支持小红书、抖音、快手、B站和微博等平台的视频、图片、评论、点赞和转发等信息的抓取。 可以指定特定数据抓取、集 […]
Cerebras Systems 推出全球最快的人工智能芯片:WSE-3 拥有高达4万亿个晶体管 关键规格 […]
EVE(Emu Video Edit)是Meta AI开发的一个视频编辑模型 EVE模型通过结合先进的图像处理 […]
奥特曼:“许多创业公司觉得GPT-5会有提升,这将为他们提供更多的商业机会。 但这是一个错误的假设,如果按 […]
一个基于 AI 的全身运动捕捉和扩展现实(XR)解决方案,通过在线系统动画师(System Animator) […]
Animagine XL 3.1是Animagine XL V3系列的最新更新,是一个开源的动漫主题文本到图像 […]
NVIDIA宣布了Project GR00T,这是一个旨在推进机器人学和具体化人工智能(AI)突破的通用基础模 […]
英伟达发布全新Blackwell GPU计算平台 🚀 2080亿个晶体管 💨 每秒10TB数据传输速度 Sup […]
MindEye2是一个利用功能磁共振成像(fMRI)数据实现从大脑活动到图像重建的研究项目。该项目通过预训练和 […]
将任意面部图片转换成用户指定的另一个图像。这一转换过程不仅增强了图像处理的创造性和多样性,而且为用户提供了一种 […]
Halim Alrasihi 分享了Midjourney中如何通过角色权重来控制角色一致性,角色权重可以极大地 […]
Allar Haltsonen (@bubblez_jazzy) 分享的Midjourney“角色参考(Cha […]
广告食品摄影 @CharaspowerAI 在X上分享了他使用Midjourney 来进行食品广告摄影的案例 […]
Allar Haltsonen (@bubblez_jazzy) 介绍了“解锁Midjourney工作流程 ” […]
字节跳动的AnimateDiff-Lightning发布 AnimateDiff-Lightning能够更快地 […]
APISR:专注于动漫图像的超分辨率 APISR可以提升动漫图像、视频的分辨率 Support authors […]
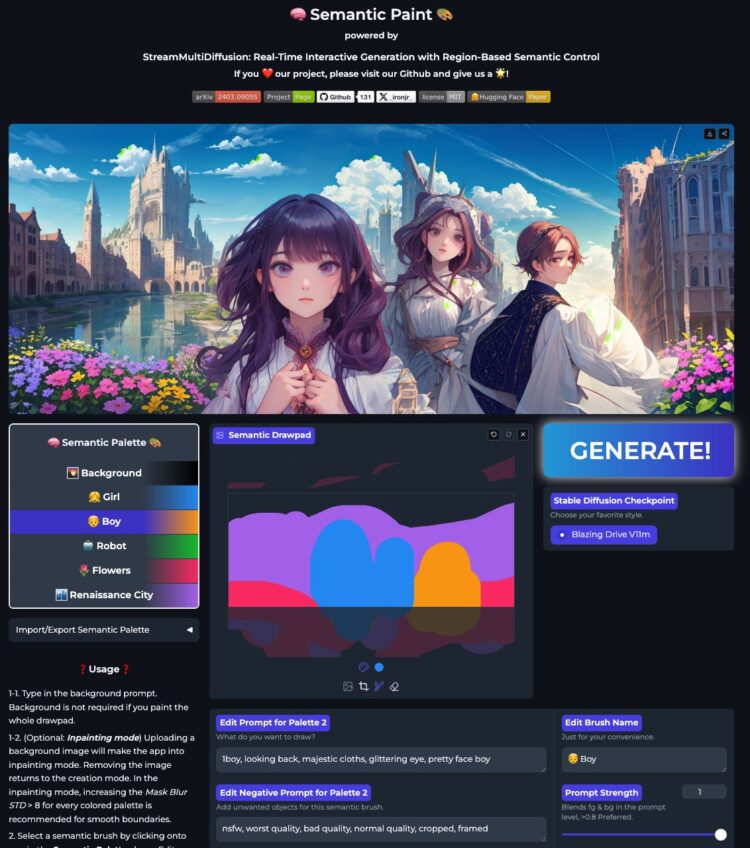
StreamMultiDiffusion:一个使用区域文本提示来实时生成图像的项目。 也就是你可以通过在多个特 […]
