GLM-4-Voice 9B——实时多语言语音对话 AI——几分钟内即可在本地安装
发布时间:2024年11月18日
如何设置
GLM-4-Voice 9B 以实现无缝的实时语音交互,支持英语和中文,并探索其独特的架构、低延迟响应和可定制的声音属性。

介绍
近年来,语音启用的人工智能取得了显著进展,使对话代理能够更好地理解和响应人类语言。从虚拟助手到客户服务机器人,语音人工智能已成为各个行业的重要工具。然而,大多数模型在流利地切换语言、理解口语查询的细微差别以及提供高质量响应方面仍然面临挑战。这正是Zhipu AI的GLM-4-Voice脱颖而出的地方。GLM-4-Voice作为一款端到端的语音模型,推动了多语言对话人工智能的边界,支持英语和中文的实时对话,同时提供可适应且类人化的响应生成。
在本文中,我们将探讨为什么GLM-4-Voice值得关注,它的独特之处,以及如何在本地设置和开始使用它。我们还将查看其架构,并提供访问网络演示的实用指南。
为什么选择 GLM-4-Voice?
传统的语言模型通常仅限于文本,并需要额外的处理层来处理语音。它们在交互性方面可能会遇到困难,或者存在延迟问题。GLM-4-Voice 通过一个统一的模型克服了这些限制,能够直接处理和生成语音。以下是它的突出之处:
1.端到端语音处理:与许多依赖于单独的文本到语音 (TTS)
或语音到文本 (STT) 模块的模型不同,GLM-4-Voice
直接以口语形式进行解读和响应,从而提供更无缝和更具响应性的体验。
2.多语言支持:该模型在处理英语和中文这两种全球广泛使用的语言方面表现出色。它流畅切换语言的能力使其非常适合双语环境和国际应用。
3.可定制属性:GLM-4-Voice 允许在情感、语调、语速甚至方言上进行调整,使其能够生成更自然和情境合适的响应。
4.低延迟:通过支持流式推理,该模型的延迟约为 20 个标记,使其能够在实时对话中实现近乎即时的响应。
GLM-4-Voice的特点
GLM-4-Voice的特点带来了几个独特的功能,使其与其他语音模型区别开来。以下是它的特别之处:
·实时语音互动:通过支持低延迟响应,GLM-4-Voice
能够保持流畅自然的对话,这对客户支持和互动 AI 等应用至关重要。
·动态语音属性:用户可以指定模型的情感语调、语速和其他特征,使互动更加生动且适合各种场景。
·具备上下文意识的双语支持:该模型旨在理解和生成中文和英文的响应。它能够无缝切换这两种语言,为多语言应用提供灵活的解决方案。
·高级语音解码:基于
CosyVoice,GLM-4-Voice 解码器能够实现高质量的语音生成,并支持流式传输,在两种语言中保持高清晰度。
架构
GLM-4-Voice
的架构由三个主要组件组成,每个组件在实现端到端语音交互中发挥着至关重要的作用:
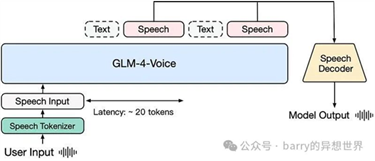
1.GLM-4-Voice-Tokenizer:该组件将连续语音输入标记化为离散标记,每秒大约生成
12.5 个标记。标记器基于 Whisper 的编码器,并添加了向量量化,使模型能够以结构化形式处理音频。
2.GLM-4-Voice-9B:核心语言模型,基于
GLM-4 架构,已调整为处理口语输入。它可以处理文本和语音,使其成为强大的多模态对话代理。
3.GLM-4-Voice-Decoder:该解码器将离散标记转换回连续语音,使模型能够生成音频输出。它支持流式推理,使响应能够在处理几个标记后立即开始,从而最小化对话延迟。
这些组件共同使 GLM-4-Voice 成为实时语音交互的强大工具,支持不同语言和方言的对话 AI。
在本地设置 GLM-4-Voicee
要体验 GLM-4-Voice,请按照以下步骤在您的机器上本地设置该模型。
第一步:克隆仓库
首先从 GitHub 克隆仓库。确保包含子模块:
!git clone--recurse-submodules
https://github.com/THUDM/GLM-4-Voice
cd GLM-4-Voice
步骤 2:安装依赖
进入项目目录并安装必要的依赖:
!pip install -r
requirements.txt
第3步:下载模型检查点
GLM-4-Voice的解码器模型托管在Hugging Face上,需要git-lfs进行下载。确保已安装git-lfs,然后运行:
!git clone
https://huggingface.co/THUDM/glm-4-voice
步骤 4:启动模型服务
一切设置完成后,启动模型服务器:
python
model_server.py --model-path glm-4-voice-9b
第5步:启动Web服务
一旦模型服务器运行,执行以下命令以启动Web服务:
python
web_demo.py
您现在可以访问Web演示 http://127.0.0.1:8888 与GLM-4-Voice进行交互。
注意: GLM-4-Voice模型资源密集,运行有效需要大量计算能力。具体来说,它需要35–40个GPU以实现最佳性能,因此适合在可访问高性能硬件的环境中部署。用户在尝试使用此模型之前,应确保具备必要的基础设施。
Web Demo Interfaceeb Demo
Interface
GLM-4-Voice
的网页演示提供了一个直观的界面,具有多种自定义选项:
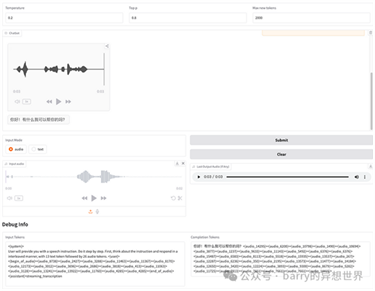
·输入模式:用户可以选择以文本或音频形式提供输入。这种灵活性允许无手操作或传统交互。
·语音控制参数:调整温度、top-p
和令牌限制,以自定义模型的响应特性。
·调试信息:显示输入和输出令牌,使用户能够洞察模型处理查询的过程。
·交互式音频显示:音频输入和响应以波形形式显示,用户可以重播或查看音频片段以评估质量。
然而,用于在演示中流式传输音频的 Gradio 有时可能会出现不稳定情况。为了获得最佳质量,建议在生成后重播对话框中的音频
结论
GLM-4-Voice
在对话式人工智能领域中脱颖而出,提供了独特的双语支持、实时音频交互和灵活的响应定制。其端到端设计和低延迟使其成为客户服务、教育、虚拟助手等应用的最佳候选者。凭借易于访问的设置过程,GLM-4-Voice 为开发者和研究人员探索中文和英文的高级语音能力打开了大门。
随着对更互动和真实的人工智能需求的不断增长,像 GLM-4-Voice 这样的模型代表了在消除语言和对话障碍方面的重要进展。无论您是想构建聊天机器人、虚拟教师还是客户服务代理,GLM-4-Voice 都提供了强大而灵活的解决方案。
原文出自:https://mp.weixin.qq.com/s/SL78O2qyCmessCN2xoQldw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
体验身临其境的 AI 世界,故事实时展开,角色栩栩如生。