Inpaint Anything 修复图像、视频和3D 场景中的任何内容!开源
发布时间:2024年09月10日
Inpaint Anything 可以修复图像、视频和3D 场景中的任何内容!
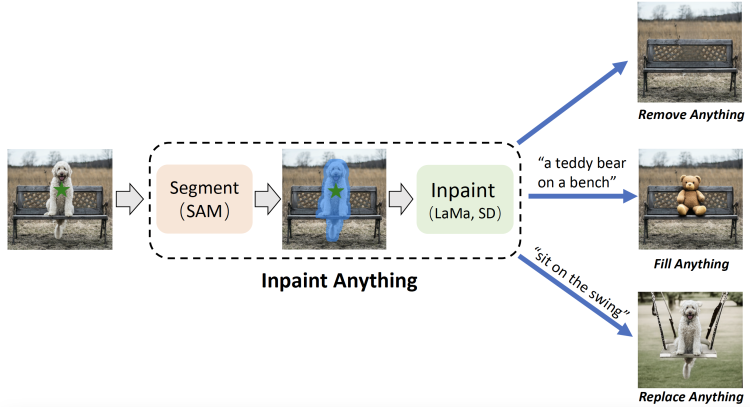
TL; DR:用户可以通过单击来选择图像中的任何对象。借助强大的视觉模型,例如SAM、LaMa和稳定扩散 (SD),Inpaint Anything能够顺利地移除对象(即Remove Anything)。此外,在用户输入文本的提示下,Inpaint Anything 可以用任何想要的内容填充对象(即Fill Anything)或任意替换其背景(即Replace Anything)。
📜 新闻
[2023/9/15] Remove Anything 3D代码可用!
[2023/4/30] Remove Anything 视频可用!您可以从视频中删除任何对象!
[2023/4/24]支持本地 Web UI!您可以在本地运行演示网站!
[2023/4/22]网站可用!您可以通过界面体验 Inpaint Anything!
[2023/4/22] Remove Anything 3D可用!您可以从 3D 场景中删除任何 3D 对象!
[2023/4/13] arXiv 上的技术报告可用!
🌟 功能
- 移除任何内容
- 填充任意内容
- 替换任何内容
- 删除任何3D内容(🔥新功能)
- 填充任意3D内容
- 替换任何3D内容
- 删除任何视频(🔥新功能)
- 填充任何视频
- 替换任何视频
💡 亮点
- 支持任意宽高比
- 支持2K分辨率
- arXiv 上的技术报告可用(🔥新)
- 网站已上线 ( 🔥新)
- 本地网页用户界面可用(🔥新)
- 支持多种模式(即图像、视频和 3D 场景)(🔥新)
📌 删除所有内容

单击图像中的某个对象,Inpainting Anything 将立即将其删除!
安装
需要python>=3.8
python -m pip install torch torchvision torchaudio
python -m pip install -e segment_anything
python -m pip install -r lama/requirements.txt
在 Windows 中,我们建议您首先安装miniconda并Anaconda Powershell Prompt (miniconda3)以管理员身份打开。然后 pip install ./lama_requirements_windows.txt而不是 ./lama/requirements.txt。
用法
下载Segment Anything和LaMa中提供的模型检查点(例如sam_vit_h_4b8939.pth和big-lama),并放入./pretrained_models。 为了简单起见,你也可以前往这里,直接下载pretrained_models,将目录放入./,即可获得./pretrained_models。
对于 MobileSAM,sam_model_type 应使用“vit_t”,sam_ckpt 应使用“./weights/mobile_sam.pt”。对于 MobileSAM 项目,请参阅MobileSAM
bash script/remove_anything.sh
指定一个图像和一个点,“Remove Anything”将会删除该点处的对象。
python remove_anything.py \
--input_img ./example/remove-anything/dog.jpg \
--coords_type key_in \
--point_coords 200 450 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama
如果你的机器有显示设备,可以改为--coords_type key_in。如果设置了,运行上述命令后,图像就会显示出来。(1)使用左键单击记录单击的坐标。它支持修改点,并且只记录最后一个点的坐标。(2)使用右键单击完成选择。--coords_type clickclick
演示
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
📌 填充任意内容
文字提示:“长凳上的一只泰迪熊”

单击一个对象,输入您想要填充的内容,Inpaint Anything 就会填充它!
安装
需要python>=3.8
python -m pip install torch torchvision torchaudio
python -m pip install -e segment_anything
python -m pip install diffusers transformers accelerate scipy safetensors
用法
下载Segment Anything中提供的模型检查点(例如sam_vit_h_4b8939.pth)并放入./pretrained_models。为了简单起见,您也可以前往,直接下载pretrained_models,将目录放入./,即可获得./pretrained_models。
对于 MobileSAM,sam_model_type 应使用“vit_t”,sam_ckpt 应使用“./weights/mobile_sam.pt”。对于 MobileSAM 项目,请参阅MobileSAM
bash script/fill_anything.sh
指定图像、点和文本提示,然后运行:
python fill_anything.py \
--input_img ./example/fill-anything/sample1.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "a teddy bear on a bench" \
--dilate_kernel_size 50 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth
演示
文字提示:“手里拿着相机镜头”
 |
 |
 |
文字提示:“墙上有一幅毕加索的画”
 |
 |
 |
文字提示:“海上有一艘航空母舰”
 |
 |
 |
文字提示:“路上的跑车”
 |
 |
 |
📌 替换任何东西
文字提示:“办公室里的一名男子”

