“Develop in Swift”教程通过一系列精心设计的章节和项目,教授开发者如何使用 Swift、Swi […]
Pipedream是一个为开发者设计的服务平台,它提供了一个强大的集成和自动化工具,使开发者能够轻松连接和自动 […]
据《纽约时报》报道,Meta将在4月为其Ray-Ban智能眼镜引入一系列相当强大的AI功能。 这些新功能将 […]
Polaris是由Hippocratic AI 开发的一款高度专注于安全、用于医疗保健的大语言模型(LLM)系 […]
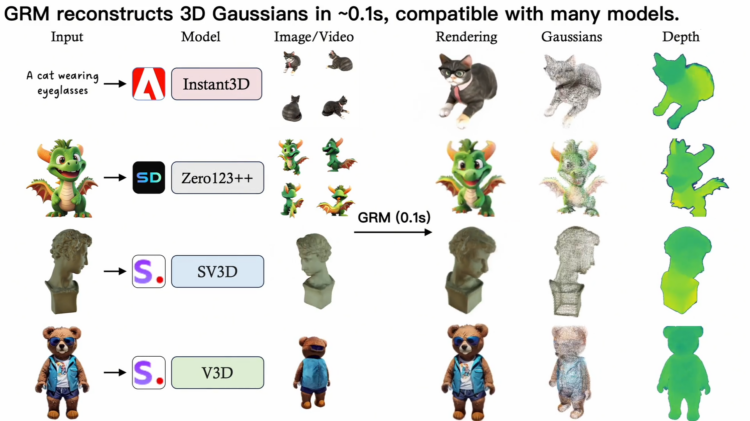
GRM(Large Gaussian Reconstruction Model)是一个用于3D重建和生成的大型 […]
微软对Azure AI语音服务的Personal Voice功能进行了升级,引入了新的零样本学习(zero-s […]
Google和纽约大学的研究人员,介绍了一种将大语言模型(LLMs)的专门化的方法,并提出了一种三步设计模式。 […]
Adobe推出Firefly服务,这是一套超过20种新的生成和创意API、工具和服务。Firefly 服务使企 […]
ACE Studio是一个先进的AI人声合成引擎,它的目标是制作听起来像真人一样自然和充满感情的歌声。为了做到 […]
该项目开发了一种新型的动画填色桶彩色化技术,项目由南洋理工大学的S-lab团队开发,旨在简化动画着色过程。 主 […]
斯坦福医学院的研究人员开发了一个新的人工智能模型,SyntheMol,该模型能够为化学家创建合成药物的配方,以 […]
Harvey与OpenAI合作,为法律专业人士构建了一个定制训练的案例法模型。该模型是具有复杂推理、广泛领域知 […]
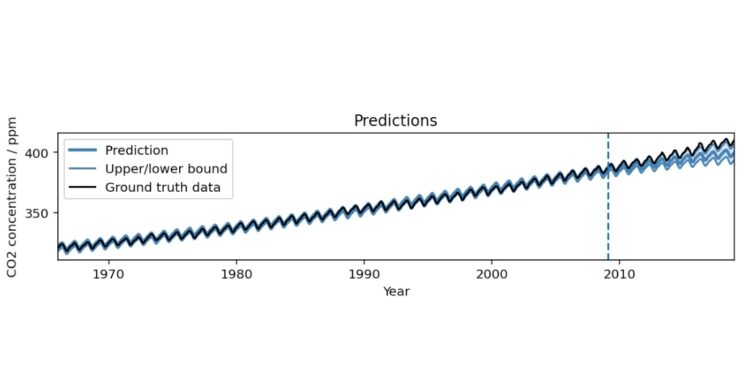
时间序列问题在许多领域都很常见,例如,预测天气和交通模式,理解经济趋势等。这些问题涉及分析按时间顺序排列的数据 […]
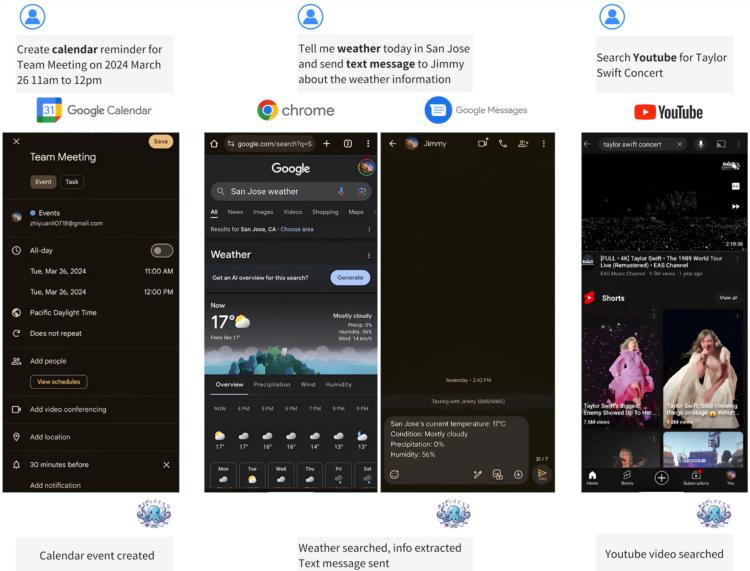
苹果研究人员开发了一种新型人工智能系统,它能理解屏幕上下文和含糊不清的提法从而改善与语音助手的交互,使得与语音 […]
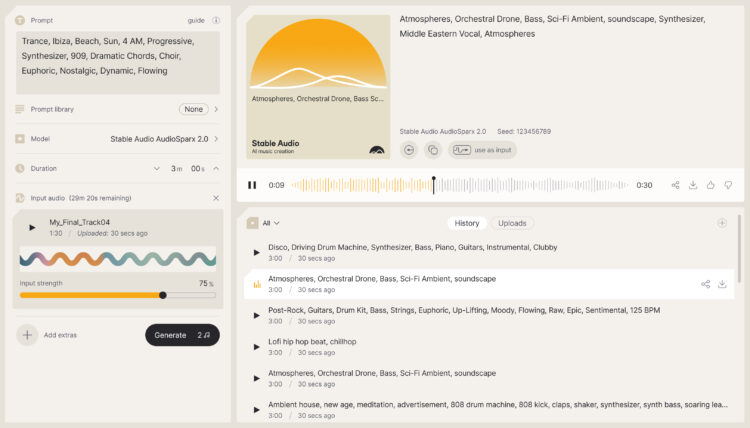
Stability AI宣布推出Stable Audio 2.0,这是一个新型模型,能从单一的自然语言提示生成 […]
