Perplexity成立不到两年,用户数迅速增长至数千万,年经常性收入(ARR)超过2000万美元。作为一家A […]
摩根士丹利表示,上周他们完成了第二个生成式人工智能应用的部署,优先选择自研解决方案,而非从技术提供商那里购买现 […]
随着AI的普及和发展,如何有效区分人工编写和 AI 自动化生成的求职信是一个挑战?网络安全初创公司 Intri […]
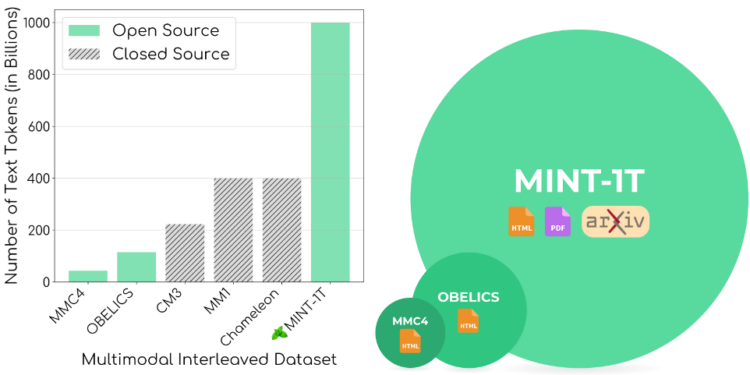
Salesforce AI宣布开源🍃MINT-1T,这是首个拥有一万亿个Token的多模态交织数据集。包含一万 […]
Diffree是一种基于扩散模型的图像编辑工具,专门用于在图像中通过文本描述添加对象。它不需要用户手动绘制任何 […]
谷歌研究团队开发了一种名为“Alchemist”的方法,允许用户在保持照片真实感的同时,对图像中对象的材料属性 […]
ViPer(Visual Personalization of Generative Models via I […]
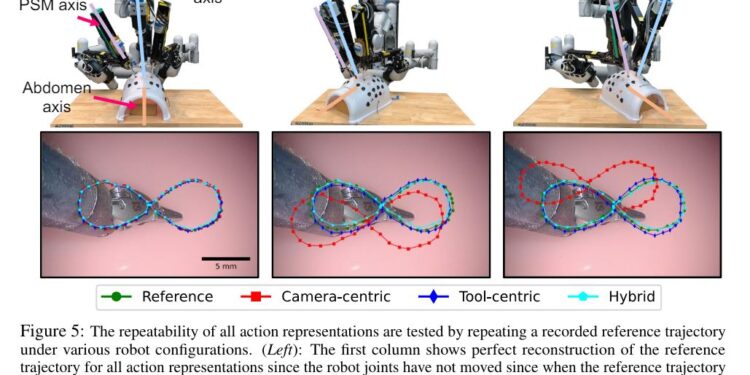
Surgical Robot Transformer (SRT) 是一个通过模仿学习在达芬奇手术机器人(da […]
Synchron的脑机接口(BCI)正在试验将ChatGPT整合到其脑机系统中,以使瘫痪患者更容易控制他们的数 […]
Meta AI 宣布推出新一代的Segment Anything Model (SAM) 2,能够在视频和图像 […]
该项目是一个实时打字翻译软件,提供语音实时打字、语音实时翻译功能,尤其适用于游戏(如LOL)的语音打字输入。其 […]
Meta AI推出 AI Studio 平台,让用户可以创建、分享和发现 AI 角色。这个平台基于 Llam […]
生数科技的 Vidu 模型直接开放了 官方称不到30秒可以生成一个4秒钟的视频… 根据演示视频来看,效果还不错 […]
Mem0为大语言模型提供了一层智能的、自我改进的记忆层,用于大语言模型(LLM),以实现跨应用程序的个性化AI […]
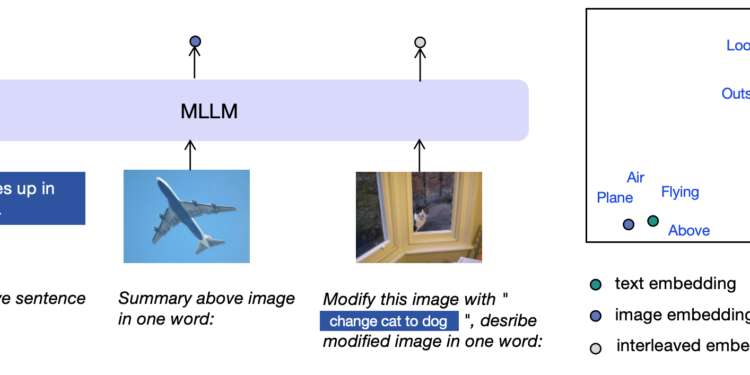
多模态大语言模型(MLLMs)已经在理解图像和文本方面取得了很大的进展,但在如何表示和整合这两种类型的信息方面 […]
Live_Portrait_Monitor 基于快手的这个 LivePortrait 项目,实现了摄像头驱动图 […]
