1 背景 1.1 为什么要做新系统 B站过去的客服系统是通过外部采购获得的,已经使用了几年。然而 […]
What!你还在耗费十几个小时下载庞大的数据集和模型吗? Oops!你的电脑已经不堪重压,内存告急、卡顿抗 […]
在《GPT最佳实践 - 提升Prompt效果的六个策略》中,我们介绍了OpenAI官方发布的"GPT 最佳实践 […]
SDXL发布已经有一段时间了,模型也更新到了1.0 SDXL 1.0具有以下新特性: 1、更出色的图像生成 […]
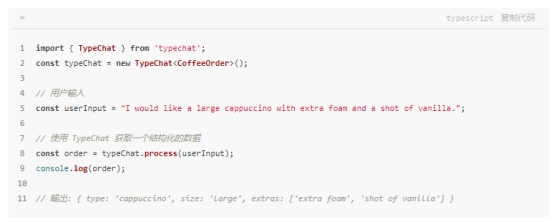
什么是 TypeChat TypeChat 是一个革命性的库,它简化了使用 TypeScript 构建自然语言 […]
“视频版ControlNet”来了! 让蓝衣战神秒变迪士尼公举: 视频处理前后,除了画风以外,其他都不更改 […]
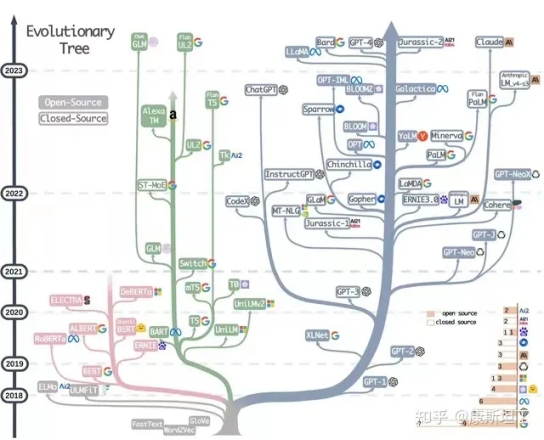
在过去的几周里,我一直在试用几个大型语言模型(LLMs)并使用互联网上的各种方法探索它们的潜力,但现在是时候分 […]
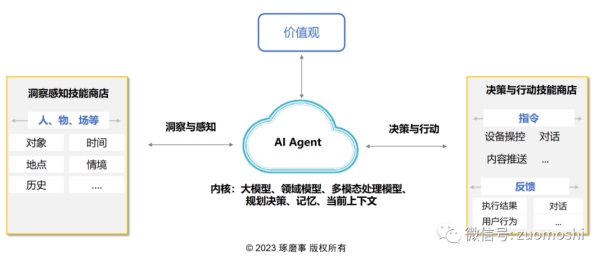
PART 01未来大模型的发展方向:AI Agent 大语言模型(Large Language Models, […]
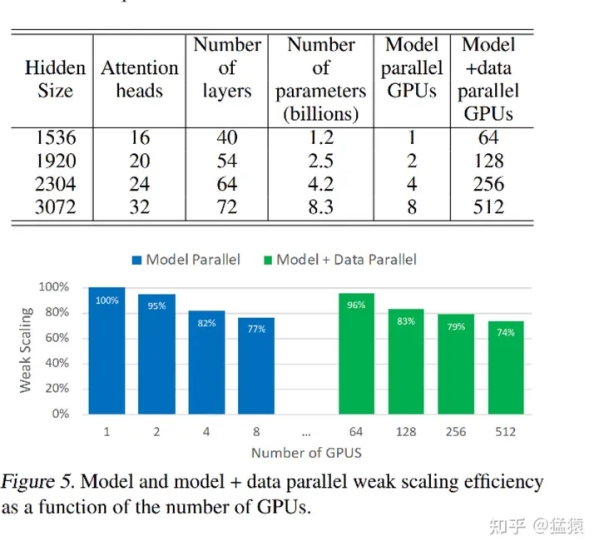
今天我们将要介绍最重要,也是目前基于Transformer做大模型预训练最基本的并行范式:来自NVIDIA的张 […]
在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用 […]
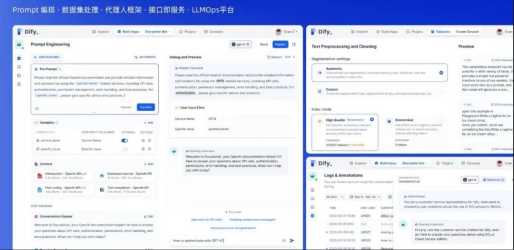
当前,随着大模型应用落地需求不断增加,越来越多的人在寻找搭建LLM应用的最佳模式,而这种模式就如同当年web开 […]