单击一个对象,输入您想要替换的背景,Inpaint Anything 将替换它!
安装
需要python>=3.8
python -m pip install torch torchvision torchaudio
python -m pip install -e segment_anything
python -m pip install diffusers transformers accelerate scipy safetensors
用法
下载Segment Anything中提供的模型检查点(例如sam_vit_h_4b8939.pth)并放入./pretrained_models。 为了简单起见,您也可以前往,直接下载pretrained_models,将目录放入./即可./pretrained_models。
对于 MobileSAM,sam_model_type 应使用“vit_t”,sam_ckpt 应使用“./weights/mobile_sam.pt”。对于 MobileSAM 项目,请参阅MobileSAM
bash script/replace_anything.sh
指定图像、点和文本提示,然后运行:
python replace_anything.py \
--input_img ./example/replace-anything/dog.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "sit on the swing" \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth
演示
文字提示:“坐在秋千上”
 |
 |
 |
文字提示:“一辆公交车,在一条乡间小路的中央,夏天”
 |
 |
 |
文字提示:“早餐”
 |
 |
 |
文字提示:“城市十字路口”
 |
 |
 |
📌 删除任何 3D 内容
 |
 |
 |
 |
 |
 |
只需单击源视图的第一个视图中的对象,Remove Anything 3D 就可以从整个场景中删除该对象!
- 单击源视图的第一个视图中的一个对象;
- SAM将对象分割出来(使用三个可能的掩码);
- 选择一个面具;
- 利用OSTrack等跟踪模型来跟踪这些视图中的对象;
- SAM根据跟踪结果在每个源视图中分割出对象;
- 利用LaMa等修复模型来修复每个源视图中的对象。
- 利用NeRF等新颖视图合成模型来合成没有物体的场景的新颖视图。
安装
需要python>=3.8
python -m pip install torch torchvision torchaudio
python -m pip install -e segment_anything
python -m pip install -r lama/requirements.txt
python -m pip install jpeg4py lmdb
用法
下载Segment Anything和LaMa中提供的模型 checkpoint (如sam_vit_h_4b8939.pth),放入./pretrained_models。 另外,从这里下载OSTrack预训练模型(如vitb_384_mae_ce_32x4_ep300.pth)放入。 另外,下载 [nerf_llff_data](如horns),放入。 为了简单起见,你也可以到这里,直接下载pretrained_models,将目录放入,即可获得。 另外,下载pretrain,将目录放入,即可获得。./pytracking/pretrain./example/3d././pretrained_models./pytracking./pytracking/pretrain
对于 MobileSAM,sam_model_type 应使用“vit_t”,sam_ckpt 应使用“./weights/mobile_sam.pt”。对于 MobileSAM 项目,请参阅MobileSAM
bash script/remove_anything_3d.sh
指定一个 3d 场景、一个点、场景配置和遮罩索引(指示使用第一个视图的哪个遮罩结果),然后 Remove Anything 3D 将从整个场景中删除该对象。
python remove_anything_3d.py \
--input_dir ./example/3d/horns \
--coords_type key_in \
--point_coords 830 405 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama \
--tracker_ckpt vitb_384_mae_ce_32x4_ep300 \
--mask_idx 1 \
--config ./nerf/configs/horns.txt \
--expname horns
通常--mask_idx设置为 1,这通常是第一帧最可信的掩码结果。如果对象没有被很好地分割出来,你可以尝试其他掩码(0 或 2)。
📌 删除所有视频
 |
 |
 |
只需单击视频第一帧中的某个对象,“Remove Anything Video”即可从整个视频中删除该对象!
- 点击视频第一帧中的某个对象;
- SAM将对象分割出来(使用三个可能的掩码);
- 选择一个面具;
- 利用OSTrack等跟踪模型来跟踪视频中的对象;
- SAM根据跟踪结果在每帧中分割出物体;
- 利用STTN等视频修复模型来修复每一帧中的对象。
安装
需要python>=3.8
python -m pip install torch torchvision torchaudio
python -m pip install -e segment_anything
python -m pip install -r lama/requirements.txt
python -m pip install jpeg4py lmdb
用法
下载Segment Anything和STTN中提供的模型检查点(例如sam_vit_h_4b8939.pth和sttn.pth),并将它们放入./pretrained_models。此外,从这里下载OSTrack预训练模型(例如vitb_384_mae_ce_32x4_ep300.pth)并将其放入。为了简单起见,您也可以前往这里,直接下载pretrained_models,将目录放入并获取。另外,下载pretrain,将目录放入并获取。./pytracking/pretrain././pretrained_models./pytracking./pytracking/pretrain
对于 MobileSAM,sam_model_type 应使用“vit_t”,sam_ckpt 应使用“./weights/mobile_sam.pt”。对于 MobileSAM 项目,请参阅MobileSAM
bash script/remove_anything_video.sh
指定一个视频、一个点、视频 FPS 和蒙版索引(表示使用第一帧的哪个蒙版结果),Remove Anything Video 将从整个视频中删除该对象。
python remove_anything_video.py \
--input_video ./example/video/paragliding/original_video.mp4 \
--coords_type key_in \
--point_coords 652 162 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama \
--tracker_ckpt vitb_384_mae_ce_32x4_ep300 \
--vi_ckpt ./pretrained_models/sttn.pth \
--mask_idx 2 \
--fps 25
通常--mask_idx设置为 2,这通常是第一帧最可信的掩码结果。如果对象没有被很好地分割出来,你可以尝试其他掩码(0 或 1)。
演示
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
致谢
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
TechCrunch 美国主流科技网站媒体 是一个聚焦信息技术公司报道的新闻网站。 主要报道新兴互联网公司、评论互联网新产品、发布重大突发新闻。