开源大模型超越GPT-3.5!爆火MoE实测结果出炉,网友:OpenAI越来越没护城河了
发布时间:2024年06月06日
一条神秘磁力链接引爆整个AI圈,现在,正式测评结果终于来了:
首个开源MoE大模型Mixtral 8x7B,已经达到甚至超越了Llama 2 70B和GPT-3.5的水平。
(对,就是传闻中GPT-4的同款方案。)
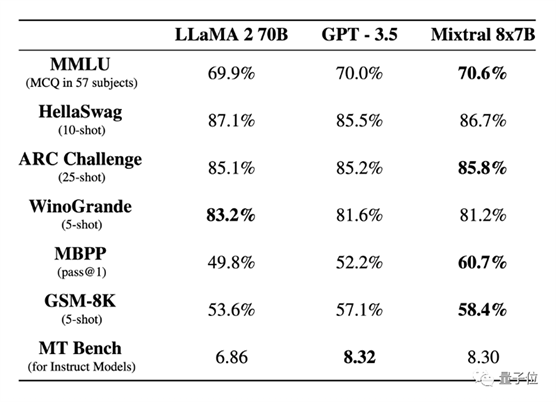
并且由于是稀疏模型,处理每个token仅用了12.9B参数就做到了这般成绩,其推理速度和成本也与12.9B的密集模型相当。
消息一出,再次在社交媒体上掀起讨论热潮。

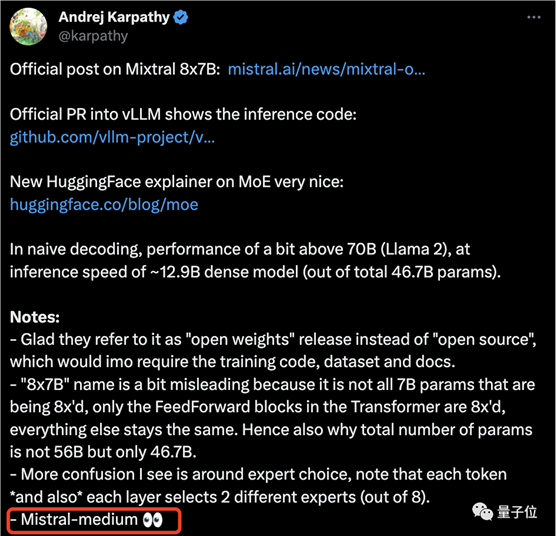
OpenAI创始成员Andrej Karpathy第一时间赶到现场整理起了笔记,还高亮出了重点:这家“欧版OpenAI”透露出的最强模型,还只是“中杯”。
p.s. Mixtral
8×7B甚至只是小杯……
英伟达AI科学家Jim Fan则赞说:
每个月都会有十几个新的模型冒出来,但真正能经得住检验的却寥寥无几,能引发大家伙热烈关注的就更少了。

并且这波啊,不仅是模型背后公司Mistral AI大受关注,也带动MoE(Mixture of Experts)再次成为开源AI社区的最火议题。
HuggingFace官方就趁热发布了一篇MoE的解析博文,同样打出了“转发如潮”的效果。

值得关注的是,Mistral AI的最新估值已经冲破20亿美元,在短短6个月中增长了7倍多……
基本超越Llama 2 70B
说起来,Mistral AI这家公司也是不走寻常路。隔壁大厂前脚刚轰轰烈烈搞发布会,慢慢悠悠发模型,他们可倒好,直接来了个程序颠倒:
先甩链接开放下载,又给vLLM项目(一个大模型推理加速工具)提了PR,最后才想起来发布技术博客给自家模型整了个正经官宣。

△模型一开始是酱婶发布的
那么还是先来看看,官方给出了哪些信息,与这两天吃瓜群众自己扒出来的细节有何不同。
首先,官方自信地表示:
Mixtral 8×7B在大多数基准测试中都优于Llama 2 70B,推理速度快了6倍。
它是最强大的、具有宽松许可的开放权重模型,也是最佳性价比之选。
具体来说,Mixtral采用了稀疏混合专家网络,是一个decoder-only的模型。在其中,前馈块会从8组不同的参数组中进行选择——
也就是说,实际上,Mixtral 8×7B并不是8个7B参数模型的集合,仅仅是Transformer中的前馈块有不同的8份。
这也就是为什么Mixtral的参数量并不是56B,而是46.7B。

