京东开源普通话数字人JoyHallo,一口流利标准普通话还会讲英语
发布时间:2024年11月18日
在音频驱动的视频生成领域,制作普通话视频面临着许多挑战。首先,收集全面的普通话数据集非常困难;其次,普通话的复杂口型动作使得模型训练比英语更具挑战性。为了解决这个问题,JoyHallo 收集了来自京东健康国际公司员工的29小时普通话语音视频,形成了 jdh-Hallo 数据集。这个数据集中包含了不同年龄和说话风格的人,涵盖了日常对话和专业医疗主题。为了让 JoyHallo 模型适应普通话,采用了中文的 wav2vec2 模型来提取音频特征。同时,提出了一种半解耦结构,旨在捕捉嘴唇、表情和姿态特征之间的关系。这种集成不仅提高了信息的利用效率,还加快了推理速度,提升了 14.3%。值得一提的是,JoyHallo 在生成英语视频方面依然表现出色,显示了其优秀的跨语言生成能力。(链接在文章底部)
01 技术原理—
虽然现有模型如 AnimateAnyone 和 Hallo 在英语视频生成方面表现优异,但由于缺乏高质量的普通话数据集以及普通话复杂的唇部动作,它们在普通话生成中表现不佳。为了解决这一问题,引入了 JoyHallo 模型,采用了半解耦结构,以提高普通话唇部动作预测的准确性。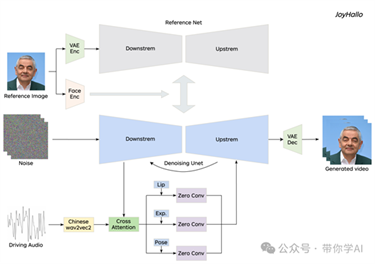 半解耦结构是一种创新模块,旨在提高音频驱动视频生成中唇部动作预测的准确性,尤其是针对普通话。这一结构整合并分离了面部动画中涉及的关键组成部分,使得复杂的唇部动作和表情建模更加精确。在传统模型中,唇部动作、表情和头部姿势等特征通常是交织在一起的,导致由于普通话音素的复杂性而产生的结果不理想。有些方法,例如 Hallo,采用完全解耦的方法,将面部特征完全分开并独立学习。虽然这种方法在孤立个别特征方面有效,但可能妨碍模型学习面部特征之间的隐含关联。随着面部特征复杂性的增加,保持生成准确性变得更加困难。
半解耦结构是一种创新模块,旨在提高音频驱动视频生成中唇部动作预测的准确性,尤其是针对普通话。这一结构整合并分离了面部动画中涉及的关键组成部分,使得复杂的唇部动作和表情建模更加精确。在传统模型中,唇部动作、表情和头部姿势等特征通常是交织在一起的,导致由于普通话音素的复杂性而产生的结果不理想。有些方法,例如 Hallo,采用完全解耦的方法,将面部特征完全分开并独立学习。虽然这种方法在孤立个别特征方面有效,但可能妨碍模型学习面部特征之间的隐含关联。随着面部特征复杂性的增加,保持生成准确性变得更加困难。 半解耦结构最初将这些特征耦合在一起,并通过交叉注意力模块共同处理,以捕捉它们之间的相关特性。然后,采用解耦模块来分离不同的特征。这种分离允许模型专注于每个特征的特定细微差别,而不会受到其他特征的干扰。这种半解耦结构有效平衡了独立特征处理与捕捉特征间关系的能力,从而增强了整体性能和适应性。通过利用这一结构,JoyHallo 模型在普通话视频生成中的唇部同步和面部表情的准确性得到了显著提升。此外,使用中文 wav2vec2 模型进一步提高了普通话的表现。这种方法不仅增加了生成视频的真实感,还提高了推理效率。
半解耦结构最初将这些特征耦合在一起,并通过交叉注意力模块共同处理,以捕捉它们之间的相关特性。然后,采用解耦模块来分离不同的特征。这种分离允许模型专注于每个特征的特定细微差别,而不会受到其他特征的干扰。这种半解耦结构有效平衡了独立特征处理与捕捉特征间关系的能力,从而增强了整体性能和适应性。通过利用这一结构,JoyHallo 模型在普通话视频生成中的唇部同步和面部表情的准确性得到了显著提升。此外,使用中文 wav2vec2 模型进一步提高了普通话的表现。这种方法不仅增加了生成视频的真实感,还提高了推理效率。
https://github.com/jdh-algo/JoyHallo
原文出自:https://mp.weixin.qq.com/s/nkuTPr4HWJJq2opiBwg09A
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
TattoosAi,AI纹身,人工智能驱动的纹身师,如果你有一个纹身的想法,但找不到合适的设计,TattoosAi能在几秒钟内生成一个。