《Generative AI for Beginners》是由Microsoft Cloud Advocate […]
200 多位知名音乐人签署了一封公开信 呼吁阻止AI对人类创造力的攻击😄 估计是Suno 3.0的发布让音 […]
一款低成本的机器人手臂,成本大约为$250。该项目还包含如何构建第二个机器人手臂(领导手臂),用以控制另一个手 […]
Infinity AI :一个神奇的AI 工具 Infinity AI致力于开发以人为中心的生成式视频模型。在 […]
Octopus-V2-2B是由斯坦福大学Nexa AI开发的一种先进的开源大型语言模型,具有20亿参数,专为A […]
这些资源包括基础教程、编程和提示工程课程、生成性人工智能和 Google 云工具课程、以及 Udemy 和 C […]
InstantStyle是一个基于扩散模型的文本到图像生成框架,专门设计来保持图像生成中的风格一致性。Inst […]
Microsoft和量子计算公司Quantinuum共同报告,他们已经成功开发出一种前所未有的可靠量子计算机, […]
Exactly.ai是一个高级AI艺术作品创作平台,专为艺术家设计。它使用AI来理解艺术家的风格,并基于简单的 […]
阿里巴巴推出Qwen1.5-32B 模型 Qwen1.5-32B 是Qwen1.5语言模型系列的最新成员,这个 […]
Higgsfield.ai 正在开发一个基础视频模型,这是一种先进的AI系统,专为视频内容创作而设计,目的是为 […]
“Tool use (function calling)是Claude一个特定功能,允许它与外部客户端工具和函 […]
这篇论文展示了语言模型(LMs)可以通过吸收(即融合)来自同源模型的参数来获得新的能力,这个过程不需要重新训练 […]
Lixel CyberColor (LCC) 是由 XGRIDS 公司开发的一款先进技术产品,旨在自动生成大规 […]
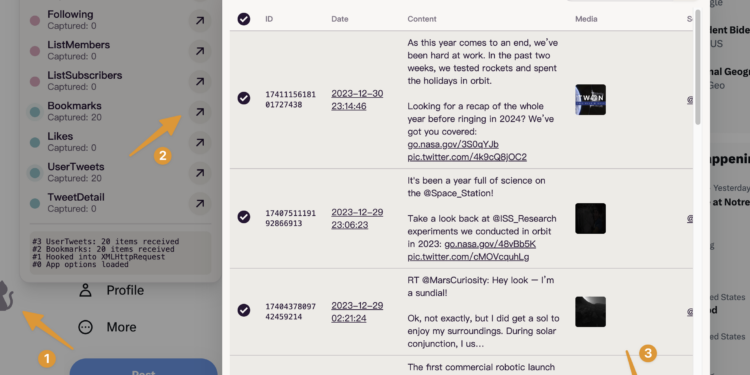
Twitter-web-exporter:一键导出推文、书签、列表 一个开源工具,可以直接在浏览器运行。 […]

















“Develop in Swift”教程通过一系列精心设计的章节和项目,教授开发者如何使用 Swift、Swi […]