

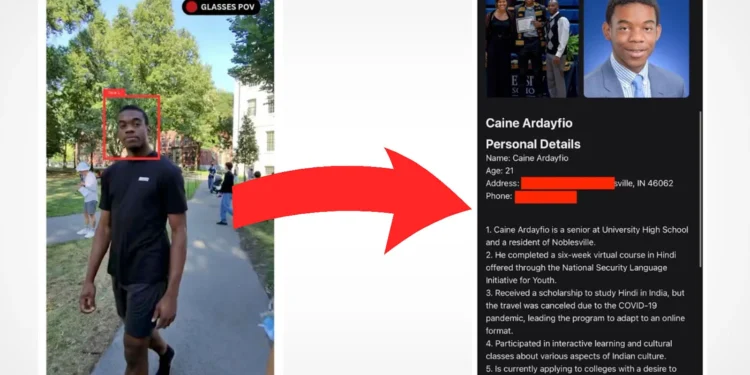
PimEyes :人脸识别搜索引擎和反向图像搜索工具 上传照片帮你追踪照片上的人
PimEyes 是一个人脸识别搜索引擎和反向图像搜索工具,旨在帮助用户找到哪些网站发布了他们的照片。它允许用户 […]
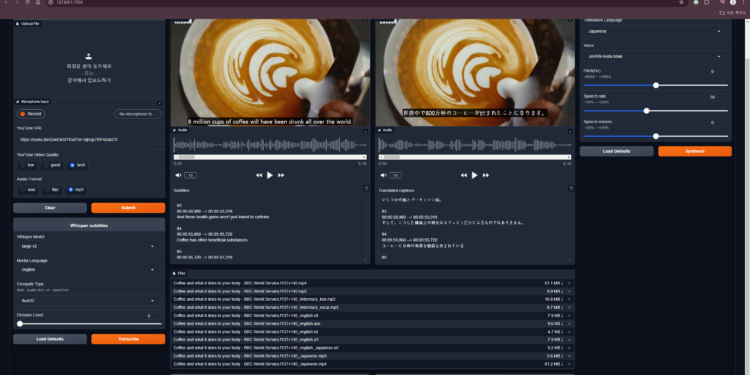



Ebook2Audiobook:将电子书自动转换为有声书 支持语音克隆、多种语言
ebook2audiobookXTTS 是一个开源项目,旨在将电子书自动转换为有声书,并支持多种语言、语音克隆 […]





![Black Forest Labs 发布其最新的图像生成模型 FLUX1.1 [pro] 生成速度快6倍](https://www.linkshub.net/wp-content/uploads/other/aizx/2024-10-04/ff823388edf5e5cc5c77e62cfe0cfa6c.jpg)

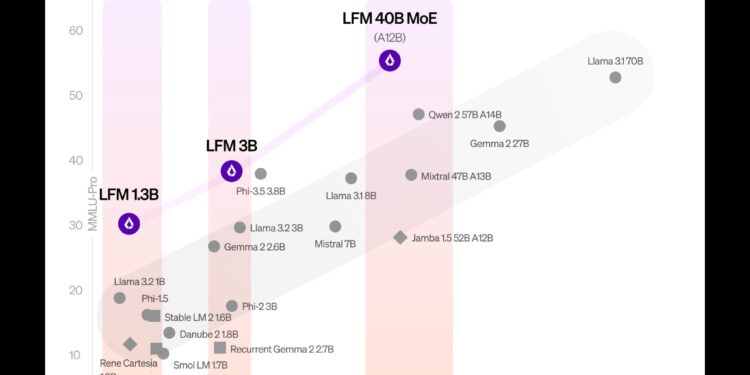





Anthropic 的 CEO Dario Amodei发表了一篇名为《机器爱的恩宠》的文章,讨论了强大人工智 […]