苹果发布 Final Cut Pro 11,这次重大更新为专业视频编辑带来了先进的 AI 驱动功能、空间视频编 […]
Context Autopilot 是由 Context 公司推出的一款 AI 办公助手,旨在通过先进的人工智 […]
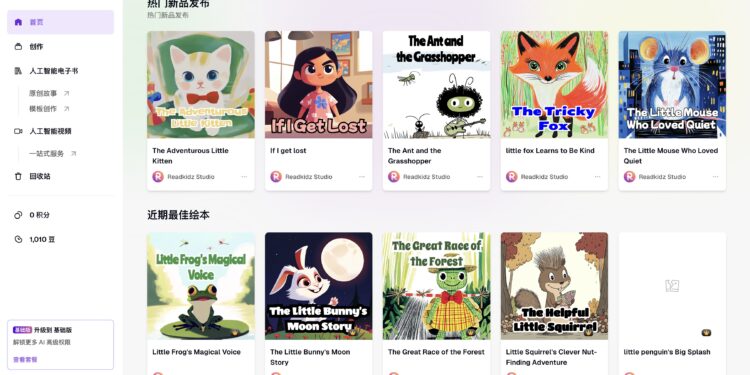
ReadKidz 是一个专为儿童内容创作设计的 AI 驱动平台,提供一站式的儿童电子图画书和多媒体故事制作功能 […]
Fish Audio 发布高级语音处理模型Fish Agent V0.1 3B,它是一个语音到语音模型,它可以 […]
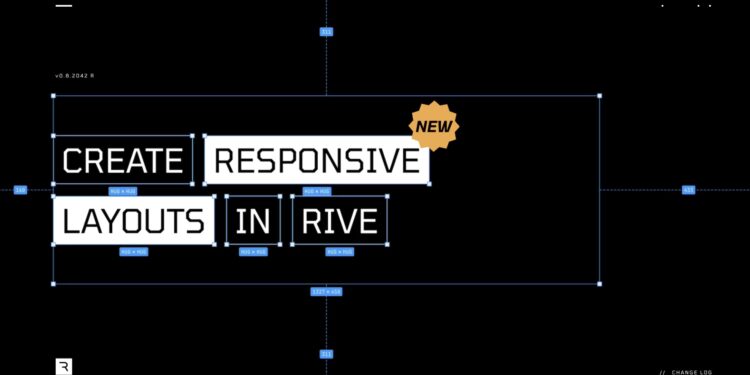
Rive 引入的新功能 Layouts 为设计师和开发者提供了一种方法,可以在各种设备上创建动态、响应式的动画 […]
腾讯发布开源 Mixture of Experts(MoE)模型:腾讯混元大模型(Hunyuan-Large) […]
腾讯推出的一体化 3D 生成框架:混元3D-1.0 ,支持从文本和图像生成 3D 内容,仅需 10 秒便可生成 […]
Hertz-dev 是由 Standard Intelligence 公司开发的首个会话音频开源模型。hert […]
Recraft推出了其最新的图像生成模型——Recraft V3。通过引入设计语言思维,Recraft V3能 […]
Act-One 是 Runway 的 Gen-3 Alpha 版本中的一款创新视频生成工具,能够通过简单的操作 […]
硬件与空间: 确保计算机上有 15GB 的可用磁盘空间。 本教程中的工具在大多数支持的硬件上运行良好,但更高性 […]
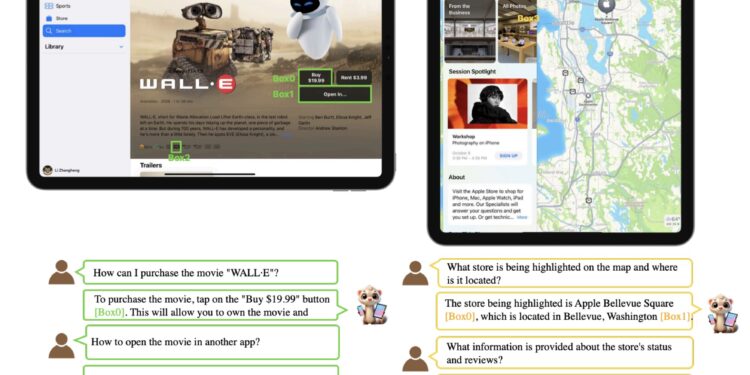
Ferret-UI是由苹果开发的一个专门理解和与移动用户界面(UI)互动的多模态大语言模型(MLLM)。 它把 […]
Physical Intelligence 公司推出了 π0(pi-zero),这是一个通用的机器人策略模型, […]
Meta FAIR(基础人工智能研究团队)公开发布了多项新研究成果,旨在推动机器人技术的发展,以实现高级机器智 […]
Claude 3.5 Sonnet发布PDF图像预览新功能,允许用户分析长度不超过100页的PDF中的视觉内容 […]
In-Context LoRA是一种新方法,用于对文本到图像的生成模型(如扩散变换器,DiTs)进行微调,使其 […]
