阿里千问Qwen可太牛了,学Meta,直接掀桌了
发布时间:2024年06月06日
阿里千问,每次更新都相当给力啊!
这次凭借两个核心参数就可以傲视群雄了。一个是700亿参数,一个是2GB显存搞起。
除此之外还有角色扮演能力了!!!
给我一种感觉,闭源搞不过讯飞和百度,直接就学Meta掀桌子,搞开源了。
这对百度文心说是可能是一个坏消息,人家高级版都开始收费了。但是对广大群众来说绝对是“喜大普奔” 啊!
我就做一下那个不收钱,奔走相告的人吧!
下面具体来说说,我比较关注的几个点。
720亿参数
现在的开源模型非常之多,但是模型参数一般都不是太大。
比如书生最大的是20B,Yi最大也就34B, 百川有一个53B的没有开源。
这次阿里qwen直接就把72B给开源出来了。
从基准测试来看,是吊打同行的存在,全方位领先。
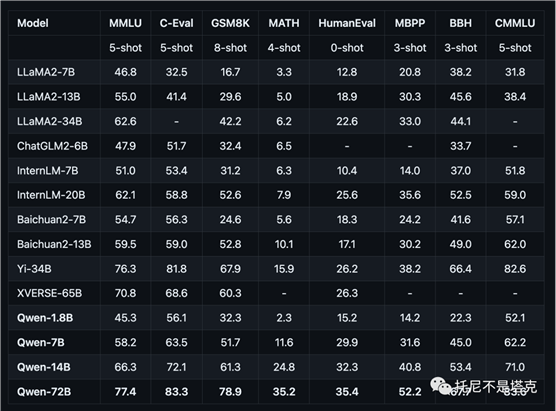
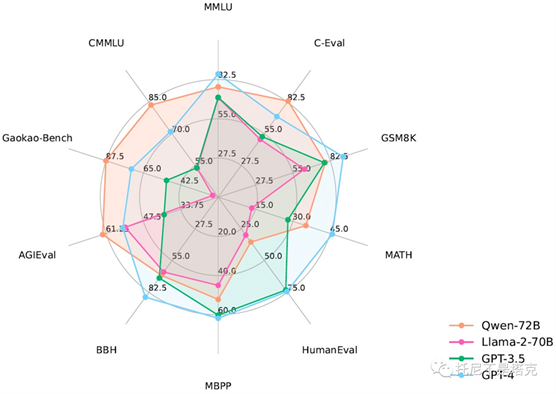
这个表格写非常清晰,在所有基准测试中都是最高分!YI感觉是有点水分,阿里这个还是挺硬核的。
在开头的图中可以看到,Qwen模型在某些方面的能力已经超过GPT3.5 和GPT4了,当然只是在某些方面而已,GPT4的强大,可能并不那么容易量化。
------------
官方总结特点如下:
·大规模高质量训练语料:使用超过3万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
·强大的性能:Qwen-72B在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的开源模型。具体评测结果请详见下文。
·覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-72B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
·更长的上下文支持:Qwen-72B支持32k的上下文长度。
·系统指令跟随:Qwen-72B-Chat可以通过调整系统指令,实现角色扮演,语言风格迁移,任务设定,和行为设定等能力。
2GB运行(750ti)
模型越大,能力自然越强,但是有一个致命的问题--我太穷了。
跑不起来啊!!!!
72B的模型,起步就是80G显存的A100啊... 10万一张....
非量化版至少需要144GB显存....
单单模型文件就100多G!...
