从案例看,当前对于自定义流程的Agent实现上尚存在一定的限制,这将是其改进的方向,进而实现复杂的Agent应用模式。另一方面,受限于AgentWorker的设计,Agent与RAG混排可能也是未来值得官方改进的方向。
参考:https://github.com/run-llama/llama_index/blob/main/docs/examples/agent/agent_runner/query_pipeline_agent.ipynb
出自:https://mp.weixin.qq.com/s/VvdtEgX_9SoO1W0aY7TRGg
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Postme 是一款强大的AI写作工具,它可以帮助您轻松生成原创、优质并且SEO友好的英文内容,让您摆脱繁琐的写作工作,专注于营销策划和推广。