轻松爬取清纯小姐姐私房照!小孩子别学
发布时间:2024年04月23日
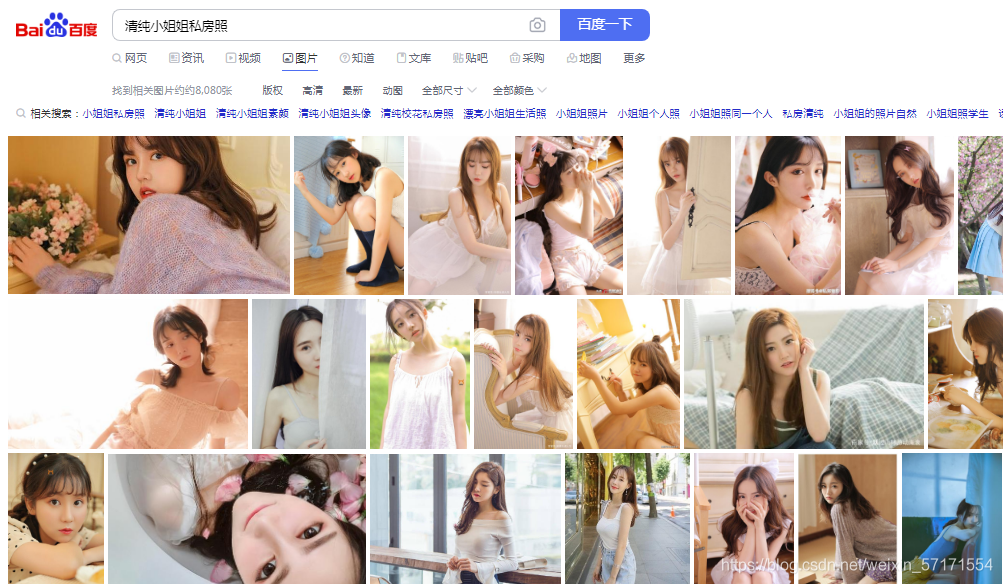
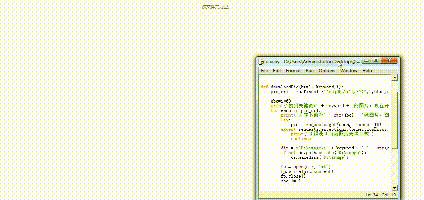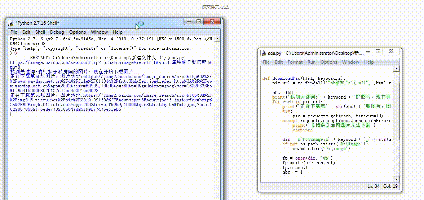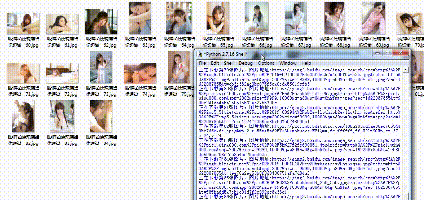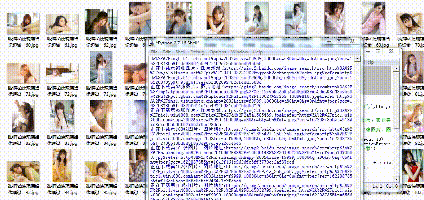
先上效果图
import requests
import os
import re import requests import os
头文件:
因为爬虫需要用到请求网络部分,所以需要这两个包,没有的话自行下载即可。这个可以直接用pip安装。如果连pip都不懂,那就只能学习一下python基础了。
请求头:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, l
完整的请求:
result = requests.get(url,headers=headers)<br>
dowmloadPic(result.content.decode(), name)
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=='+name+'+&pn='+str(i*30)
result = requests.get(url,headers=headers)
dowmloadPic(result.content.decode(), name)
正则表达式:
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
下载图片:
fp.write(pic.content)
fp.close()
fp = open(dir, 'wb') fp.write(pic.content) fp.close()
完整代码:
# -*- coding: UTF-8 -*-
import re
import requests
import os
def dowmloadPic(html, keyword,i):
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
abc=i*60
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(abc) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = r'D:\image\i' + keyword + '_' + str(abc) + '.jpg'
if not os.path.exists('D:\image'):
os.makedirs('D:\image')
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
abc += 1
if __name__ == '__main__':
#word = input("Input key word: ")
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}
name = "清纯妹子私房照"
num = 0
x =1
for i in range(int(x)):
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+name+'+&pn='+str(i*30)
print(url)
result = requests.get(url,headers=headers)
dowmloadPic(result.content, name,1)
print("下载完成")
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
import requests
import os
def dowmloadPic(html, keyword,i):
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
abc=i*60
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(abc) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = r'D:\image\i' + keyword + '_' + str(abc) + '.jpg'
if not os.path.exists('D:\image'):
os.makedirs('D:\image')
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
abc += 1
if __name__ == '__main__':
#word = input("Input key word: ")
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}
name = "清纯妹子私房照"
num = 0
x =1
for i in range(int(x)):
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+name+'+&pn='+str(i*30)
print(url)
result = requests.get(url,headers=headers)
dowmloadPic(result.content, name,1)
print("下载完成")
我从没有这么渴望过知识,第一次感受到知识的力量!!!
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
小裂变,提供专业权威的裂变式获客营销解决方案,小裂变企业微信裂变系统帮助企业搭建集裂变获客、留存促活、销售变现、客户管理于一体的裂变增长系统。