SndHound AI 和 Perplexity 正合作,将 Perplexity 的在线大语言模型(LLM) […]
Gemma-10M 模型使用一种称为 Infini-Attention 的技术,将 Gemma 2B 的上下文 […]
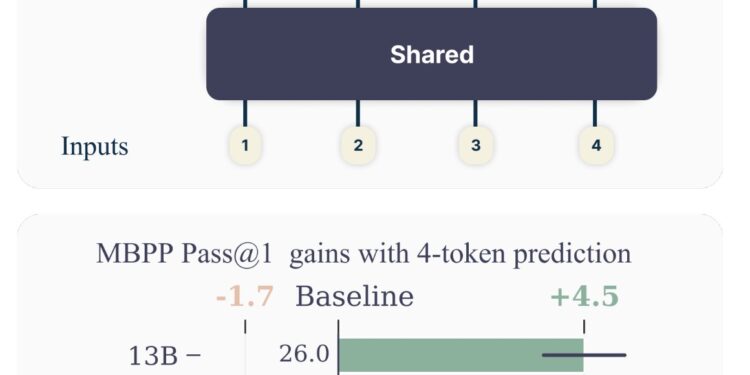
Meta AI发表了一篇论文,研究了一种新的训练大型语言模型的方法,即通过预测多个未来标记来提高模型的效率和性 […]
Llama3 中文聊天项目综合资源库,集合了与Llama3 模型相关的各种中文资料,包括微调版本、有趣的权重、 […]
AniTalker通过一个静态的肖像画和输入音频,生成生动多样的说话面部动画视频。该框架不仅仅着重于嘴唇同步这 […]
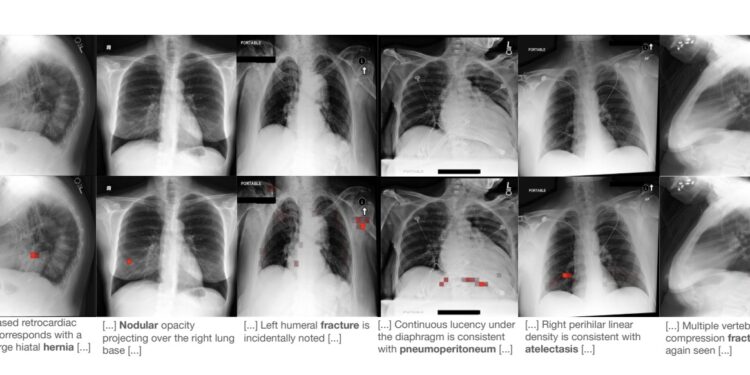
RayDINO 是一个基于人工智能的视觉模型,专门设计用于分析胸部X光图像。它采用了自监督学习方法,它可以在没 […]
TimesFM 是一种用于时间序列预测的先进工具。简单来说,时间序列预测就是基于过去的数据来预测未来事件的发生 […]
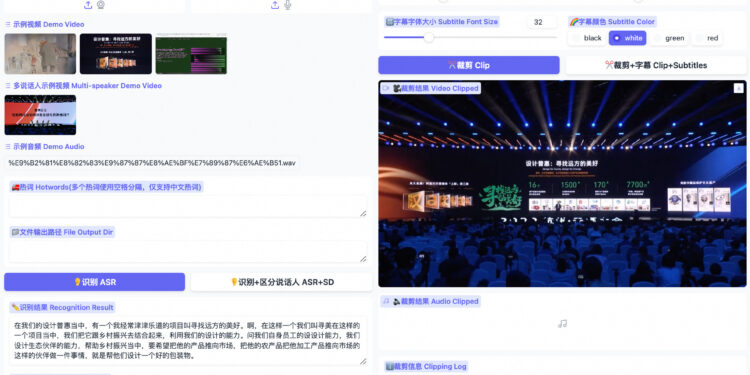
FunClip 是阿里巴巴通义实验室开源的一款视频剪辑工具,专门用于精准、便捷的视频切片。 它能够自动识别视频 […]
Refuel AI 最近推出了两个新版本的大语言模型 RefuelLLM-2 和 RefuelLLM-2-sm […]
宇树科技发布 Unitree G1 人形机器人,超大关节运动角度,23~34 个关节,结合力位混合控制,灵敏可 […]
VimTS,一种先进的文本检测工具,专门设计用于同时处理视频和图像中的文本。它通过一种新的方法来提高视频和图像 […]
