





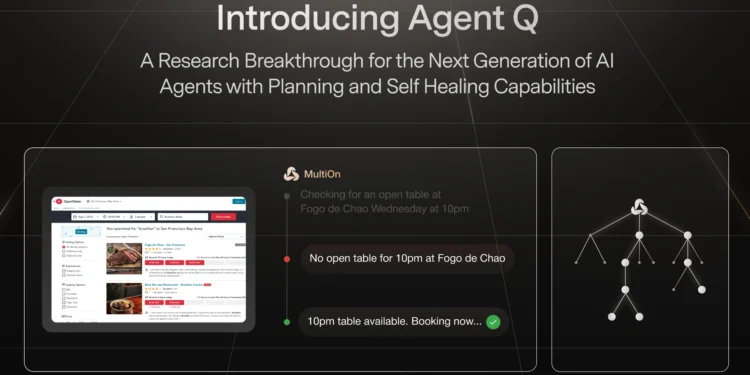

Genie 一个更像人类工程师的 AI 模型 在编程任务中超越所有的现有AI模型
Cosine发布了一款,专为软件工程设计的AI模型:Genie。Genie在SWE-Bench和SWE-Lit […]



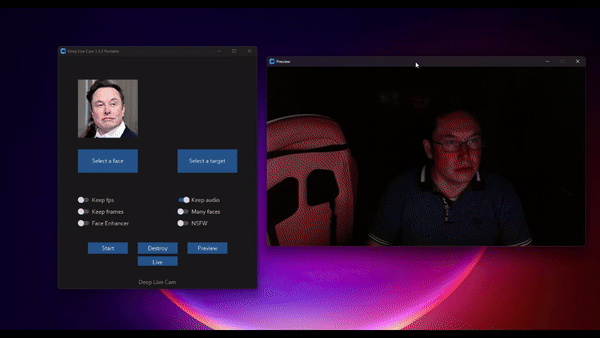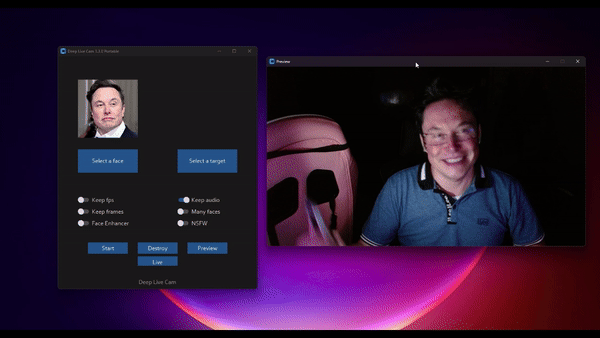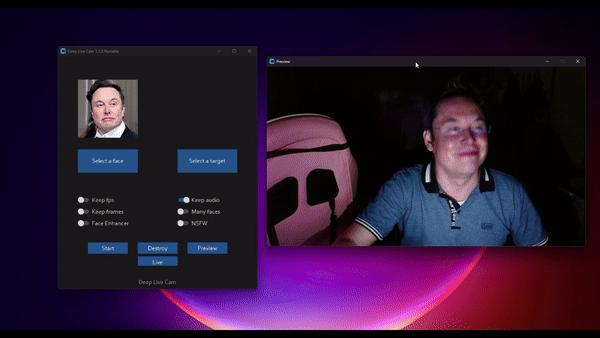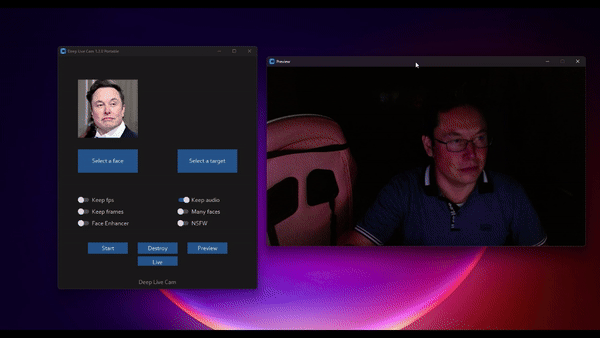
ReSyncer:一个多功能统一模型 可以实现音视频口型同步、说话风格迁移和换脸
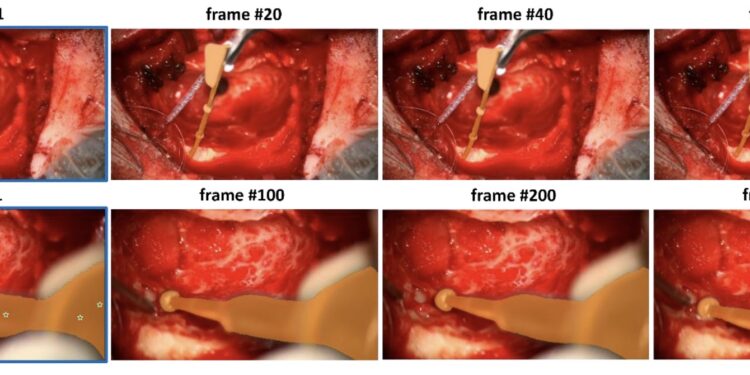
ReSyncer是由清华大学、百度和南洋理工大学 S-Lab 实验室共同开发的一种新型框架,它能够生成非常逼真 […]
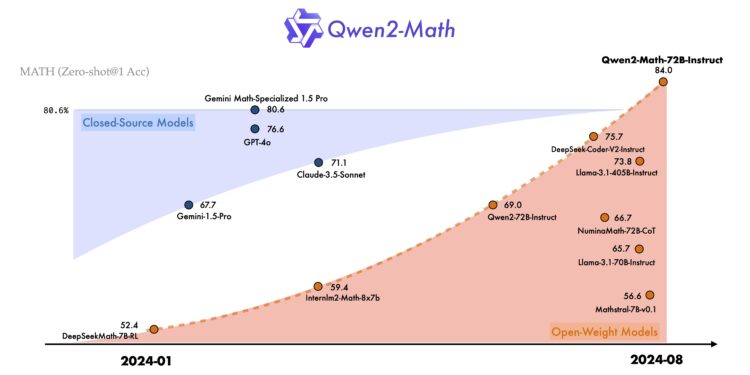