其特点包括以下几个方面:
§在大多数基准测试中表现优于Llama 2 70B,甚至足以击败GPT-3.5
§上下文窗口为32k
§可以处理英语、法语、意大利语、德语和西班牙语
§在代码生成方面表现优异
§遵循Apache 2.0许可(免费商用)
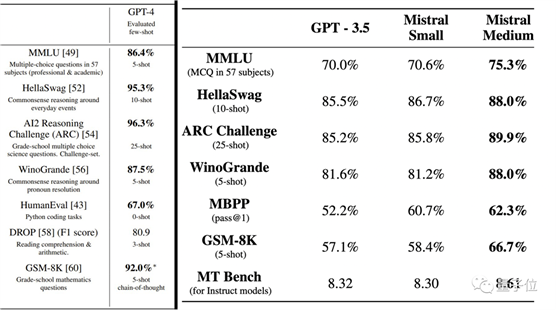
具体测试结果如下:
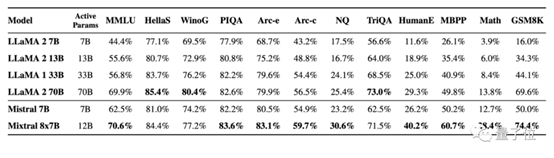
另外,在幻觉问题方面,Mixtral的表现也由于Llama 2 70B:
在TruthfulQA基准上的成绩是73.9% vs 50.2%;在BBQ基准上呈现更少的偏见;在BOLD上,Mixtral显示出比Llama 2更积极的情绪。
此次与Mixtral 8×7B基础版本一起发布的,还有Mixtral 8x7B Instruct版本。后者经过SFT和DPO优化,在MT-Bench上拿到了8.3的分数,跟GPT-3.5差不多,优于其他开源大模型。

目前,Mistral官方已经宣布上线API服务,不过还是邀请制,未受邀用户需要排队等待。
值得关注的是,API分为三个版本:
§小小杯(Mistral-tiny),对应模型是Mistral 7B Instruct;
§小杯(Mistral-small),对应模型是这次发布的Mixtral 8×7B;
§中杯(Mistral-medium),对应的模型尚未公布,但官方透露其在MT-Bench上的得分为8.6分。
有网友直接把GPT-4拉过来对比了一下。可以看到,中杯模型在WinoGrande(常识推理基准)上的得分超过了GPT-4。
价格方面,小小杯到中杯的输入和输出价格分别是每一百万token0.14~2.5欧元和0.42~7.5欧元不等,嵌入模型则是0.1欧元每百万token(1欧元约合7.7人民币)。

而在线版本,目前还只能到第三方平台(Poe、HuggingFace等)体验。
能看懂中文,但不太愿意说
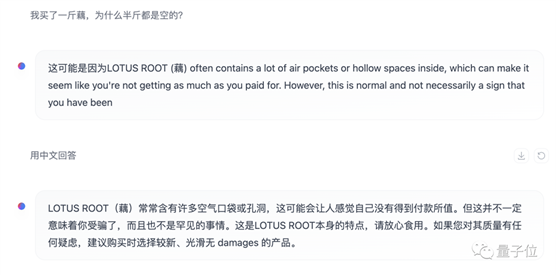
虽然官方通告中并没有说支持中文,但我们实测(HuggingFace Chat中的在线版,模型为Instruct版本)发现,Mixtral至少在理解层面上已经具备一定中文能力了。
生成层面上,Mixtral不太倾向于用中文来回答,但如果指明的话也能得到中文回复,不过还是有些中英混杂的情况。
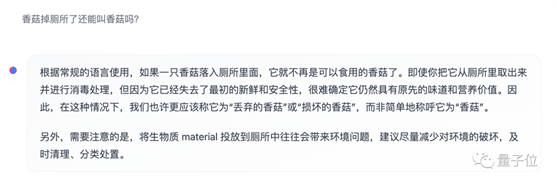
面对更多的“弱智吧”问题,Mixtral的回答虽中规中矩,但看上去至少已经理解了字面含义。
数学方面,面对经典的鸡兔同笼问题,Mixtral的回答从过程到结果都完全正确。

即使是高等数学问题,比如复杂的函数求导,Mixtral也能给出正确答案,更难能可贵的是过程没什么问题。

而此次的官方通告中专门强调了Mixtral的代码能力很强,所以也受到了我们的重点考察。
一道困难难度的LeetCode下来,Mixtral给出的代码一次就通过了测试。
给你一个未排序的整数数组nums,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为O(n)并且只使用常数级别额外空间的解决方案。