RAFT(Retrieval Augmented Fine-tuning)是一种新的技术方法,用于改善大语言模 […]
OpenAI 刚刚发布了 GPT-4o,这是一种新的人工智能模式,集合了文本、图片、视频、语音的全能模型。 能 […]
混元DiT是腾讯推出的一款先进的文本到图像生成模型,它基于扩散变换器(Diffusion Transforme […]
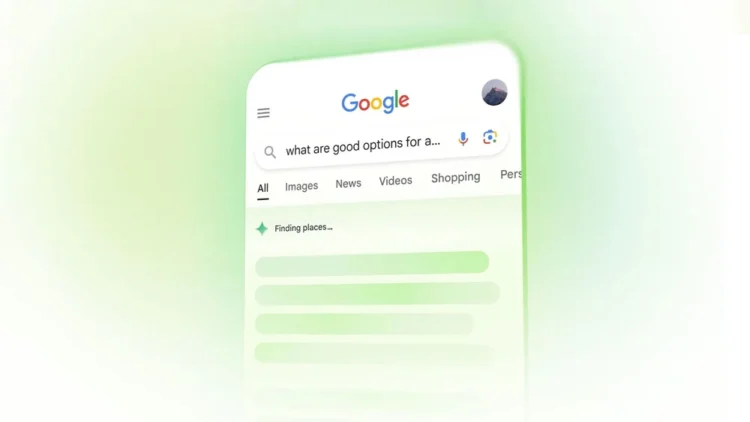
Google 在其 2024 年 Google I/O 大会上发布的搜索中引入生成式 AI 的新功能。这些功能 […]
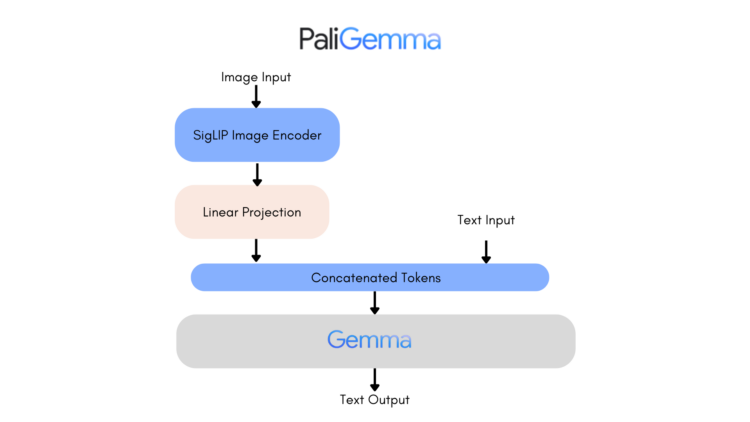
PaliGemma是一个开放的视觉语言模型(VLM),受PaLI-3启发,基于SigLIP视觉模型和Gemma […]
苹果公司今天宣布将于今年晚些时候推出新的辅助功能,其中包括眼动追踪(Eye Tracking)、音乐触感(Mu […]
通过手持式夹持器和精心设计的接口进行数据收集。 UMI可以将人类在复杂环境下的操作技能直接转移给机器人,无需人 […]
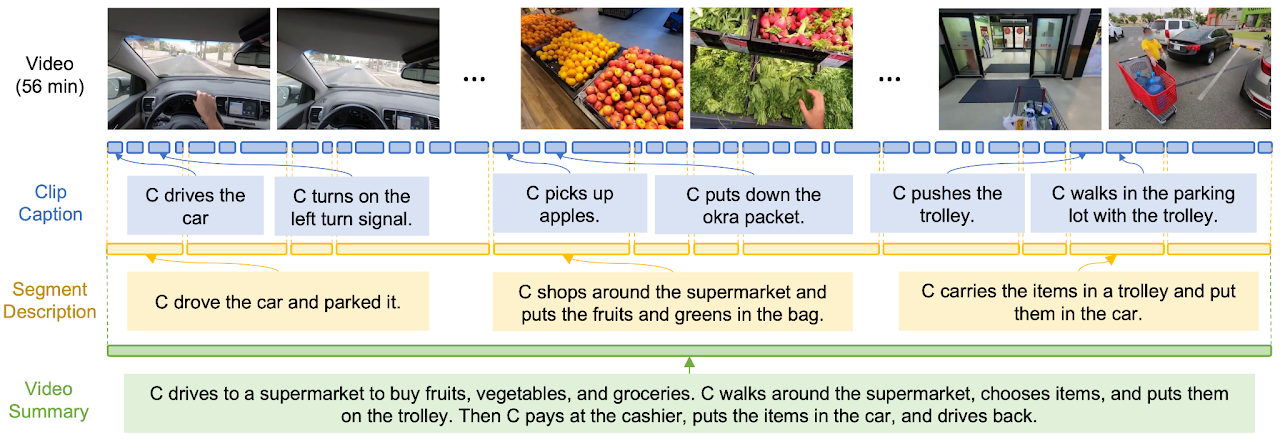
ReCap是一个创新的递归式视频字幕模型,能够自动分析视频内容,并在不同的时间层级上(如短片段、中等长度段落和 […]
Genie能够从单一图像提示生成无限种可玩(即可通过行动控制的)游戏场景。 这些图像可以是合成图像、真实照片, […]
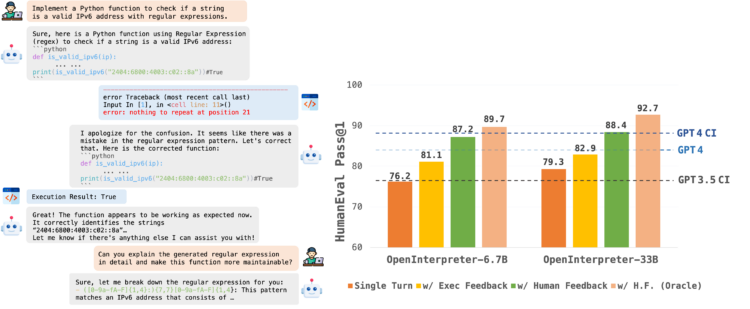
OpenCodeInterpreter与之前的代码解释器不同的是,它不仅可以生成代码,还能根据人类的反馈学习如 […]
