Runway宣布推出其视频生成模型的API。该API旨在帮助开发者和公司将Runway的生成式AI模型集成到第 […]
Playground v3(PGv3)是由Playground开发的一种文本到图像生成模型,其基于最新的大语言 […]
g1 是一个使用 Llama-3.1 70b 模型在 Groq 上创建类似 o1 的推理链的实验性应用。其主要 […]
故事板是一种视觉工具,用于通过一系列框架描绘故事或概念,类似于漫画。它最初用于电影行业,帮助有效规划和传达想法 […]
斯坦福大学教授李飞飞的新公司 World Labs 成功融资 2.3 亿美元。李飞飞被誉为“AI教母”,她的公 […]
GOT-OCR2.0 是一种用于光学字符识别(OCR)任务的通用模型,旨在解决传统OCR系统(OCR-1.0) […]
PuLID(Pure and Lightning ID Customization via Contrasti […]
GameGen-O是一个专为生成开放世界视频游戏而设计的Diffusion Transforme模型。该模型能 […]
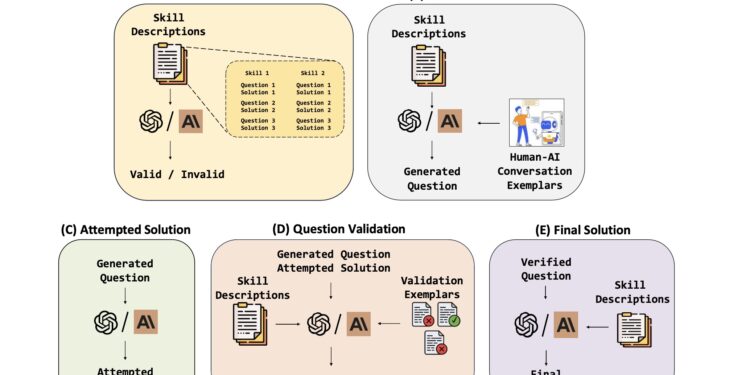