ElevenLabs 发布了一个开源的小项目,X-to-Voice ,允许用户通过分析 Twitter 资料生 […]
OpenAI 高层 Reddit AMA 完整翻译 GPT-5 及即将推出的模型 GPT-5:今年没有发布 G […]
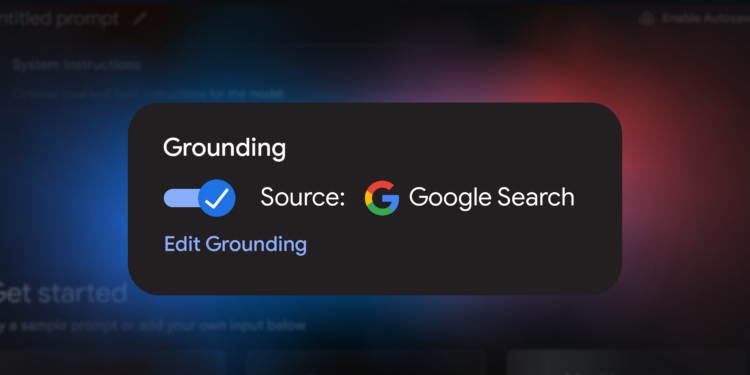
Google 宣布在其 Gemini API 和 Google AI Studio 中推出新功能“Google […]
Wonder Dynamics 推出了一项开创性的新技术——Wonder Animation,可以将传统视频片 […]
AI视频平台D-ID推出了两款新型数字人工具—Express和Premium+,专为内容创作设计,旨在让企业在 […]
DeepMind 公布其正在开发一套创新的音频生成技术细节,也就是NotebookLM背后使用的语音技术。使 […]
Ultralight-Digital-Human 是一个创新的开源项目,使得数字人在移动设备上的实时应用成为可 […]
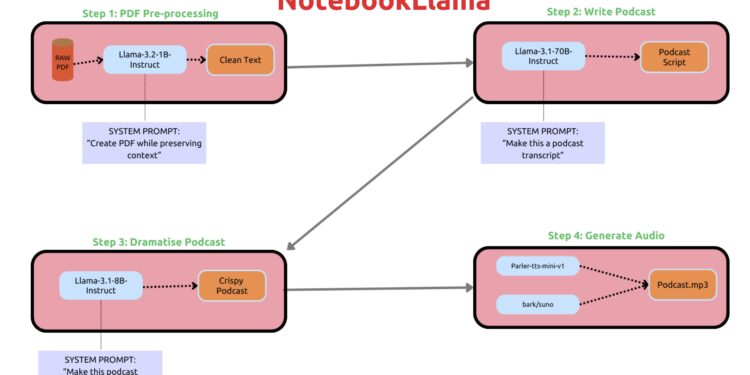
NotebookLlama 是一套用于从 PDF 文件生成播客的引导式教程,结合了文本到语音(TTS)模型的应 […]
MaskGCT(Masked Generative Codec Transformer)是一种零样本文本到语音 […]
PersonaTalk 是由字节跳动开发的一种专为实现高保真和个性化视觉配音的技术框架,也就是专门用来给视频人 […]
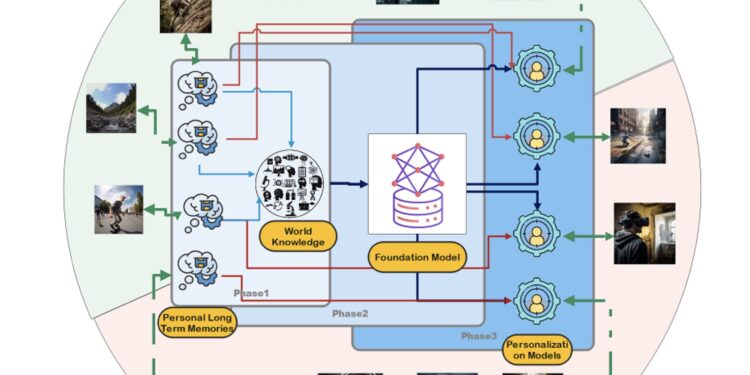
长期记忆(LTM)是AI自进化的核心,它允许模型通过与环境的持续交互,累积并存储经验数据。这些数据可以在未来的 […]
Google DeepMind 发布了一项新的生成式 AI 技术,这项技术被应用在了 MusicFX DJ 和 […]
Cloudflare推出了一个新的开发工具:Workflows。的持久执行引擎,目前已进入公开测试阶段。这项工 […]
前天,Claude 才发布 Computer Use,让AI可以像人一样操控你的电脑来干活,已经很炸裂了。 这 […]








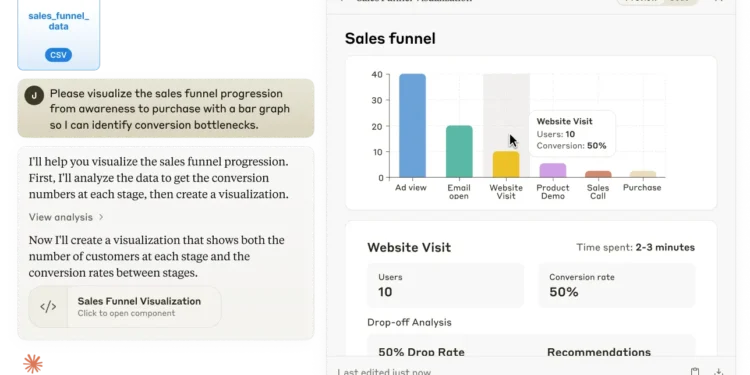










苹果发布 Final Cut Pro 11,这次重大更新为专业视频编辑带来了先进的 AI 驱动功能、空间视频编 […]