Perplexity宣布与TakoViz合作,为用户提供高级知识搜索和可视化功能。现在,用户可以在Perple […]
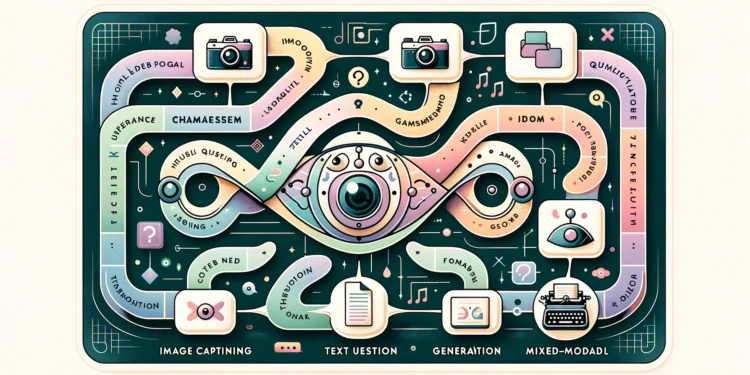
Chameleon 是由Meta的FAIR团队开发的一系列早期融合的基于令牌的混合模态模型。它可以同时处理图像 […]
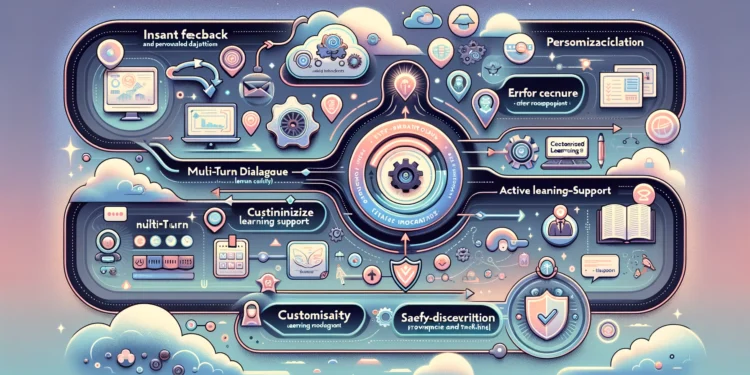
LearnLM-Tutor 是一个由 Google DeepMind 开发的生成式 AI 模型,专门用于教育领 […]
目前的人工智能模型常被描述为一个“黑箱”。因为AI 开发者不会为这些系统编写明确的规则,而是通过输入大量数据, […]
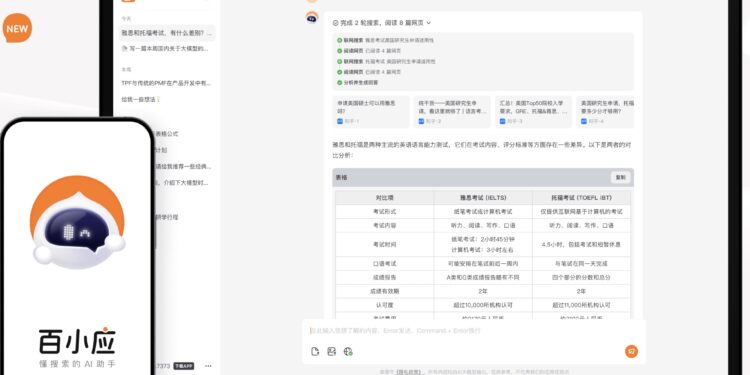
百川智能发布新一代基座大模型 Baichuan 4,并推出首款 AI 助手「百小应」,具备搜索技术与多模态能力 […]
机器翻译(MT)在各个领域取得了显著进展,但文学文本的翻译仍然是一个巨大的挑战。 腾讯 AI 实验室开发出一种 […]
微软CEO 纳德拉谈新款 Windows AI Copilot+ PC 如何击败苹果 Mac 华尔街日报的记者 […]