随着大语言模型(如GPT-4、Claude等)的发展,LLM在处理数学问题上取得了显著进展。然而,这些模型的能 […]
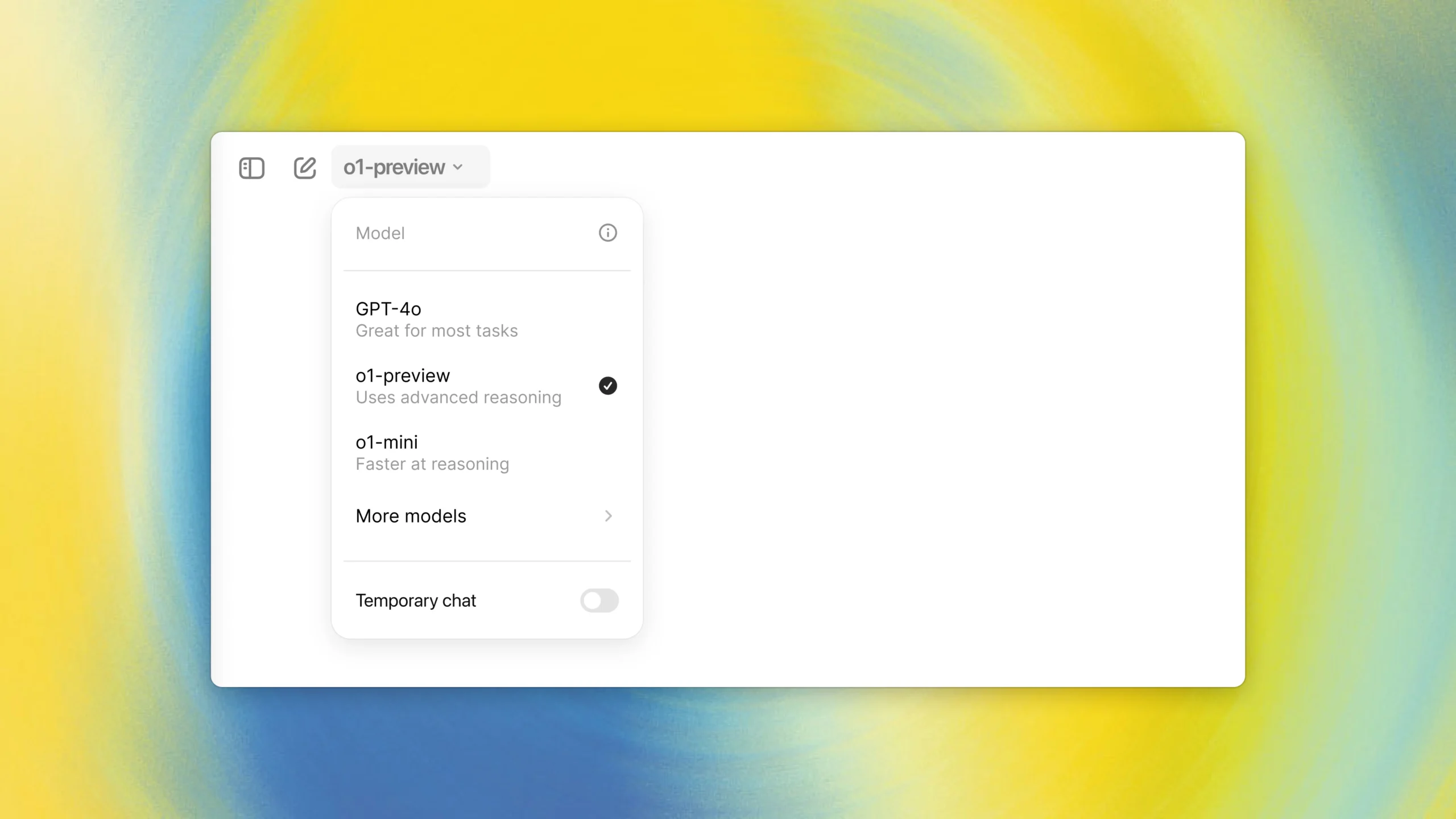
OpenAI发布了全新的o1-preview” 推理模型系列,这是一个设计用于解决复杂问题的 AI 系列,能够 […]
OpenAI公布了其最新的o1 模型官方提示词建议,OpenAI明确表示模型在简单的提示下表现最佳。一些提示工 […]
Suno推出Covers功能,通过Cover功能,你可以将任何音频,从简单的录音到完整制作的歌曲,转化为一种全 […]
Google最新推出的DataGemma模型旨在通过与Google Data Commons(数据共享平台)的 […]
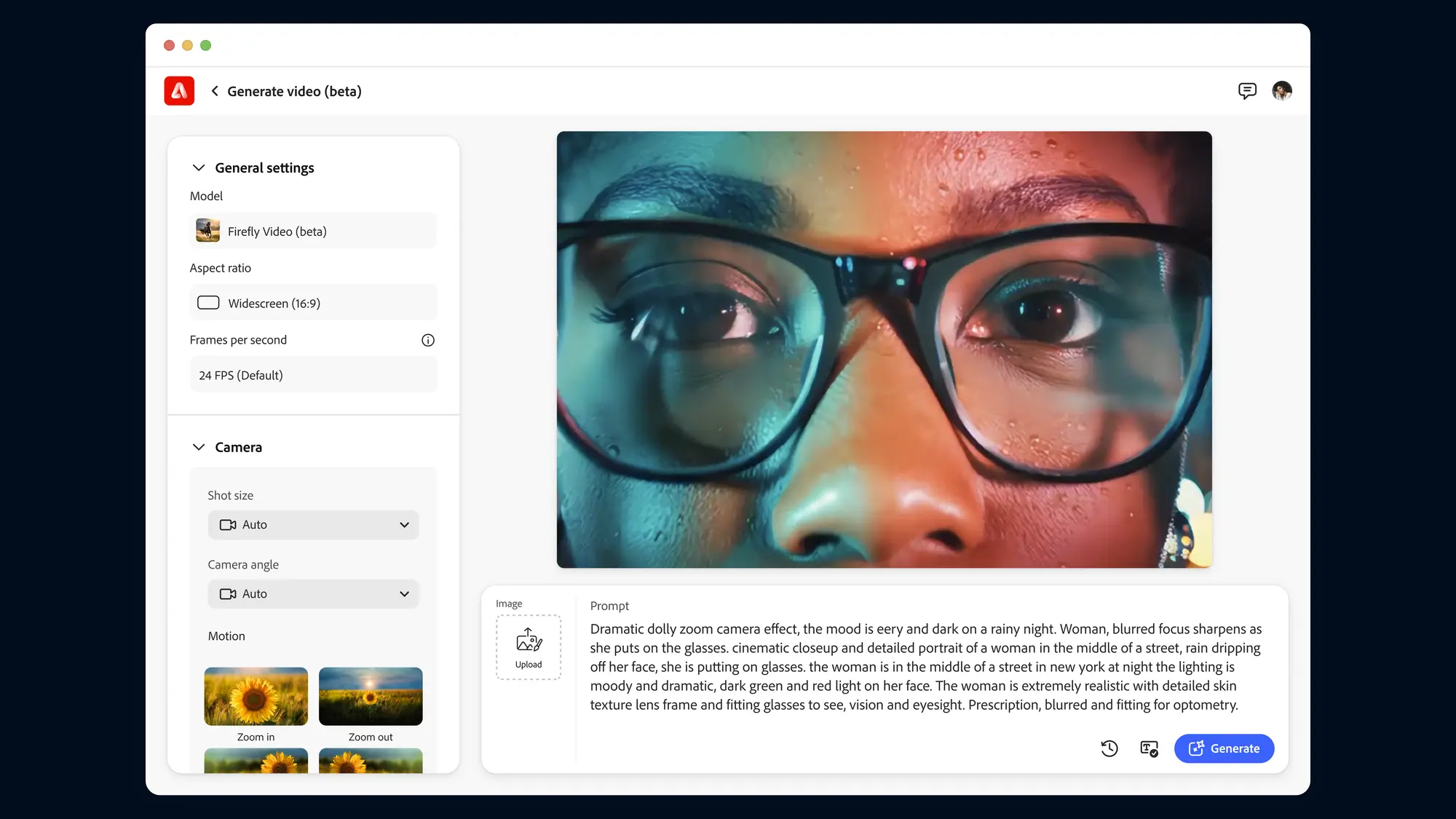
Adobe 将推出新的生成式 AI 视频模型Adobe Firefly Video Model ,专门用于视频 […]
Hume AI 推出的全新语音对话基础模型:EVI 2 ,能够与用户进行极其人性化的语音对话。它可以快速流畅地 […]
Vchitect 2.0 是由上海人工智能实验室开发的视频生成模型,它支持通过文本和图像生成5 到 20 秒的 […]