但随着我们继续提问,Mixtral的回答一不小心暴露了自己可能专门针对LeetCode做过训练,而且还是中文版LC。

为了更加真实地展示Mixtral的代码能力,我们转而让它编写实用程序——用JS写一个Web版计算器。
经过几轮调整之后,虽然按钮的布局有些奇怪,但基本的四则运算已经可以完成了。

此外我们会发现,如果在同一个对话窗口中不断补充新的要求,Mixtral的表现可能会有所下降,出现代码格式混乱等问题,开启新一轮对话后则会恢复正常。
除了API和在线版本,Mistral AI还提供了模型下载服务,可以用𝕏上的磁力链接或通过Hugging Face下载之后在本地部署。
在𝕏上,已经有不少网友在自己的设备上跑起了Mixtral,还给出了性能数据。
在128GB内存的苹果M3 Max设备上,使用16位浮点精度运行Mixtral时消耗了87GB显存,每秒可以跑13个token。

同时也有网友在M2 Ultra上通过llama.cpp跑出了每秒52token的速度。
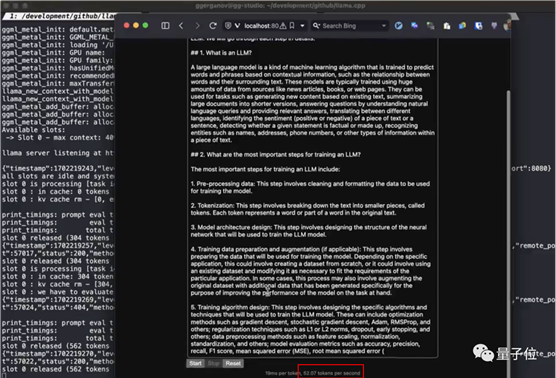
看到这里,你会给Mistral AI的模型实力打几分?
不少网友是已经兴奋起来了:
“OpenAI没有护城河”,看起来肯定会成为现实……
要知道,Mistral AI今年5月才刚刚成立。
短短半年,已是一手20亿美元估值,一手惊艳整个AI社区的模型。
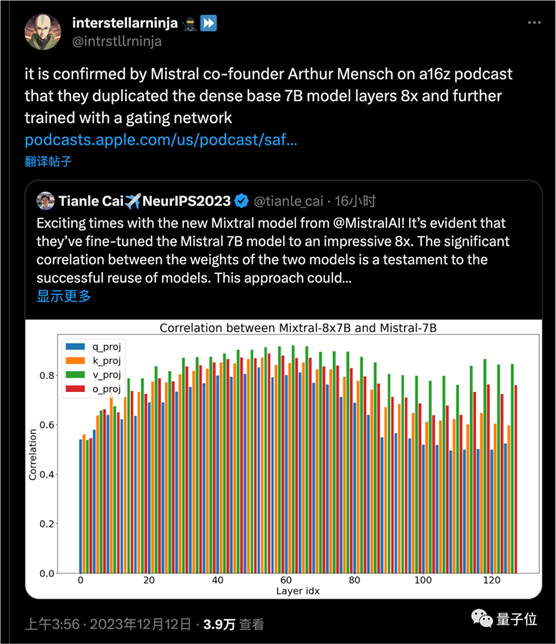
更关键的是,普林斯顿博士生Tianle Cai分析了Mistral-7B与Mixtral-8x7B模型的权重相关性做了分析,证明了模型的成功复用。
随后网友发现,Mistral AI创始人也亲自证实,MoE模型确实就是把7B基础模型复制8次,再进一步训练来的。
随着此类模型的免费商用,整个开源社区、新的创业公司都可以在此基础之上推动MoE大模型的发展,就像Llama已然带动的风暴那样。
作为吃瓜群众,只能说:

参考链接:
[1]https://mistral.ai/news/mixtral-of-experts/
[2]https://mistral.ai/news/la-plateforme/
[3]https://huggingface.co/blog/mixtral#about-the-name
原文:https://mp.weixin.qq.com/s/t_zdSjpoCE8PZ9FeMM0sfw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
ArchitectAI世界上第一个人工智能建筑、室内、景观设计师将照片和草图转变为新的设计风格。