Stability AI新模型FreeWilly击败Llama 2,性能媲美ChatGPT,登顶开源模型第一
发布时间:2024年06月06日
7月21日,独角兽Stability AI联合CarperAI实验室发布基于Llama 2 70B微调的新模型FreeWilly 2,以及基于Llama 1 65B微调的新模型FreeWilly 1。
在最新的 HuggingFace 的 Open LLM 排行榜上,FreeWilly 2拿下开源模型第一,平均得分比Llama 2高了4个百分点。
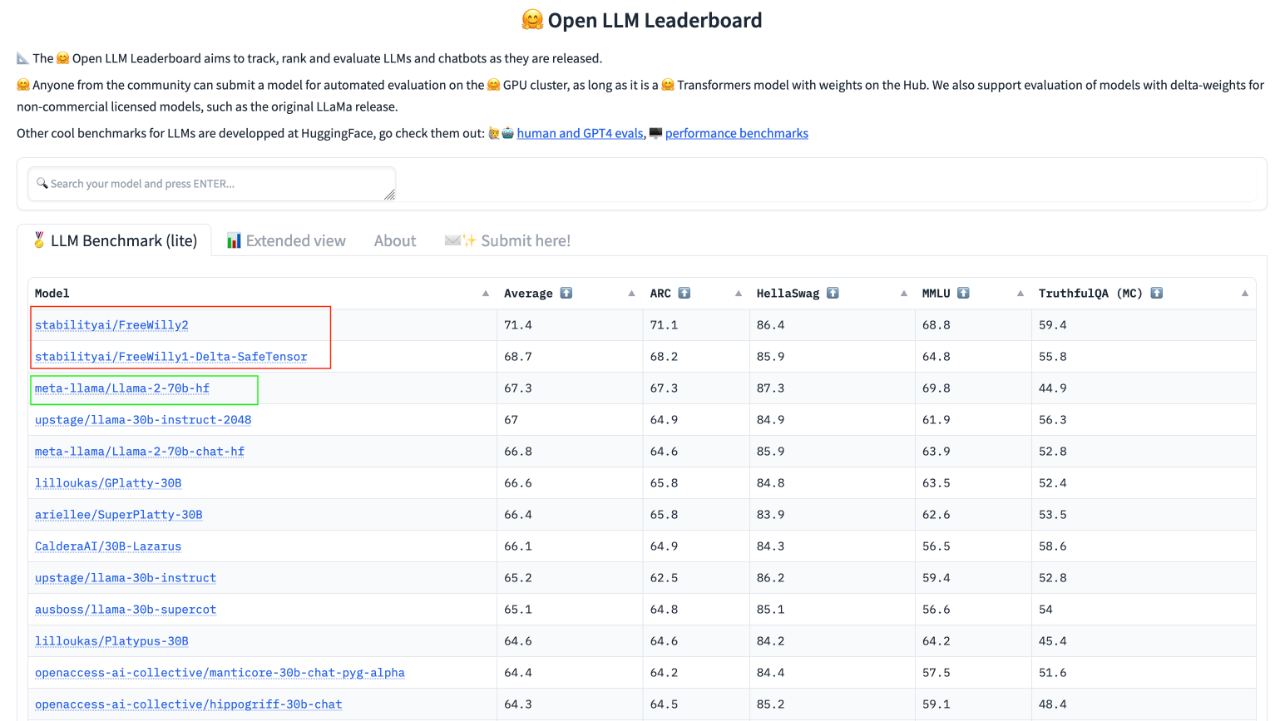
排行榜链接:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
模型地址:https://huggingface.co/stabilityai/FreeWilly2
模型地址:https://huggingface.co/stabilityai/FreeWilly1-Delta-SafeTensor
FreeWilly 模型采用了基于标准Alpaca格式,并经过监督微调(SFT)的全新合成数据集来进行训练。
根据官方的介绍,FreeWilly 2 在基准测试中表现优异,甚至有部分任务还超过了GPT-3.5。这样,FreeWilly 2 成了首个可以和 GPT-3.5 相抗衡的开源大模型,连前几天被称为「最强开源模型」的Llama 2也未达成。
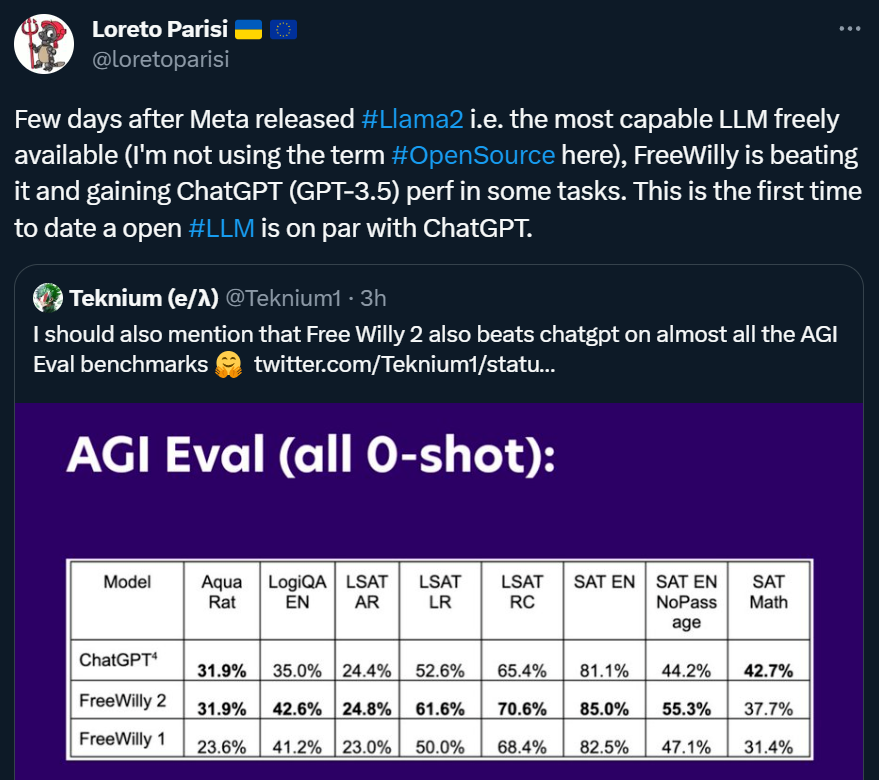
Stability AI在官方博客中表示,FreeWilly 模型的训练方法是受到微软论文《Orca: Progressive Learning from Complex Explanation Traces of GPT-4》的直接启发。所以 FreeWilly 模型的数据生成过程与它相似,但两者的数据来源却存在差异。

