
正如预期的那样,Meta 今天发布了 Llama 3.1 系列 AI 模型。Llama 3.1 系列包括三种模型:Llama 3.1 8B、Llama 3.1 70B 和 Llama 3.1 405B。这三种模型现在都具有改进的 128K 上下文长度。此外,Meta 现在允许开发人员使用 Llama 模型的输出来改进其他模型。
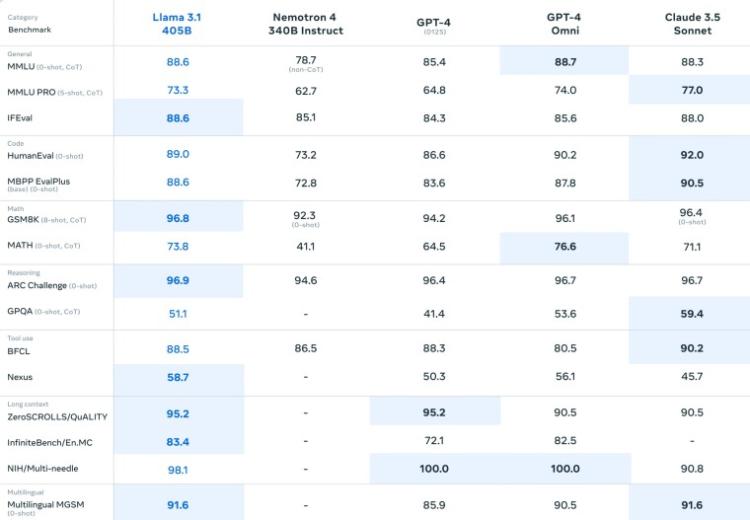
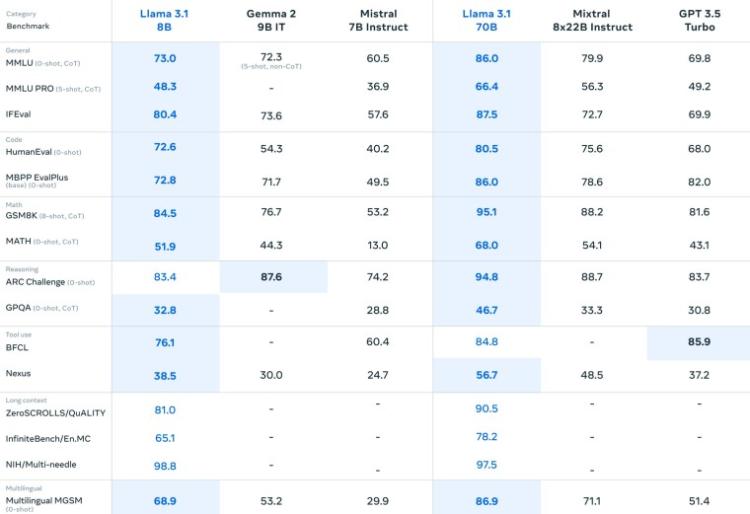
Meta 在 150 多个基准数据集上评估了 Llama 3.1 系列模型的性能。Meta 还进行了几次人工评估,以将这些模型与现实场景中的其他竞争模型进行比较。根据结果,Llama 3.1 405B 与领先的基础模型(包括 GPT-4、GPT-4o 和 Claude 3.5 Sonnet)具有竞争力。因此,Meta 现在声称 Llama 3.1 405B 是世界上最大、功能最强大的公开基础模型。此外,较小的 Llama 3.1 模型与大小相似的封闭和开放模型都具有竞争力。
Llama 3.1 405B 与其他领先型号的基准比较:
Llama 3.1 8B 和 Llama 3.1 70B 与其他领先型号的基准比较:
开发人员现在可以通过 AWS、NVIDIA、Databricks、Groq、Dell、Azure 和 Google Cloud 使用新的 Llama 3.1 系列模型。Llama 3.1 405B 可通过 Azure AI 的模型即服务作为无服务器 API 端点使用。此外,Llama 3.1 8B 和 Llama 3.1 70B 的最新微调版本现已在 Azure AI 模型目录中提供。
Meta 创始人兼首席执行官马克·扎克伯格 (Mark Zuckerberg) 针对 Llama 3.1 版本发表了以下看法:
“如今,许多科技公司正在开发领先的封闭模型。但开源正在迅速缩小差距。去年,Llama 2 仅与落后的上一代模型相当。今年,Llama 3 可以与最先进的模型相媲美,并在某些领域处于领先地位。从明年开始,我们预计未来的 Llama 模型将成为业内最先进的。但即使在此之前,Llama 已经在开放性、可修改性和成本效益方面处于领先地位。”
Meta 的 Llama 3.1 版本标志着开源 AI 行业的一个重要里程碑。Meta 的性能可与领先的封闭模型相媲美,并致力于实现可访问性,从而实现 AI 功能的民主化,促进创新,并为协作和透明度树立新标准。
妙鸭相机是一款在线生成专业质感大片的AI相机,拥有潮流、时尚、有趣、好玩的风格模板,让你方便快捷地拥有百变照片,掌握引爆朋友圈的流量密码,成为社交圈的时尚先锋!