Stable Diffusion 3 震撼发布,采用Sora同源技术,生成图像、视频真假难辨!
发布时间:2024年04月23日

==============
Stable Diffusion 3 申请地址:【点击前往】
Stable Diffusion 3 模型套件目前的参数范围为 800M 到 8B。 这种方法旨在与我们的核心价值观保持一致,为用户提供多种可扩展性和质量选项,以最好地满足他们的创意需求。 Stable Diffusion 3 结合了扩散变压器架构和流量匹配。
和很多 AI 创业公司一样,Stability AI 面临的困境在于其以惊人的速度烧钱,但却没有明确的盈利途径。去年年底,该公司还传出了 CEO 可能被投资者赶下台的消息,公司本身可能也在寻求卖身。在这样的背景下,Stability AI 迫切地需要提振投资者信心。
公司首席执行官 Emad Mostaque 在 X 平台的帖子中提到,在得到反馈并进行改进后,他们会把该模型开源
Stable Diffusion 3 背后的技术
Diffusion Transformer+Flow Matching
在博客中,Stability AI 公布了打造 Stable Diffusion 3 的两项关键技术:Diffusion Transformer 和 Flow Matching。
Diffusion Transformer
Stable Diffusion 3 使用了类似于 OpenAI Sora 的 Diffusion Transformer 框架,而此前几代 Stable Diffusion 模型仅依赖于扩散架构。
Diffusion Transformer 是 Sora 研发负责人之一 Bill Peebles 与纽约大学助理教授谢赛宁最初在 2022 年底发布的研究,2023 年 3 月更新第二版。
论文探究了扩散模型中架构选择的意义,研究表明 U-Net 归纳偏置对扩散模型的性能不是至关重要的,并且可以很容易地用标准设计(如 Transformer)取代。

论文标题:Scalable Diffusion Models with Transformers
论文链接:https://arxiv.org/pdf/2212.09748.pdf
具体来说,论文提出了一种基于 Transformer 架构的新型扩散模型 DiT,并训练了潜在扩散模型,用对潜在 patch 进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以 Gflops 衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性,各个型号的 DiT 都取得了不错的效果。
我们都知道,扩散模型的成功可以归功于它们的可扩展性、训练的稳定性和生成采样的多样性。在扩散模型的范围内,所使用的骨干架构存在很大差异,包括基于 CNN 的、基于 Transformer 的、CNN-Transformer 混合,甚至是状态空间模型。
用于扩展这些模型以支持高分辨率图像合成的方法也各不相同,现有方法或是增加了训练的复杂性,或是需要额外的模型,或是牺牲了质量。潜在扩散是实现高分辨率图像合成的主要方法,但在实践中无法表现精细细节,影响了采样质量,限制了其在图像编辑等应用中的实用性。其他高分辨率图像合成方法还有级联超分辨率、多尺度损失、增加多分辨率的输入和输出,或利用自调节和适应全新的架构方案。
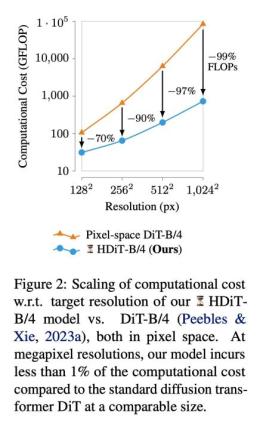
基于 DiT 的启发,Stability AI 进一步提出了 Hourglass Diffusion Transformer (HDiT)。这是一种随像素数量扩展的图像生成模型,支持直接在像素空间进行高分辨率(如 1024 × 1024)训练。
这项工作通过改进骨干网络解决了高分辨率合成问题。Transformer 架构可以扩展到数十亿个参数,HDiT 在此基础上,弥补了卷积 U-Net 的效率和 Transformer 的可扩展性之间的差距,无需使用典型的高分辨率训练技术即可成功进行训练。

论文标题:Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers
论文链接:https://arxiv.org/pdf/2401.11605.pdf
研究者引入了一种「pure transformer」架构,获得了一种能够在标准扩散设置中生成百万像素级高质量图像的骨干结构。即使在 128 × 128 等低空间分辨率下,这种架构也比 DiT 等常见 Diffusion Transformer 骨干网络(图 2)的效率高得多,在生成质量上也具有竞争力。另一方面,与卷积 U-Nets 相比,HDiT 在像素空间高分辨率图像合成的计算复杂度方面同样具备竞争力。
Flow Matching
使用 Flow Matching 技术的意义则在于提升采样效率。
深度生成模型能够对未知数据分布进行估计和采样。然而,对简单扩散过程的限制导致采样概率路径的空间相当有限,从而导致训练时间很长,需要采用专门的方法进行高效采样。在这项工作中,研究者探讨了如何建立连续标准化流的通用确定性框架。
这项研究为基于连续归一化流(CNF)的生成建模引入了一种新范式,实现了以前所未有的规模训练 CNF。

论文标题:FLOW MATCHING FOR GENERATIVE MODELING
论文链接:https://arxiv.org/pdf/2210.02747.pdf
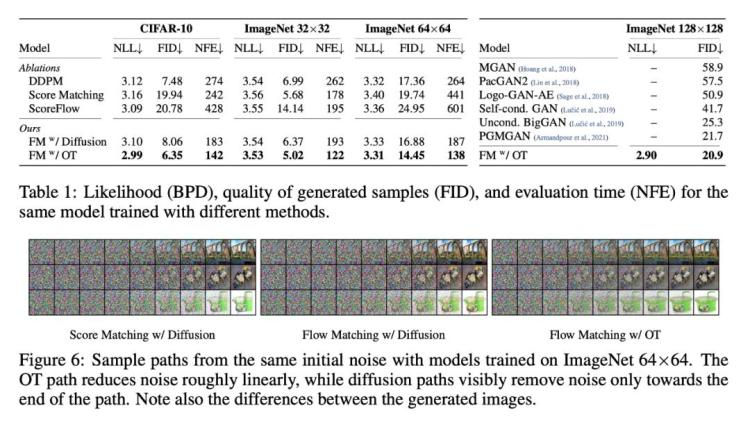
具体来说,论文提出了「Flow Matching」的概念,这是一种基于固定条件概率路径向量场回归训练 CNF 的免模拟方法。Flow Matching 与用于在噪声和数据样本之间进行转换的高斯概率路径的通用族兼容(通用族将现有的扩散路径归纳为具体实例)。
研究者发现,使用带有扩散路径的 Flow Matching 可以为扩散模型的训练提供更稳健、更稳定的替代方案。
此外,Flow Matching 还为使用其他非扩散概率路径训练 CNF 打开了大门。其中一个特别值得关注的例子是使用最优传输(OT)位移插值来定义条件概率路径。这些路径比扩散路径更有效,训练和采样速度更快,泛化效果更好。在 ImageNet 上使用 Flow Matching 对 CNF 进行训练,在似然性和采样质量方面的性能始终优于其他基于扩散的方法,并且可以使用现成的数值 ODE 求解器快速、可靠地生成采样。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Blenny AI是一个截取网页的任何部分,Blenny 将立即帮助您总结、翻译、应用自定义代理等的AI工具