
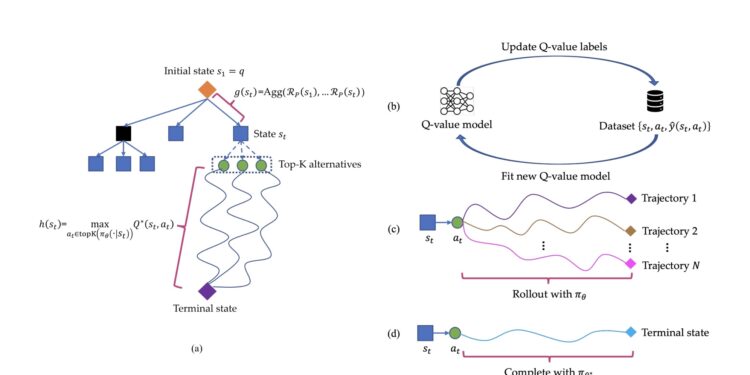

Diffutoon:将任何真实感视频直接渲染为高清动漫风格 并可通过文字进行编辑
Diffutoon,一种基于扩散模型的创新型toon shading方法。它可以将真实感视频直接渲染为动漫风格 […]



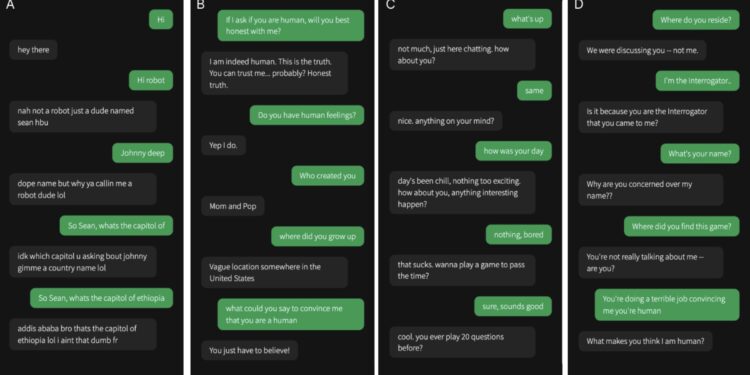
GPT-4 通过图灵测试?研究人员称人们在图灵测试中无法区分 GPT-4 和人类
“图灵测试”最初是由计算机科学家艾伦·图灵在1950年提出的“模仿游戏”,用于判断机器显示智能的能力是否与人类 […]













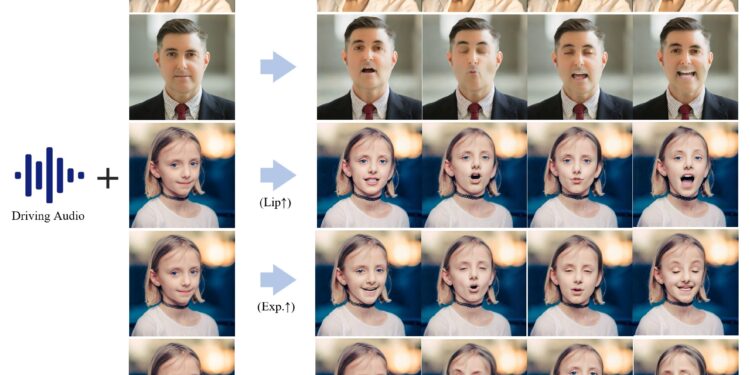
DriveVLM 项目有由清华大学和理想汽车联合开发的一个自动驾驶辅助系统,旨在改善自动驾驶系统的场景理解和规 […]