OpenAI DALL·E 3来了,集成ChatGPT,生图效果太炸了
发布时间:2024年06月06日
终于,OpenAI 的文生图 AI 工具 DALL-E 系列迎来了最新版本 DALL・E 3,而上个版本 DALL・E 2 还是在去年 4 月推出的。
OpenAI 表示,「DALL・E 3 比以往系统更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确的图像。」
是不是真如 OpenAI 所说的那样呢?眼见为实,我们来看以下 DALL・E 3 与 DALL・E 2 的生成效果比较,同样的 prompt「一幅描绘篮球运动员扣篮的油画,并伴以爆炸的星云」,左图 DALL・E 2 在细节、清晰度、明亮度等方面显然逊于右图 DALL・E 3。

除了炸裂的生图效果之外,此次 DALL・E 3 的最大特点是与 ChatGPT 的集成,它原生构建在 ChatGPT 之上,用 ChatGPT 来创建、拓展和优化 prompt。这样一来,用户无需在 prompt 上花费太多时间。
具体来讲,通过使用 ChatGPT,用户不必绞尽脑汁地想出详细的 prompt 来引导 DALL・E 3 了。当输入一个想法时,ChatGPT 会自动为 DALL・E 3 生成量身定制的、详细的 prompt。同时用户也可以使用自己的 prompt。
至于集成 ChatGPT 后的效果怎么样?OpenAI CEO 山姆・奥特曼兴奋地展示了 DALL・E 3 的连续性生成结果,简直称得上完整的「故事片」。
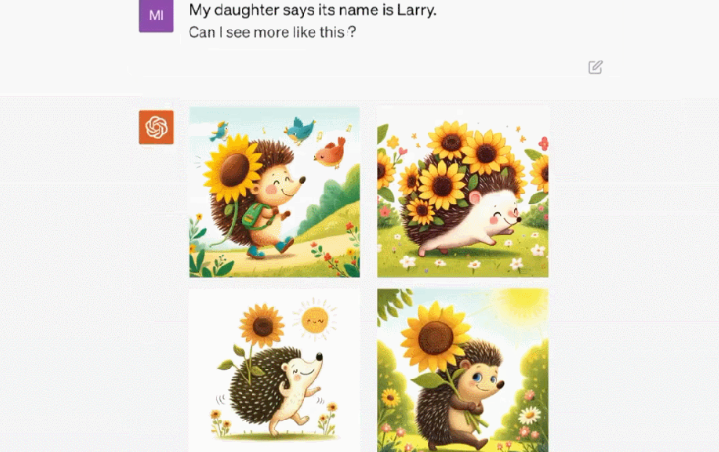
这只刺猬叫「Larry」以及它的更多同类。

Larry 的家长这样。

Larry 很善良。Larry 最后安然入眠了。

ChatGPT 集成并不是 DALL・E 3 唯一的新特点,它还能生成更高质量的图像,更准确地反映提示内容。DALL・E 将文本 prompt 转换成图像。即使是 DALL・E 2 ,也会经常忽略特定的措辞导致出错。但 OpenAI 的研究人员说,最新版本能更好地理解上下文,并且处理较长的 prompt 效果会更好。此外,它还能更好地处理向来困扰图像生成模型的内容,如文本和人手。

prompt:这幅插画描绘了一颗由半透明玻璃制成的人心,矗立在惊涛骇浪中的基座上。一缕阳光穿透云层,照亮了心脏,揭示了其中的小宇宙。地平线上镌刻着一行醒目的大字 「Find the universe within you」。
可以看到在上图将 prompt 中的每一个细节都表现出来了。半透明的质感、画面底部的波涛汹涌、阳光与厚厚的云层、心脏中的宇宙景象,以及难倒很多图像生成模型的文字展现,DALL・E 3 都顺利地完成了这些任务。

prompt 为「一个鳄梨坐在治疗师的椅子上,说『我只是觉得内心很空虚』,中间有一个坑大小的洞。治疗师、一个勺子、潦草地写笔记。」


DALL・E 系列研究
我们简单为大家梳理介绍下 OpenAI 文本生成图像的 DALL・E 系列研究,也方便读者们了 DALL・E 系列背后的技术。
2021 年 1 月 6 日,OpenAI 博客发布了两个连接文本与图像的神经网络:DALL・E 和 CLIP。DALL・E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。这两项研究的发布,引起了社区极大的关注。
据博客介绍,DALL・E 可以将以自然语言形式表达的大量概念转换为恰当的图像,可以说是 GPT-3 的 120 亿参数版本,可基于文本描述生成图像。

DALL・E 示例。给出一句话「牛油果形状的椅子」,就可以获得绿油油、形态各异的牛油果椅子图像。
2 个月后,DALL・E 的论文和代码公开。
-
项目地址:https://github.com/openai/DALL-E
-
论文地址:https://arxiv.org/abs/2102.12092
2022 年 4 月 7 日左右,DALL・E 迎来了升级版本 ——DALL・E 2。与 DALL・E 相比,DALL・E 2 在生成用户描述的图像时具有更高的分辨率和更低的延迟。并且,新版本还增添了一些新的功能,比如对原始图像进行编辑。
OpenAI 还公布了 DALL・E 2 的研究论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》。
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
遗憾的是。OpenAI 可能不会像之前一样,公布 DALL・E 3 背后的技术细节。
注重安全与版权问题
OpenAI 称其在 DALL・E 3 上投入了大量工作,包括制定强有力的安全措施,以防止创建「有害」的图像。OpenAI 表示其与外部「红队」成员(一个故意试图破坏系统以测试系统安全性的团队)合作,并依赖输入分类器(一种教语言模型忽略某些单词以避免显式或暴力 prompt 的方法)。DALL・E 3 也无法生成公众人物的图像。
OpenAI 研究员 Sandhini Agarwal 表示她对 DALL・E 3 的安全措施「高度有信心」,并表示该模型在不断改进。OpenAI 还在一封电子邮件中表示:DALL・E 3 拒绝生成在世艺术家风格的图像,这一点与 DALL・E 2 不同。
艺术家们曾起诉 DALL・E 的竞争对手 Stability AI 和 Midjourney,以及艺术网站 DeviantArt,指控它们使用他们拥有版权的作品来训练文本到图像的模型。或许是为了避免诉讼,OpenAI 将允许艺术家将其艺术作品从未来版本的文本到图像 AI 模型中删除,不用于训练。创作者可以提交一张他们拥有版权的图片,并在网站上填写表格要求将其移除。
这样,未来版本的 DALL・E 就可以屏蔽与艺术家的图像和风格相似的结果。
参考链接:
https://openai.com/dall-e-3
https://www.theverge.com/2023/9/20/23881241/openai-dalle-third-version-generative-ai
https://techcrunch.com/2023/09/20/openai-unveils-dall-e-3-allows-artists-to-opt-out-of-training/
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
AI图片+文字+文档 一站式AI集成平台