STORM(Synthesis of Topic Outlines through Retrieval and […]
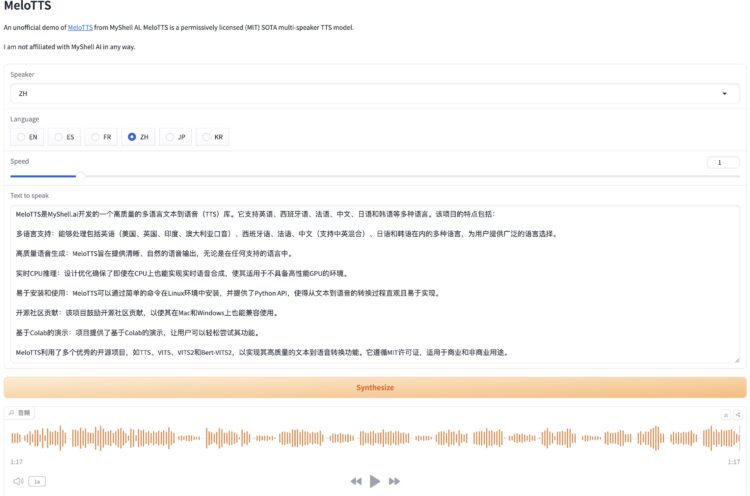
MeloTTS是MyShell.ai开发的一个高质量的多语言文本到语音(TTS)库。它支持英语、西班牙语、法语 […]
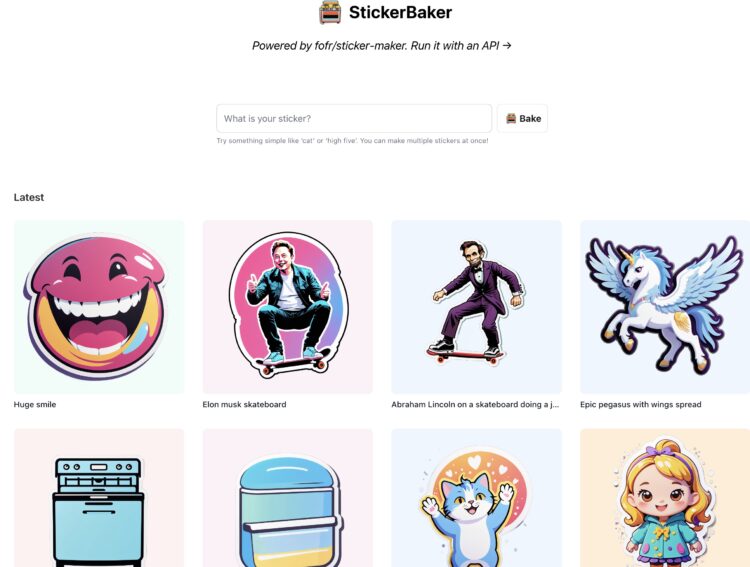
一个开源的「贴纸生成器」 输入文字提示,即可在几秒钟生成一个精美的贴纸 Support authors and […]
MobiLlama:一个0.5B大小 能在手机上运行的小型语言模型 该模型基于LLaMA-7B架构设计,旨 […]
通过根据给定的文本提示、和弦序列、旋律线索、音乐主题或形式等条件。 ChatMusician能自动生成结构 […]
该项目由阿里巴巴开发,利用单张图像和音频输入(如说话或唱歌),EMO能够生成具有表情变化和头部动态的虚拟人像视 […]
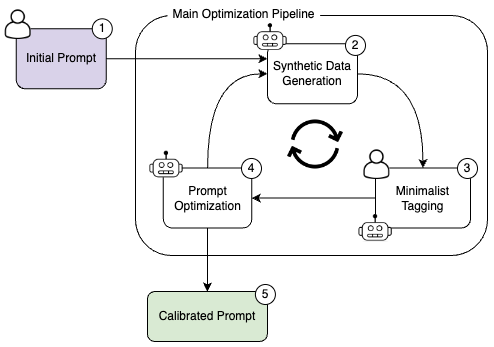
AutoPrompt 是一个专为优化提示而设计的框架,目的是改善和完善在真实世界应用场景中使用的提示。这个框架 […]
StarCoder2拥有三种不同规模的模型,参数量分别为3B、7B和15B。特别地,15B参数的StarCod […]
LTX Studio是一个创新的平台,通过整合人工智能技术与视频制作过程,为创意人士提供了从概念构思到最终编辑 […]


















SndHound AI 和 Perplexity 正合作,将 Perplexity 的在线大语言模型(LLM) […]