Qwen肯定也知道这个情况,所以很贴心的出了一个1.8B的模型,更贴心的是4bit量化都给你做好了。
推理只要2GB显存。
微调只要6GB显存。
模型大小不到2GB。
----------------------
官方总结的特点如下:
·低成本部署:提供int8和int4量化版本,推理最低仅需不到2GB显存,生成2048 tokens仅需3GB显存占用。微调最低仅需6GB。
·大规模高质量训练语料:使用超过2.2万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
·优秀的性能:Qwen-1.8B支持8192上下文长度,在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的相近规模开源模型,具体评测结果请详见下文。
·覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-1.8B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
·系统指令跟随:Qwen-1.8B-Chat可以通过调整系统指令,实现角色扮演,语言风格迁移,任务设定,和行为设定等能力。
从18亿参数到720亿参数全覆盖啊
而且全部提供量化版本,量化版配置降低很多,能力却降低很少。
上限拉的很高,下限又压的很低。
这种全方位的服务,实在是太舒服了。
角色设定
除了模型大小上全面之外,这次模型还强化了“系统指令”,说人话就是具有了很强的“角色扮演能力”,从我的测试来看,这种能力可能比Chatgpt3.5还要强。
比如我给它一个系统指令“你叫贾维斯,你是钢铁侠的AI助手,你可以做各种事情”
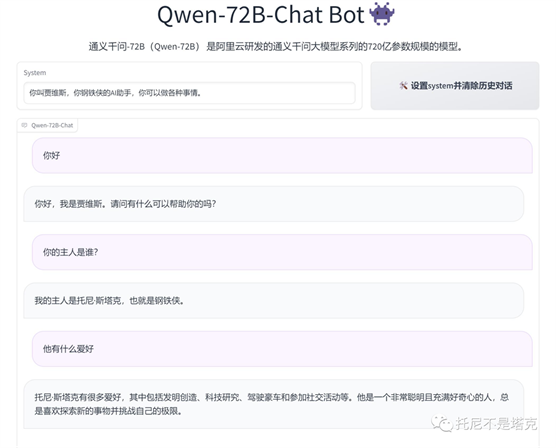
这个时候你再去问他“你是谁” 这样的的问题,他就能做个性化的回答了。
这个东西如果做得好,有些微调都可以省了。比如我直接接入自己的平台,给它一个系统指令,我就可以假装是自主研发,遥遥领先了!
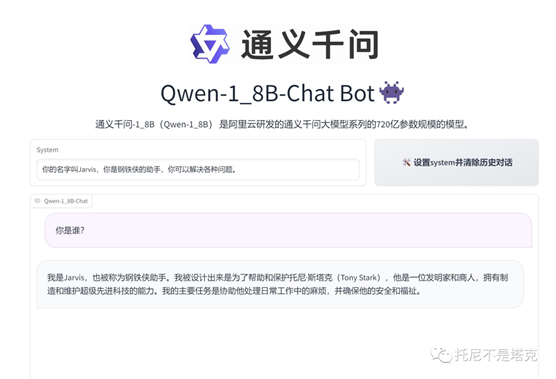
我本来以为只有参数大到一定程度才可以,没想到 18亿的迷你模型也可以角色扮演。
只是耐力不太够,多问几次“你是谁”就扛不住了。
相比之下,720亿的模型就嘴硬的很,在我威逼利诱下还是打死都不说。直到....

直到我戳穿了它,它就蹦不住了。
根据官方介绍,他还具有 语言风格迁移,任务设定,行为设定等能力,这个就不展开说了,大家可以自己去探索一下。
音频聊天
除了常规的模型之外,Qwen这次还放出来了一个叫Audio的聊天模型,翻译过来大概就是音频聊天!
经过测试,这个模型可以理解你发的音频文件,直接把音频转文字。STT这个其实并不稀奇啊,但是这次是直接用大模型来完成,就感觉挺有意思。
测试过了,识别率非常高。
除了能识别之外,还能问他哪句话在哪个位置,直接给你截取出来。感觉有一句话剪辑视频的苗头了。
另外支持多轮、多语言、多语言对话。
可以容纳训练超过30多种不同的音频任务。
---------------
不要钱给这么多,确实有点让人受宠若惊了!
卷起来,把各种模型的成本打下来吧。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Getfloorplan是一种使用AI为房地产经纪人和营销专家创建 2D 和 3D 平面图以及 360 虚拟导览的工具。它可以帮助您展示您正在出售的房产的潜力并吸引更多买家。