Morph Studio最近引入了一个创新的工具,允许用户将Stability AI生成的视频片段编织成一部电 […]
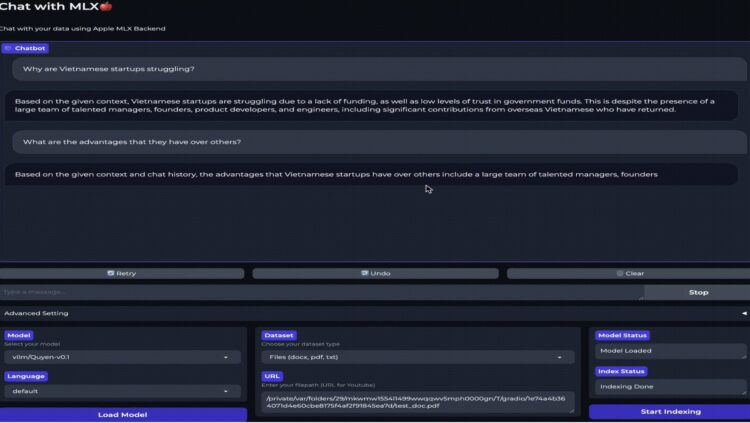
Chat-With-MLX是利用苹果MLX Framework实现的一个高效、多语言支持进行检索增强生成(RA […]
Concordia是由Google DeepMind开发的一个创新性工具 它利用大语言模型可以构建和模拟具 […]
由于东南亚(SEA)地区语言多种多样,大多数现有的模型无法满足该地区需求。 Sailor基于Qwen 1. […]
兄弟们,你猜我发现了什么 原来OpenAI 3年前就开始搞AI音乐生成了 OpenAI在2019年8月 […]
OLMo(Open Language Model)与其他开源语言模型的不同之处在于其“完全开放的框架”。 […]
在文本到图像生成的领域中,精确渲染特定元素(如独特字符或风格)是一大挑战。现有的方法在有效组合多个低秩适应(L […]
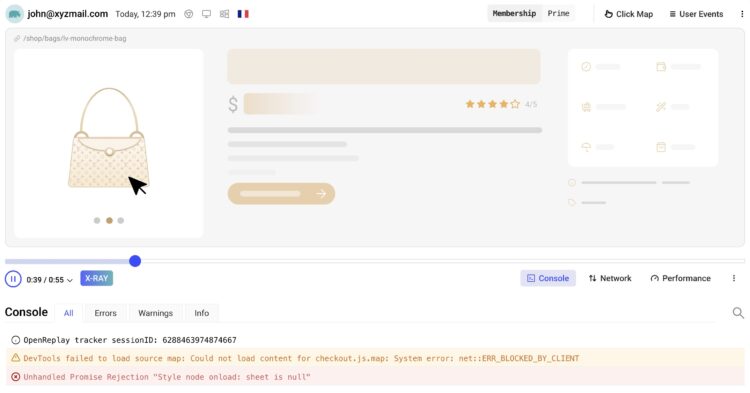
OpenReplay:用户操作记录回放 OpenReplay是一个自托管的会话回放和分析的开源工具,可以让 […]
Easy Scraper 是一个在Chrome 免费网页抓取扩展,只需一次点击从任何网站抓取数据。使得数据抓取 […]
它可以将屏幕截图转换为干净的代码,支持HTML/Tailwind CSS、React、Bootstrap或Vu […]
人像照明重塑(Portrait Relighting)是一种数字图像处理技术,它允许在不改变原始拍摄环境的情况 […]
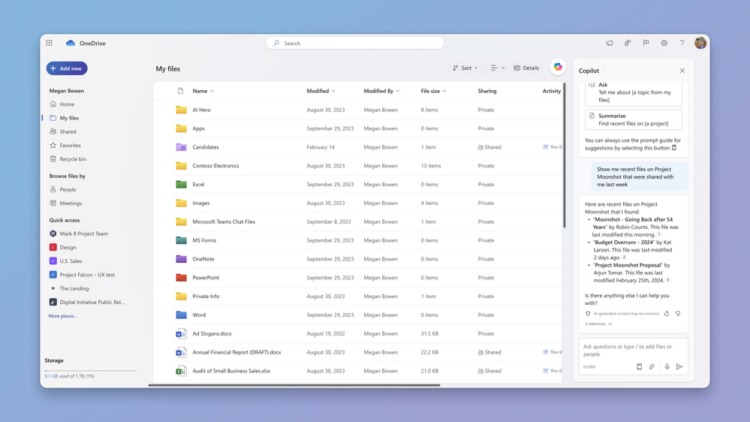