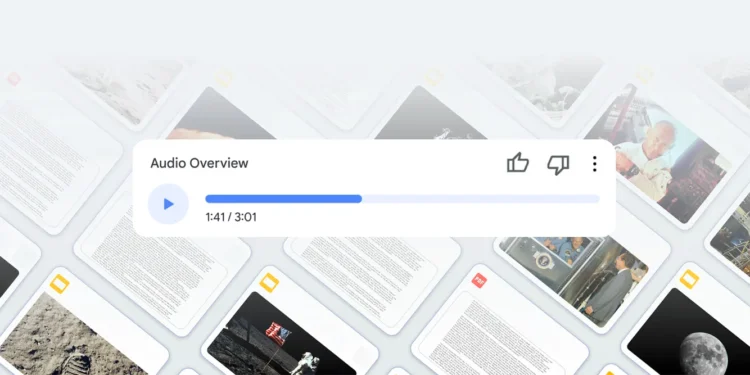
Google 推出的 NotebookLM 新增了一项名为 “Audio Overview” 的功能,允许用户 […]
法国 AI 初创公司 Mistral 推出了其首个多模态模型 Pixtral 12B,该模型具有120 亿参数 […]
Jina AI 推出的两款专门将原始 HTML 转换为干净的 Markdown 的小型语言模型。 Reader […]
Runway 发布了一篇文章介绍了他们对 AI 生成媒体的新交互方式的思考。Runway认为应该为生成式媒体创 […]
OpenAI 分享了一篇内容,介绍了一些作家如何在创作过程中使用 ChatGPT 的示例。 在这篇文章中,Op […]
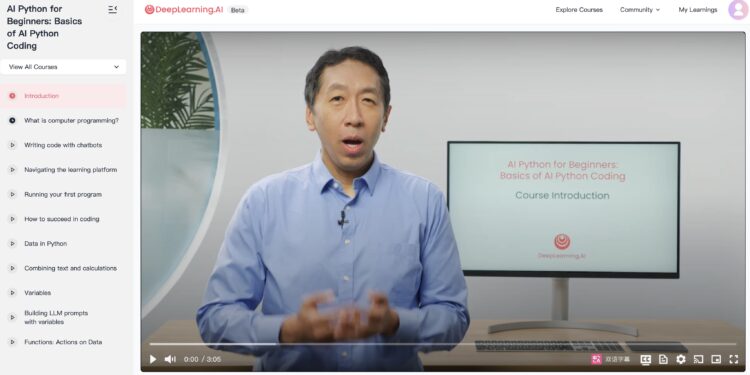
这个课程由Andrew Ng主讲,专为初学者设计,帮助学员学习Python编程基础,并将其与AI工具集成进行数 […]
Vidu升级其 AI 视频模型,支持让任意主体保持一致 重点在于在生成图像时保持主体的一致性,尤其是针对角色和 […]
微软宣布了他们在逻辑量子比特领域的突破,展示了性能最好的逻辑量子比特,错误率比物理量子比特低800倍。这一成果 […]