漫画书页面模式#prompt分享,这是为您的图画小说或漫画轻松创建高效布局概念的完美选择。 通过这个提示,您可 […]
Canva推出漫画制作工具,允许用户使用其在线平台轻松创建和分享漫画。 它提供完全可定制的模板、大量照片、图标 […]
5月20日,微软在其特别活动上,向世界介绍了一种新类别的Windows PC,一款专为AI设计的Copilot […]
在昨天的微软特别活动上,介绍了一款新型的 Windows 个人电脑——Copilot+ 个人电脑。这些是有史以 […]
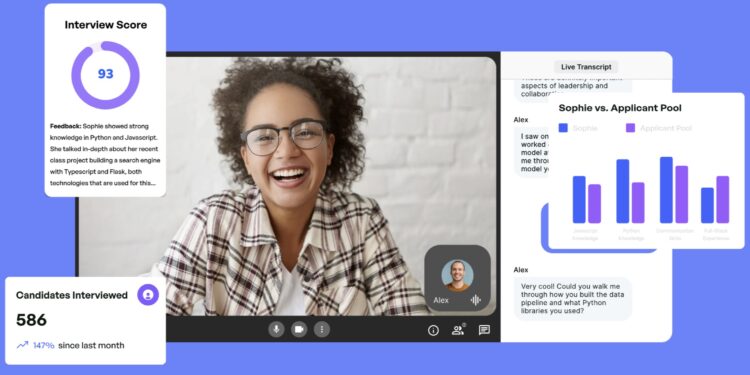
Apriora 是一个由人工智能驱动的面试平台,其主要功能包括自动安排面试、实时视频面试、即时反馈和可定制的面 […]
美国海军陆战队特种作战司令部(MARSOC)正在评估由Ghost Robotics开发的新一代四足机器人狗,这 […]
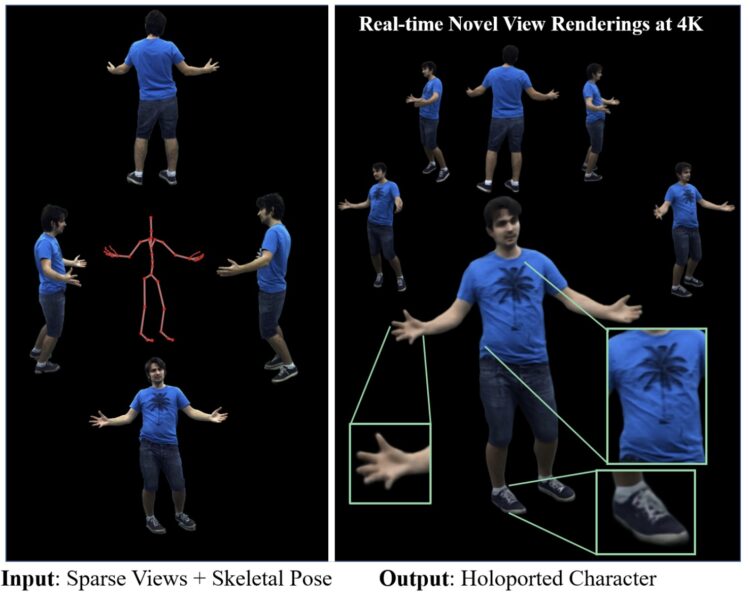
马克斯·普朗克信息学研究所、萨尔大学和萨尔布吕肯视觉计算、交互与人工智能研究中心合作,提出了一种新的实时渲染方 […]
报告介绍了 Gemini 系列的最新型号–Gemini 1.5 Pro 和 Gemini 1.5 Flash, […]