微软将在4月下旬发布OneDrive Copilot。 OneDrive Copilot将扮演类似研究助理的角 […]
DataDreamer是一个开源Python库,旨在简化大型语言模型(LLM)的集成和使用。在现代应用中,从合 […]
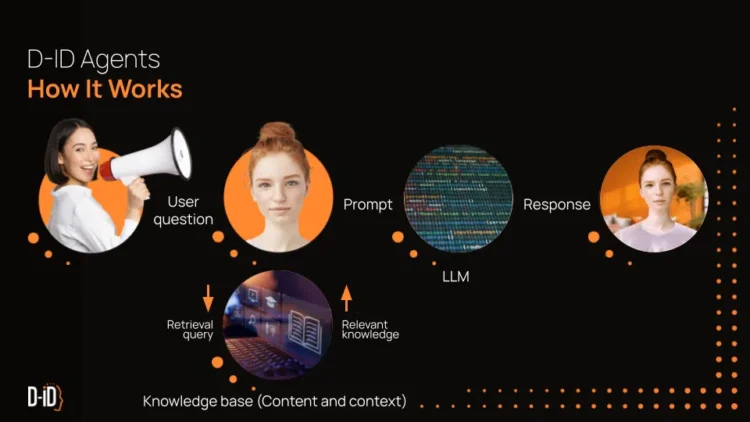
D-ID推出D-IDAgent功能:克隆自己的数字分身 选择一个形象或者上传自己照片,上传自己的声音或克隆 […]
Verce发布新的AI SDK 3.0 推出生成式UI功能 这是一种开源的生成式UI技术,允许开发者创建丰富的 […]
Multimodal ArXiv是一个旨在提高大型视觉语言模型(LVLMs)科学理解能力的数据集项目。该项目由 […]
Relightful Harmonization是由Adobe和纽约大学合作开展的一项研究项目,这项技术的核心 […]
Stability AI 与 Tripo AI 合作开发了 TripoSR,这是一个受到最新研究 LRM(大型 […]
Anthropic公司宣布推出Claude 3模型系列,性能全面超越GPT4,具有多模态度能力,推理能力和人类 […]
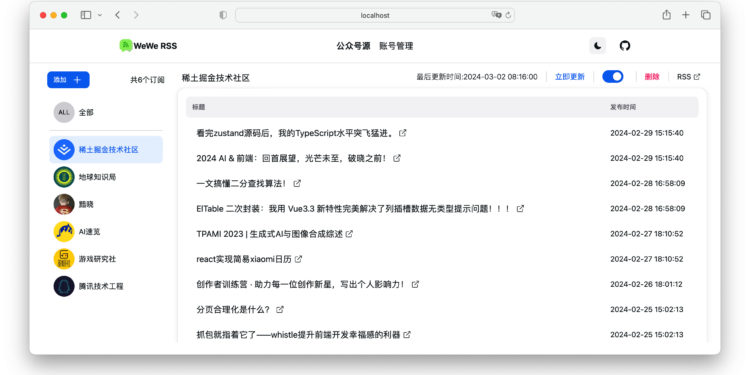
WeWe-RSS是一个开源项目,旨在提供一种更优雅的微信公众号订阅方式。它支持私有化部署以及基于微信读书的微信 […]
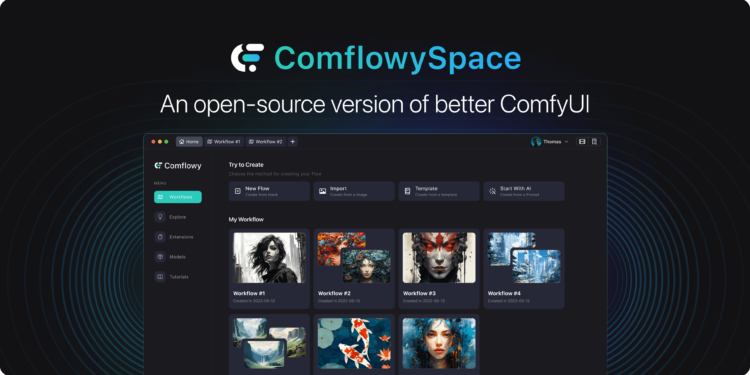
Comflowyspace是一个用于生成AI图像和视频的开源工具,它比现有的SDWebUI和ComfyUI更易 […]