论文链接:https://arxiv.org/pdf/2306.02707.pdf
FreeWilly 的数据集包含了 60 万个数据点(大约是原始 Orca 论文使用的数据集大小的 10%),它是通过以下由 Enrico Shippole 创建的高质量指令数据集来启发语言模型生成的:
-
COT Submix Original
-
NIV2 Submix Original
-
FLAN 2021 Submix Original
-
T0 Submix Original
为了评估 FreeWilly 模型的性能,Stability AI的研究人员采用了 EleutherAI 的 lm-eval-harness 基准,并加入了AGIEval基准。
lm-eval-harness 基准:由 EleutherAI 非盈利人工智能研究实验室创建,是一个专门为 LLM 进行 few shot 任务测评的工具,包括了 200 多种指标的测评。HuggingFace Open LLM 排行榜就使用了该基准来进行指标( ARC (25-s), HellaSwag (10-s), MMLU (5-s) 及 TruthfulQA (MC) )计算。
AGIEval 基准:由微软创建,专门用于评估基础模型在「以人为本」(human-centric)的标准化考试中,如高考、公务员考试、法学院入学考试、数学竞赛和律师资格考试中的表现。
论文链接:https://arxiv.org/pdf/2304.06364.pdf
数据链接:https://github.com/microsoft/AGIEval
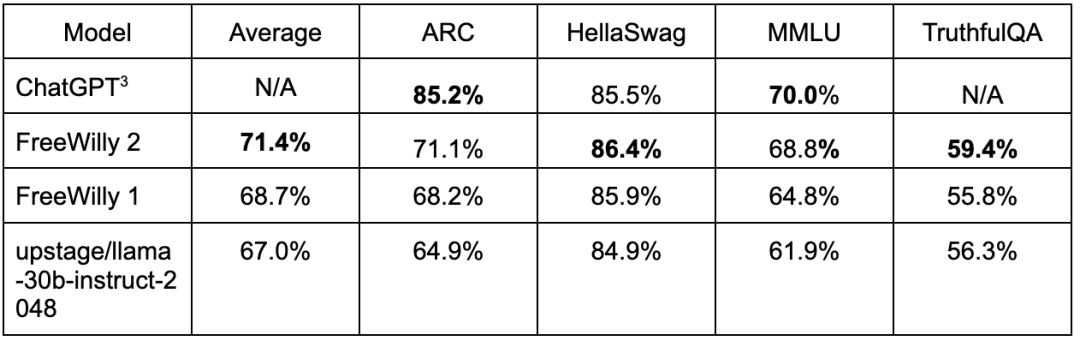
FreeWilly 1 和 FreeWilly 2 在 lm-eval-harness 基准上的评估结果如下:
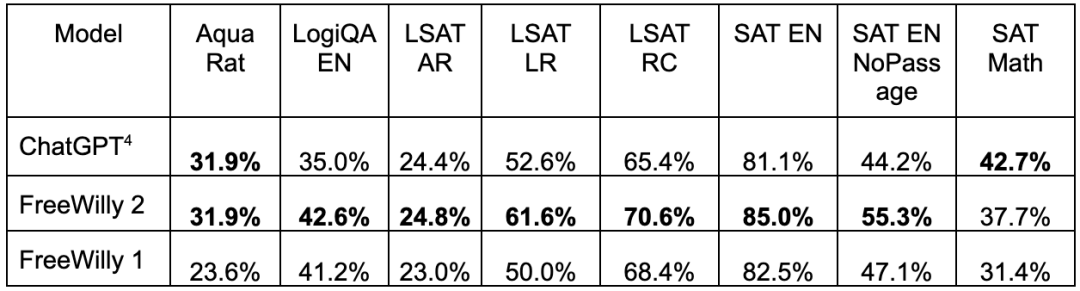
FreeWilly 1 和 FreeWilly 2 在 AGIEval 基准上的评估结果如下(全部是 0-shot):
FreeWilly 1 和 FreeWilly 2 在 GPT4ALL 基准上的评估结果如下(全部是 0-shot):

从结果上看,FreeWilly 1 和 FreeWilly 2在多个方面都表现优秀,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题(如法律和数学问题解决)。显然,开源模型正在进一步缩小与ChatGPT等最领先闭源模型的差距。
不过,虽然两个模型都是开放获取的,但官方表示,「这两款模型都是研究实验,是以非商业许可的形式发布的,仅可用于研究目」。

参考:
https://stability.ai/blog/freewilly-large-instruction-fine-tuned-models
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个提供广告法违禁词查询工具的网站,句无忧旨在帮助用户在线检测并过滤违反新广告法的禁用词、违禁词、敏感词、极限词及限制词。该网站的词库不断更新完善,适用于电商运营等多个领域。