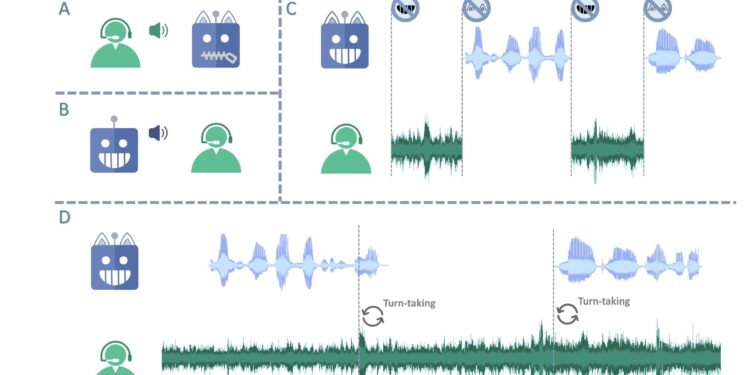


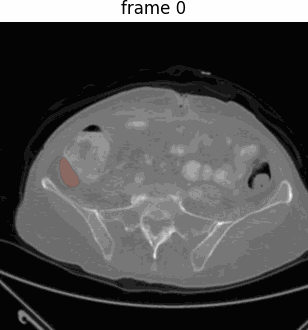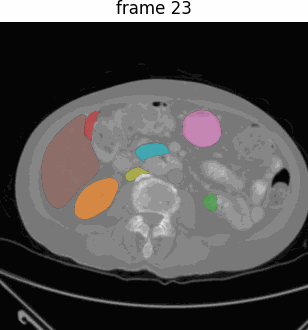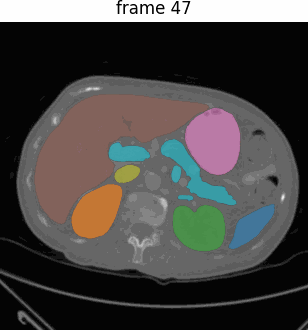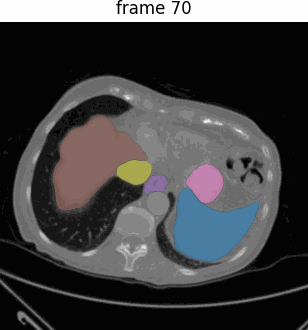


Seed-ASR 是字节跳动开发的一种先进的自动语音识别(ASR)模型,基于大语言模型(LLM)框架构建。专门 […]