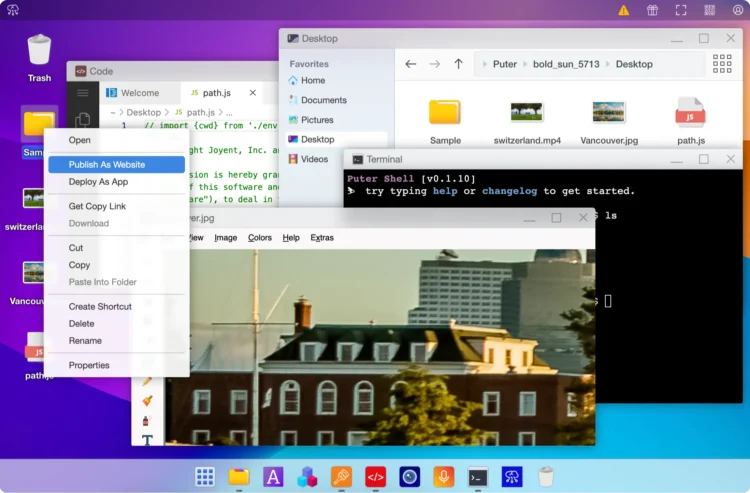
Puter项目是一个高级的开源浏览器内桌面环境,旨在提供丰富的功能、异常快速的性能和高度的可扩展性。它可以用于 […]
Stability AI发布了关于Stable Diffusion 3(SD3)的研究论文,揭示了这一最新模型 […]
PixelPlayer:MIT的研究团队开发的项目,能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。 […]
该项目由字节跳动开发,DiffusionGPT的牛P之处在于它集成了多种领域的专家图像生成模型。 然后使用LL […]
Pika近日宣布推出新功能Lip Sync,此功能允许用户为视频添加语音对白,并通过ElevenLabs支持实 […]
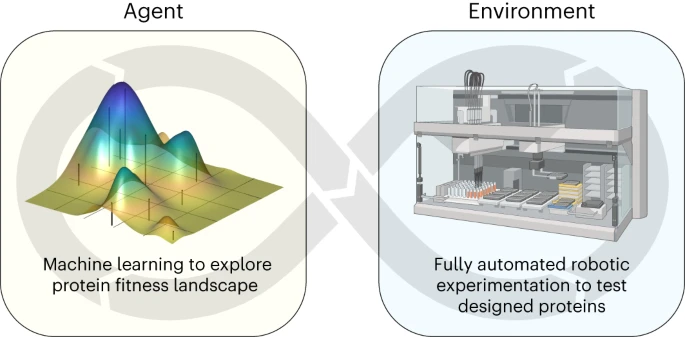
SAMPLE可以自己设计和测试新的蛋白质,而不需要人类的帮助。就像一个能自己做实验的机器人科学家。 它能自主学 […]
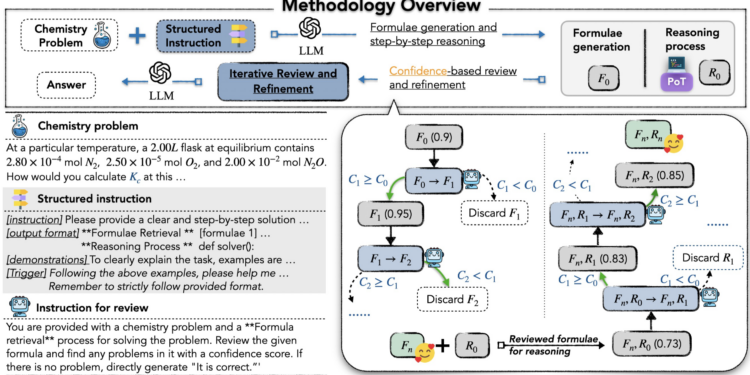
STRUCT CHEM是为了解决大语言模型(LLMs)在复杂化学问题推理中遇到的挑战而设计的一种策略。虽然LL […]
AtomoVideo是一个创新的高保真图像到视频生成框架,由阿里巴巴团队开发。这个框架能够从给定的静态图像生成 […]
Marker 能将 PDF、EPUB 和 MOBI 文件转换成 markdown 格式。它的转换速度是 nou […]


















Morph Studio最近引入了一个创新的工具,允许用户将Stability AI生成的视频片段编织成一部电 […]