manga-image-translator,一个开源工具,专门用于翻译漫画或图片中的文字。 利用高效的O […]
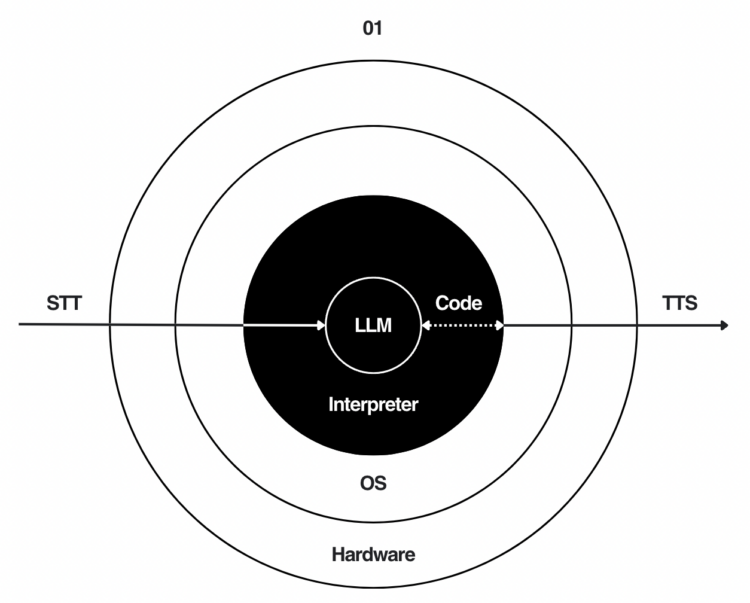
O1 Lite设备介绍: O1 Lite是一款通过语音操作计算机的设备,可连接Wi-Fi或热点,实现全端口接入 […]
FRESCO能够在不需要额外训练的情况下,直接对视频进行编辑和风格转换 同时保留视频动作和情节的自然流畅。 […]
Stability AI 推出一套全面的 API 服务 提供: Support authors and sub […]
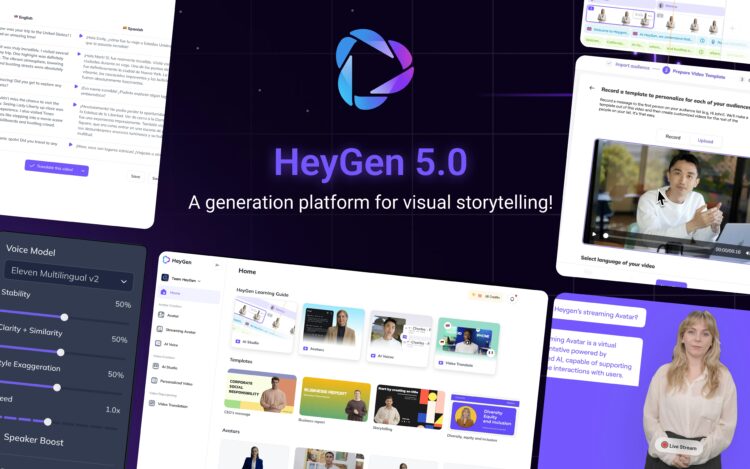
HeyGen 发布5.0版本 整合了所有功能 5.0推出了全新的用户界面设计,使用户能够更容易地导航和使用平台 […]
Suno v3发布:可以生成2分钟的广播级音乐歌曲 🎵 完整歌曲制作:根据文字提示几秒钟内生成2分钟歌曲 Su […]
Freepik推出了一款名为Reimagine AI工具 Reimagine允许用户上传图片,自动生成提示词, […]
Viggle.ai 是一个可控制视频生成工具,允许用户通过简单的命令为静态角色创建动画。其核心技术基于JST- […]
Gatekeep:一个新型的文本转视频 AI,专注与教学 它可以通过文本提示将数学、物理问题转换成视频内容 S […]
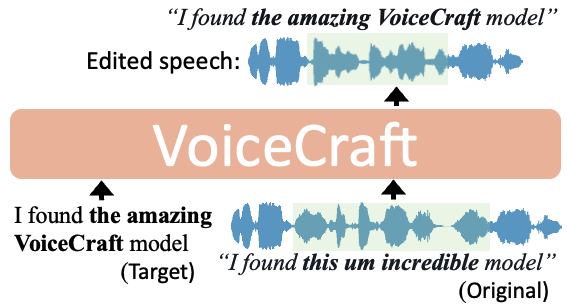
VoiceCraft是由德州大学奥斯汀分校和Rembrand的研究团队开发的高级语音技术。它主要做两件事:一是 […]
微软最近推出了其AI驱动的助手——Copilot,旨在通过一系列先进功能提升用户的生产力。以下是如何利用这些新 […]
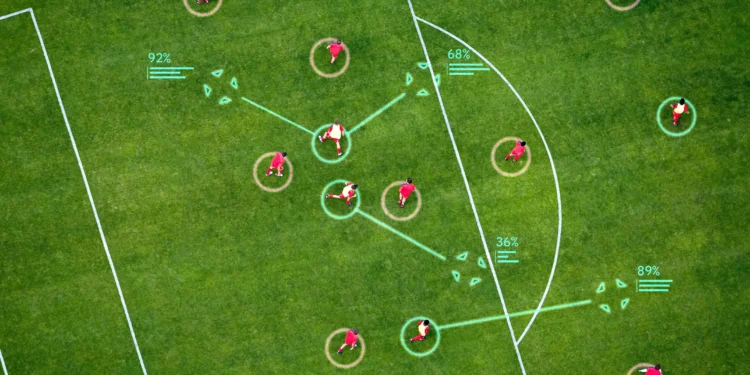
TacticAI是Google DeepMind开发的一款人工智能助手,专为足球战术设计。它旨在通过预测和生成 […]
Halim Alrasihi分享了关于在Midjourney解锁的下一级角色模型(Character Mock […]























支持小红书、抖音、快手、B站和微博等平台的视频、图片、评论、点赞和转发等信息的抓取。 可以指定特定数据抓取、集 […]