Meta Llama 3 正式发布!如何在线体验和本地安装部署?
发布时间:2024年04月23日
Meta 宣布推出下一代开源大语言模型Llama 3,标志着AI发展新里程碑。该模型分为80亿和700亿参数两个版本,被誉为”Llama 2的重大飞跃”,为大规模语言模型树立新标杆。
值得一提的是,Llama 3已与Meta AI助手深度集成,未来还将陆续在AWS、Databricks、Google Cloud等多个云平台上线,并获得AMD、Intel、NVIDIA等硬件厂商的支持,进一步扩大应用场景。
该模型的发布彰显了Meta在开源AI领域的决心和影响力。我们有理由期待,Llama 3将为自然语言处理、机器学习等AI前沿技术的发展注入新动力。
在线使用:【链接直达】
不仅可以智能对话,也可以在线生成图片
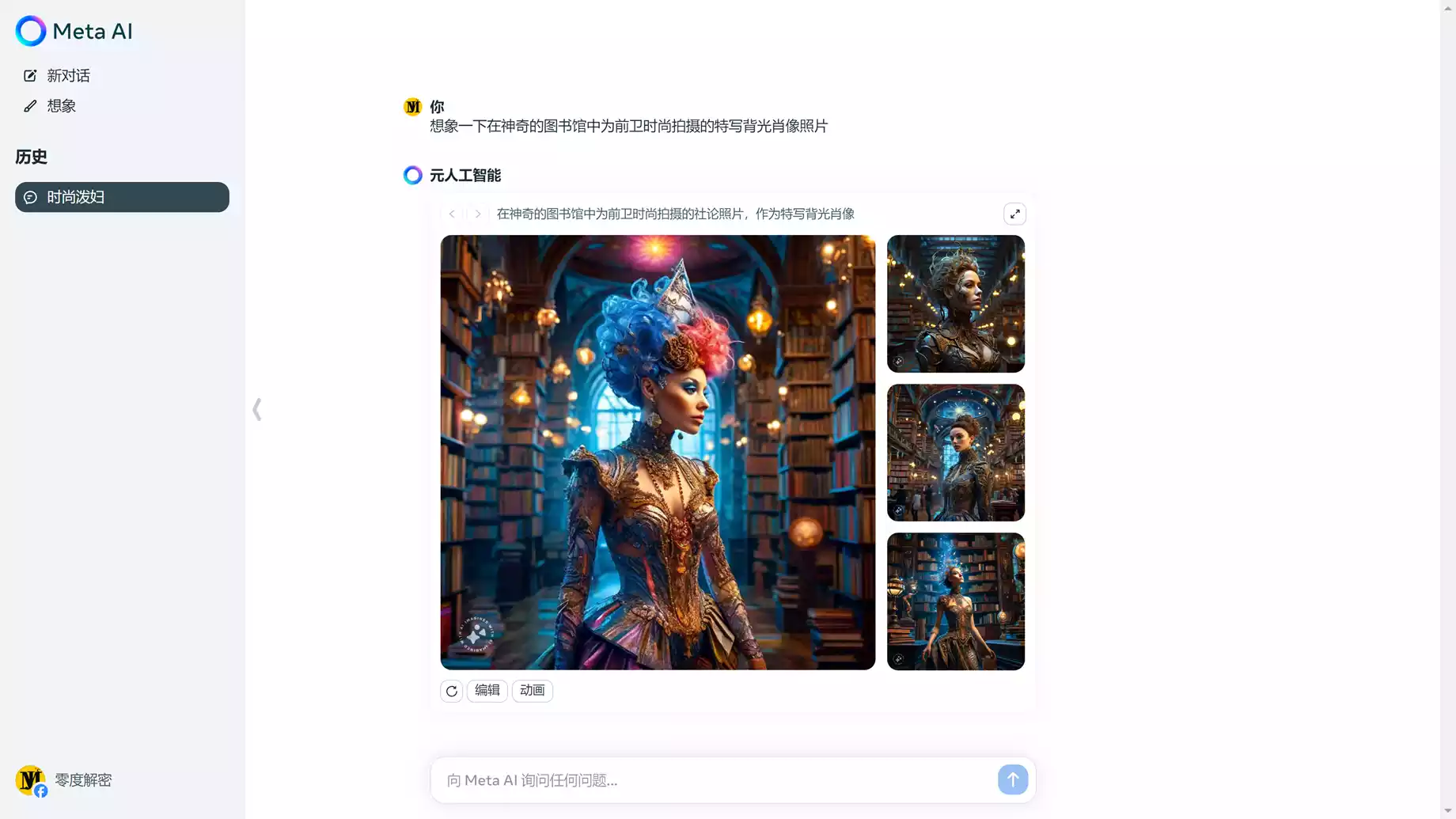
本地安装部署:
1.从github下载Llama 3 项目文件
【点击下载】
2.申请模型下载链接 (申请秒过)
【点击申请】
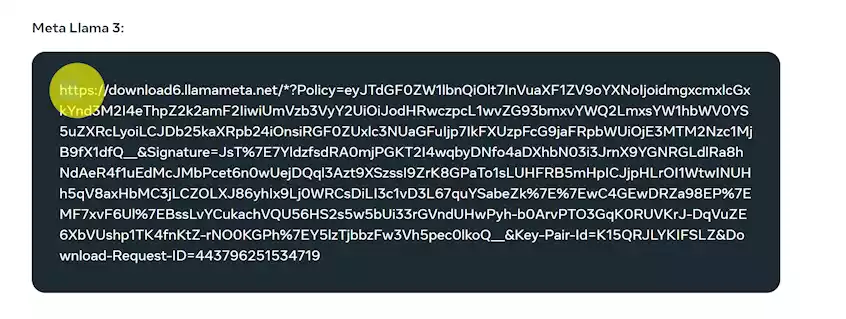
申请后会在邮件里提供一个下载链接
3.安装环境依赖
在Llama3最高级目录执行以下命令(建议在安装了python的conda环境下执行)
pip install -e .
4.下载Llama3模型,执行以下命令:
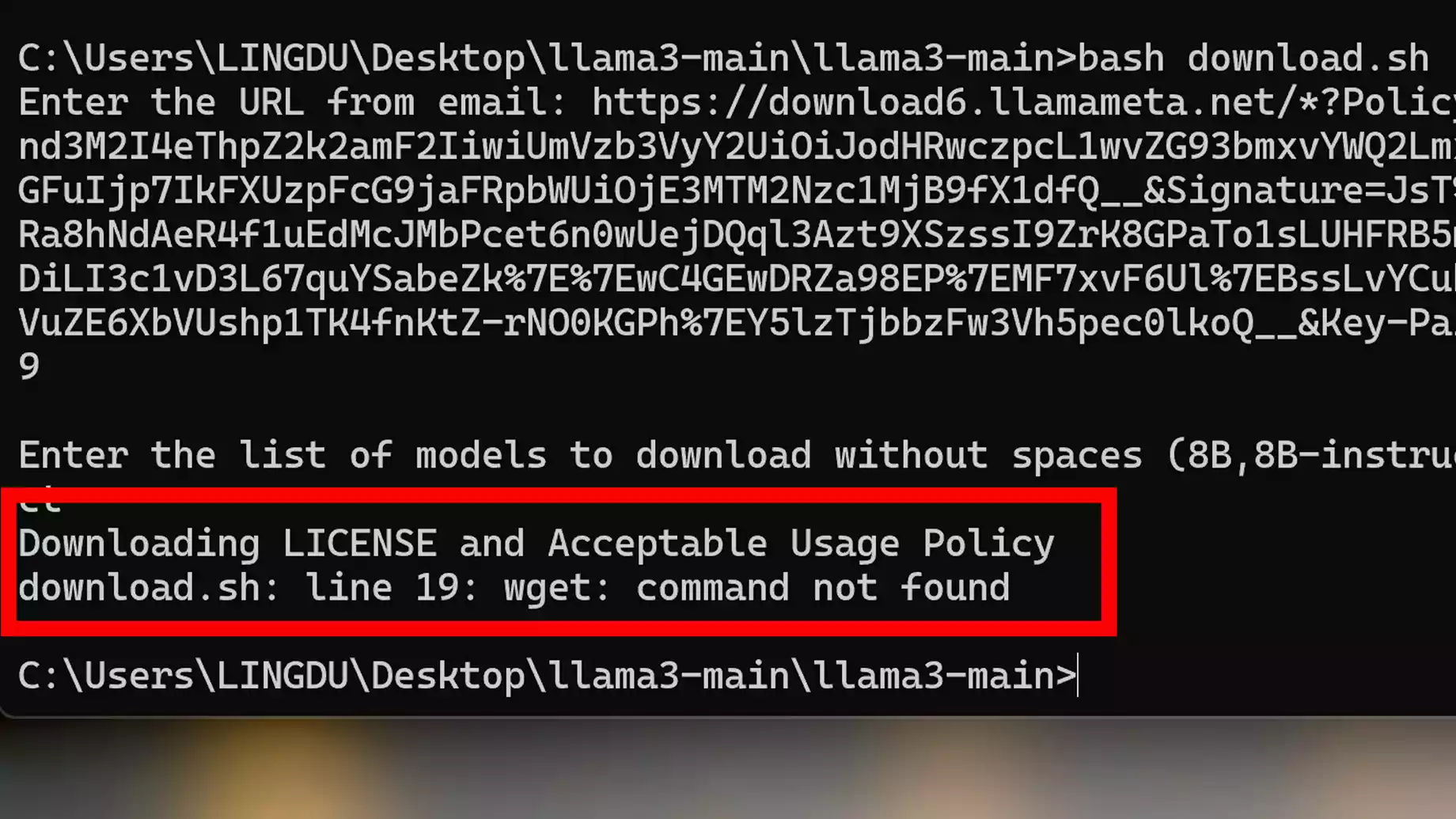
bash download.sh
运行命令后在终端下输入邮件里获取到下载链接,并选择你需要的模型,比如我选择8B-instruct
如果你在下载的时候出现这个错误,那是因为你电脑上没有安装Wget命令的环境,你只需【点击下载wget】
下载以后把wget.exe程序放在C:\Windows\System32 目录下就可以解决!看零度视频里的演示即可
5. 运行示例脚本,执行以下命令:
--ckpt_dir Meta-Llama-3-8B-Instruct/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 6
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir Meta-Llama-3-8B-Instruct/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 6
6.创建自己的对话脚本,在根目录下创建以下chat.py脚本
# This software may be used and distributed in accordance with the terms of the Llama 3 Community License Agreement.
from typing import List, Optional
import fire
from llama import Dialog, Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
"""
Examples to run with the models finetuned for chat. Prompts correspond of chat