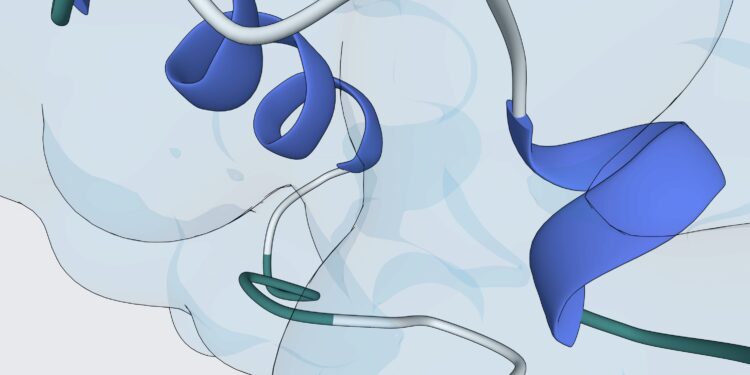
Chai Discovery 推出了 Chai-1,一个面向分子结构预测的多模态基础模型,适用于药物发现等任务 […]
Open Interpreter团队宣布了一个重要的决定:放弃制造01 Light硬件设备,转而推出01 Ap […]
FLUX.1模型的发布迅速风靡全球,生成的图像质量超越了现有的开源模型,并且支持通过简单的操作进行微调,无需编 […]
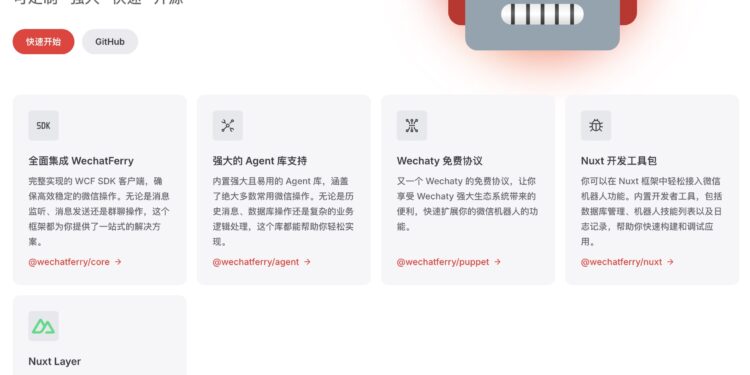
WechatFerry 是一个微信机器人框架,提供了一套强大、快速且可定制的解决方案,适用于开发和集成微信机器 […]
Concept Sliders 是一种用于扩散模型(如 Stable Diffusion)的LoRA 适配器, […]
苹果在所有新款 iPhone 都配备了一个新的按钮引入了一个全新的**“Camera Control”按钮** […]

















Runway宣布推出其视频生成模型的API。该API旨在帮助开发者和公司将Runway的生成式AI模型集成到第 […]