WayveScenes101 是一个用于自动驾驶应用的高分辨率图像数据集,主要用于新视角合成(novel vi […]
AudioNotes 是一个基于 FunASR 和 Qwen2 构建的音视频内容转结构化笔记系统。它的主要功能 […]
Unique3D 是一个创新的图像到3D框架,可以从任意对象的单一正交RGB图像中生成高保真3D纹理网格,生成 […]
微软正式推出 Microsoft Designer,这是一款创新的设计应用程序,利用人工智能技术赋予用户全新的 […]
Mistral AI 宣布发布 Mistral NeMo,这是一个由 NVIDIA 协作开发的 12B 参数模 […]
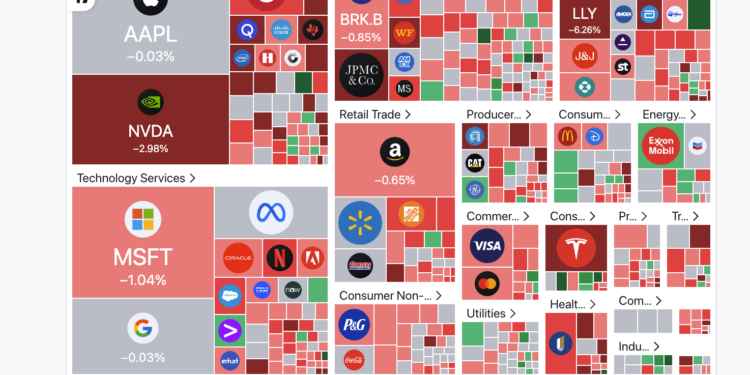
StockBot由Llama3-70B模型驱动,运行在Groq上,能够提供实时股票图表、财务数据、新闻的聊天机 […]
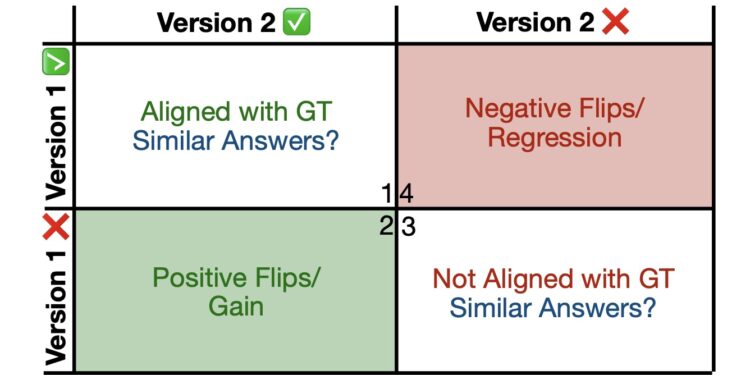
MUSCLE(Model Update Strategy for Compatible LLM Evoluti […]
IMAGDressing-v1 是一个自定义虚拟试衣系统,可生成可自由编辑的人像图像。该系统主要面向商家,帮助 […]
ElevenLabs 推出了新款 Turbo 2.5 模型。 支持印地语、法语、西班牙语、普通话和其他共32 […]
OpenAI推出了GPT-4o mini模型,用来取代GPT-3.5,这是目前市场上最具成本效益的小模型。 该 […]
TCAN项目致力于创建一个能够根据视频姿态生成一致性人像动画的方法。 也就是通过从视频中提取人物姿态动作,然后 […]
SmolLM 是由 Hugging Face 推出的一个小型语言模型系列,具有 135M、360M 和 1.7 […]
研究表明,仅通过优化链式思维(Chain-of-Thought, CoT)来解答问题,仅仅追求答案的正确性,可 […]
DETECT-2B 是由 Resemble AI 开发的一种先进的音频深度伪造检测工具。它旨在快速、准确地识别 […]







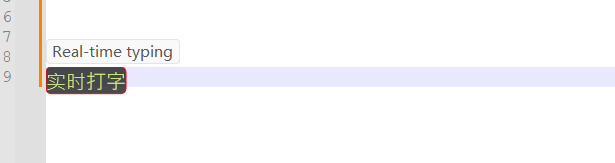














Perplexity成立不到两年,用户数迅速增长至数千万,年经常性收入(ARR)超过2000万美元。作为一家A […]