turns between the user and assistant with the final one always being the user.
An optional system prompt at the beginning to control how the model should respond
is also supported.
The context window of llama3 models is 8192 tokens, so `max_seq_len` needs to be <= 8192.
`max_gen_len` is optional because finetuned models are able to stop generations naturally.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
# Modify the dialogs list to only include user inputs
dialogs: List[Dialog] = [
[{"role": "user", "content": ""}], # Initialize with an empty user input
]
# Start the conversation loop
while True:
# Get user input
user_input = input("You: ")
# Exit loop if user inputs 'exit'
if user_input.lower() == 'exit':
break
# Append user input to the dialogs list
dialogs[0][0]["content"] = user_input
# Use the generator to get model response
result = generator.chat_completion(
dialogs,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)[0]
# Print model response
print(f"Model: {result['generation']['content']}")
if __name__ == "__main__":
fire.Fire(main)
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed in accordance with the terms of the Llama 3 Community License Agreement.
from typing import List, Optional
import fire
from llama import Dialog, Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
"""
Examples to run with the models finetuned for chat. Prompts correspond of chat
turns between the user and assistant with the final one always being the user.
An optional system prompt at the beginning to control how the model should respond
is also supported.
The context window of llama3 models is 8192 tokens, so `max_seq_len` needs to be <= 8192.
`max_gen_len` is optional because finetuned models are able to stop generations naturally.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
# Modify the dialogs list to only include user inputs
dialogs: List[Dialog] = [
[{"role": "user", "content": ""}], # Initialize with an empty user input
]
# Start the conversation loop
while True:
# Get user input
user_input = input("You: ")
# Exit loop if user inputs 'exit'
if user_input.lower() == 'exit':
break
# Append user input to the dialogs list
dialogs[0][0]["content"] = user_input
# Use the generator to get model response
result = generator.chat_completion(
dialogs,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)[0]
# Print model response
print(f"Model: {result['generation']['content']}")
if __name__ == "__main__":
fire.Fire(main)
运行以下命令就可以开始对话:
torchrun --nproc_per_node 1 chat.py --ckpt_dir Meta-Llama-3-8B-Instruct/ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model --max_seq_len 512 --max_batch_size 6
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Laravel是一个具有表达能力和优雅语法的web应用程序框架。我们已经奠定了基础——让你自由创作,而不必为小事而烦恼。