一种新的技术,可以通过文本描述生成高质量的矢量图形。传统方法存在生成的图形路径交叉或不平滑的问题,而这种新方法 […]
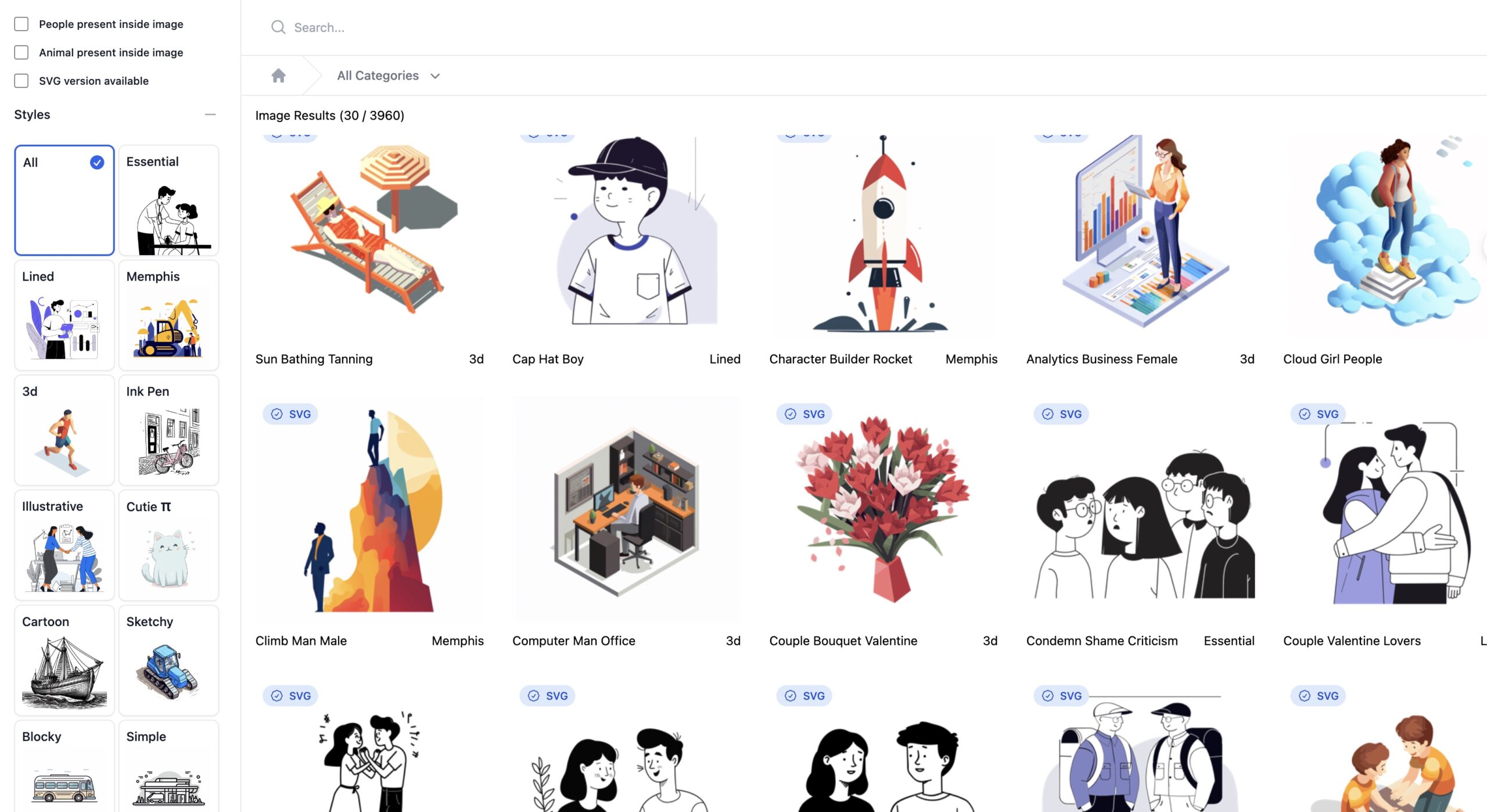
PictoGraphic 是一个AI生成的插图库,提供超过40000张图像和SVG文件,你在这里 […]
Agent Hospital是一个虚拟的医院模拟环境,在其中患者、护士和医生都作为由大语言模型(LLM)驱动的 […]
ilus AI是一款AI插画生成器,能够在几分钟内为您创建美观且风格一致的插画。用户可以使用预制模型快速生成插 […]
Danswer是一款开源的AI助手工具,旨在帮助企业快速查找和使用内部知识。它通过与团队的文档、应用程序和人员 […]
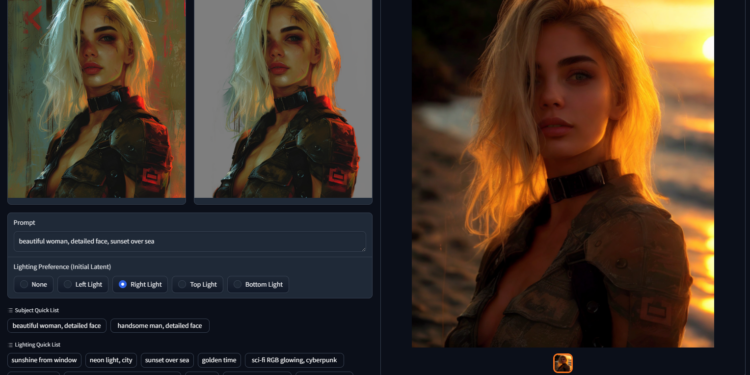
IC-Light是一款用于操纵图像照明效果的开源项目,全称为“Imposing Consistent Ligh […]
德克萨斯大学奥斯汀分校的研究人员开发了一种可拉伸的电子皮肤(e-skin),使机器人及其他设备能够拥有与人类皮 […]
MistoLine是一个基于SDXL-ControlNet的模型,专注于实现对不同类型线稿的灵活适应和高精度图 […]
