加拿大国防部和加拿大武装部队发布了一个人工智能(AI)战略,目标是到2030年,利用AI技术改善他们的工作和操 […]
Inflection AI发布Inflection-2.5版本模型 只用了四成功力就匹敌GPT 4性能,具有高 […]
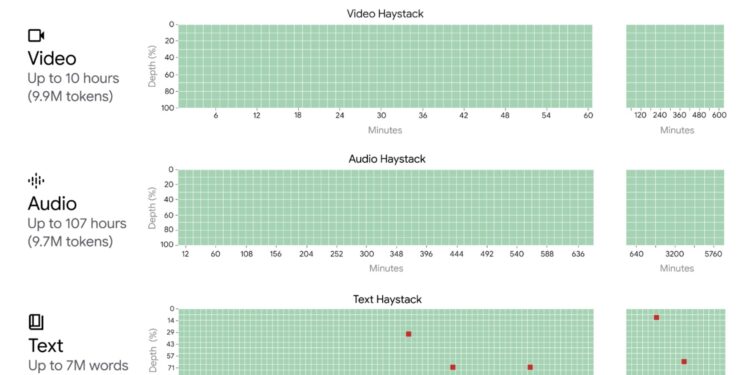
Gemini 1.5 Pro 是由 Google Gemini 团队开发的一款多模态混合专家模型,它标志着人工 […]
ELLA(Efficient Large Language Model Adapter)是由腾讯开发的一个先进 […]
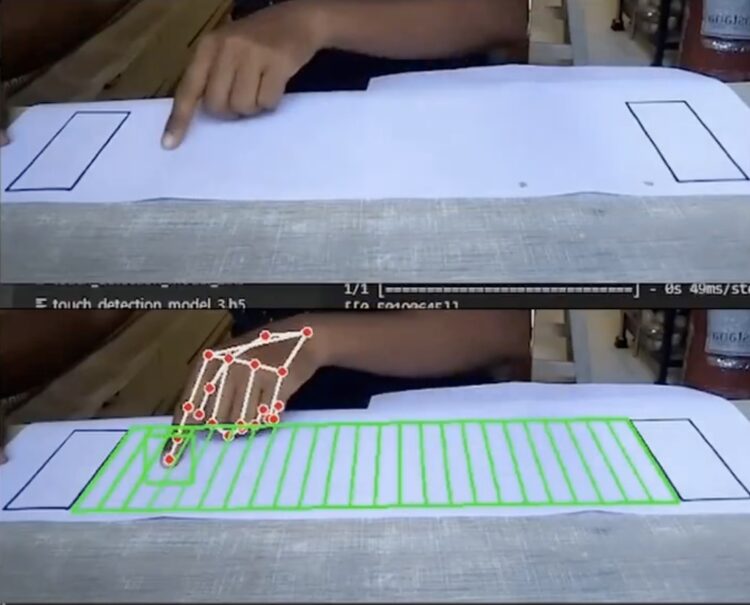
Paper Piano,通过摄像头捕捉手指的运动,在纸张上实现弹钢琴的功能,让人们无需购买真正的钢琴即可演奏音 […]
Midjourney 角色人物一致性功能上线 适用于 MJ6 和 Niji6 型号 Support autho […]
Google发表了一篇论文,介绍了一种新型的模型窃取攻击方法,这种方法能够从像OpenAI的ChatGPT或G […]
YOLOv8:目标检测跟踪模型 YOLOv8能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移 […]
NVIDIA推出了面向生成式AI和大语言模型(LLMs)的认证项目,名为NCA Generative AI L […]
Command-R是Cohere推出的一种新型大语言模型,旨在实现可扩展的生成模型,专注于检索增强生成(RAG […]
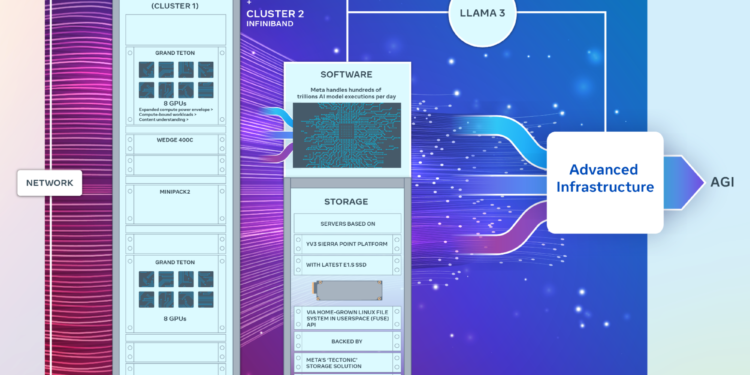
Meta 正在打造一套超大规模的人工智能计算平台,他们宣布推出了两个包含 24000GPU 的集群。这些不是普 […]
Cognition 实验室发布了 世界上第一位完全自主的 AI 软件工程师:Devi。 具备自学新语言、开发迭 […]
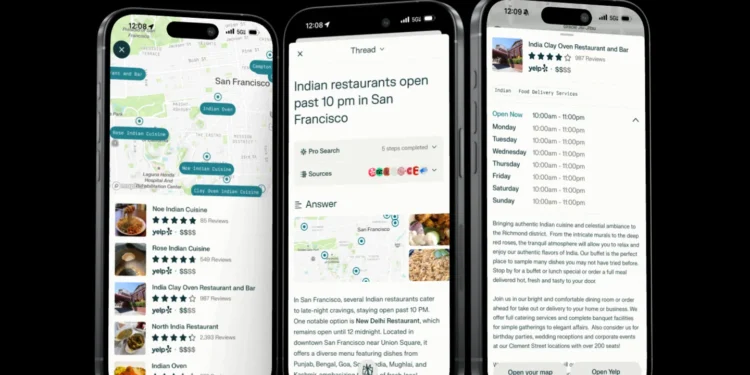
Perplexity 将 Yelp 的评论数据融入到其聊天机器人服务中 当你在考虑去哪家咖啡厅时,Perple […]
Hotshot ACT-1:一个全新、出色的文本转视频模型 ACT 1 能够以不同的宽高比产生高清视频 Sup […]
OpenAI 的 Superalignment (超级对齐)团队开发开源了一款工具:Transformer D […]