近日生数科技与清华大学共同发布了中国首个长时长、高一致性、高动态性视频大模型–Vidu。这款模型被视为国内首个 […]
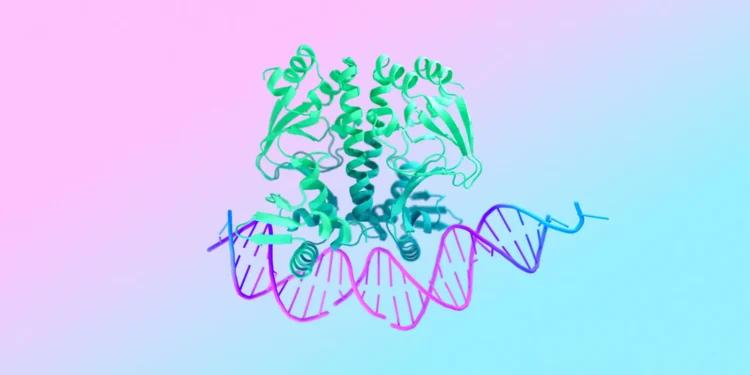
Google DeepMind 发布了 AlphaFold 3 ,一个能够预测所有生命分子结构和相互作用的 A […]
Neuralink 最近更新了他们 PRIME 脑机接口项目进展报告,在 Phoenix 亚利桑那州的巴罗神经 […]
Krea Video是一款用于生成个性化视频的工具,结合了关键帧和文本提示。 它通过关键帧和文本提示生成视频, […]
Stability AI为了赚钱绞尽了脑汁 ,推出了Stable Artisan ,这是是一款基于Discor […]
ElevenLabs 推出其自己的音乐生成模型 ElevenLabs Music,并展示了早期预览版生成的歌曲 […]
Stylar 为创作者和设计师提供了一套全面的 AI 工具,简化视觉设计流程。Stylar称自己是最可控的人工 […]




















Perplexity宣布与TakoViz合作,为用户提供高级知识搜索和可视化功能。现在,用户可以在Perple […]