Figure 展示了他们与OpenAI合作的最新进展,炸裂了 Figure 01接入ChatGPT后获得了惊人 […]
Deepgram 推出了名为 Aura 的全新文本转语音(TTS)API,这是为实时对话 AI 代理和应用程序 […]
OpenAI的首席技术官Mira Murati在接受华尔街日报采访时关于OpenAI的视频生成模型Sora的详 […]
VLOGGER是一个利用文本和音频驱动的方法,可以从人的单张照片生成说话的人视频。 给定一张人的单张输入图像和 […]
Reor:一个基于AI的开源桌面笔记应用 Reor可以作为个人知识管理工具,帮助你构建自己的“第二大脑”。 S […]
ChatMusician: 能够理解和生成音乐的大语言模型 通过根据给定的文本提示、和弦序列、旋律线索、音乐主 […]
Follow-Your-Click是一个开放领域区域图像动画项目,该项目由来自香港科技大学(HKUST)、腾讯 […]
一、获得更好结果的六种策略 写清楚说明(Write clear instructions) 提供参考文本(P […]
Muse Pro 是一款专为iPad设计的实时画图应用,通过结合先进的人工智能技术,提供了一种全新的创作体验。 […]
Cartwheel:一个文本转3D动画工具 只需输入文字提示即可生成视频、游戏、电影、广告、社交或 VR 项目 […]
Glyph-ByT5项目是由微软亚洲研究院、清华大学、北京大学以及澳大利亚国立大学的研究人员共同开展的。该项目 […]
在2021年夏天,OpenAI宣布关闭其机器人团队,原因是缺乏必要的数据来训练机器人如何使用人工智能进行移动和 […]
Captury:无标记运动捕捉技术 Captury 发明了一种3D体积扫描技术:CapturyDome,它 […]
MM1模型是一个高性能的多模态大语言模型(MLLM),旨在处理和理解图像和文本数据。该模型通过大规模的预训练, […]
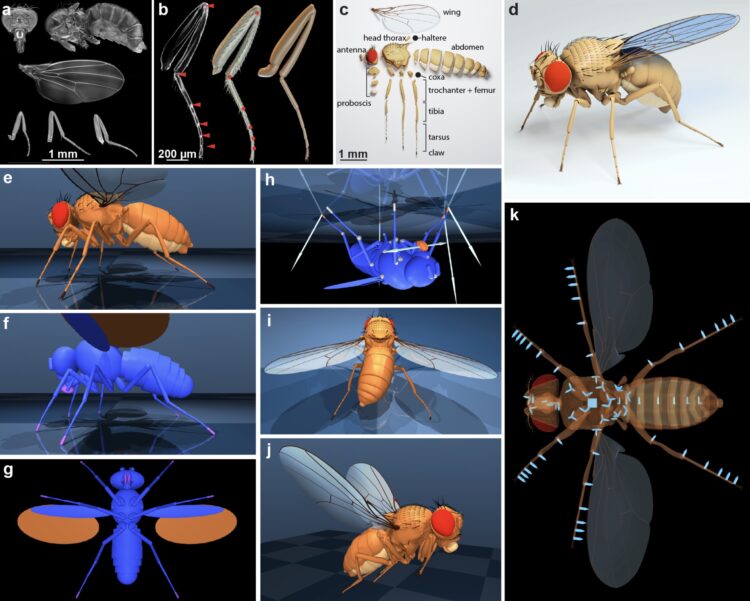
Janelia和Google DeepMind的科学家通过将人工智能融入一个虚拟果蝇模型中,创建了一种能够像真 […]








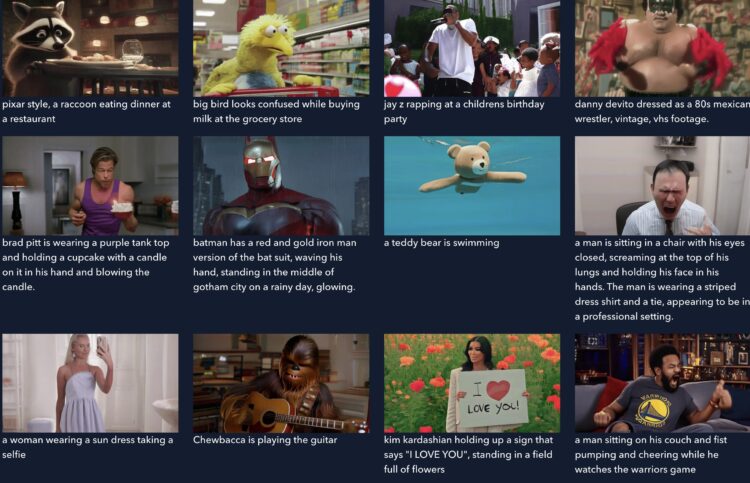












加拿大国防部和加拿大武装部队发布了一个人工智能(AI)战略,目标是到2030年,利用AI技术改善他们的工作和操 […]