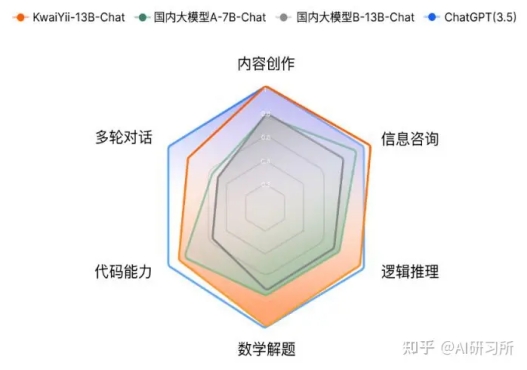
「快意」大模型(KwaiYii) 是由快手AI团队从零到一独立自主研发的一系列大规模语言模型(Large La […]
和大部分人一样,我对自然语言处理和语言模型的了解从ChatGPT开始。 和大部分人一样,第一次接触就被Chat […]
痛点:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失 笔者之前采用了Longchain的文档切分工具, […]
导读以ChatGPT为代表的大模型悄然加速了时代的变革,你是否对此感到举手无措呢。本文详细整理了探索大模型相关 […]
智东西8月23日报道,过去三个月,生成式AI浪潮变数丛生,国内AI大模型产业也连爆大事:6月29日美团宣布完成 […]
该项工作的作者提出 Llama 2 模型:这是经过一系列 预训练和微调的大语言模型 (LLM),其参数规模从 […]
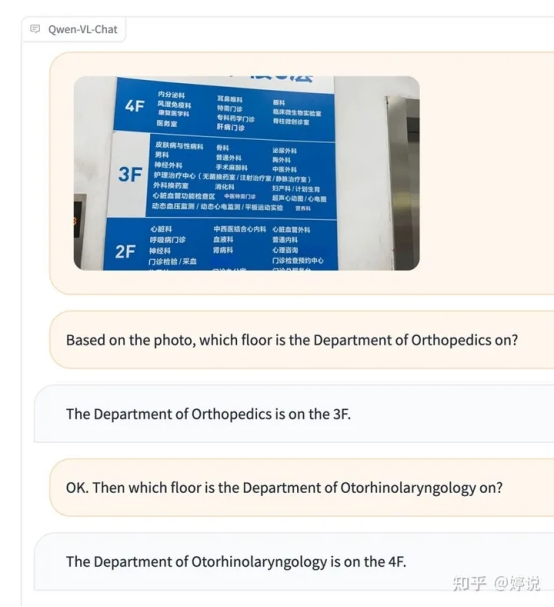
通义千问开源第二波!8月25日消息,阿里云推出大规模视觉语言模型Qwen-VL,一步到位、直接开源。Qwen- […]
随着ChatGPT以前所未有的速度火出圈,大模型也迅速从过去的遥不可及走到了我们身边。从今天开始,元碳院将开始 […]
LLM(大规模语言模型)的微调不再困难!!我们都知道,大模型在某些特定的垂直场景,效果不是那么好,很多企业/个 […]
几周前,我介绍了基于stable diffsion的一个换脸插件:roop(这个插件也有独立版,功能更多,甚至 […]
随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前 […]
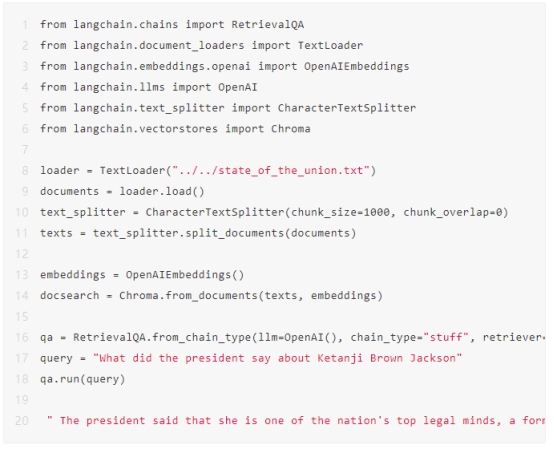
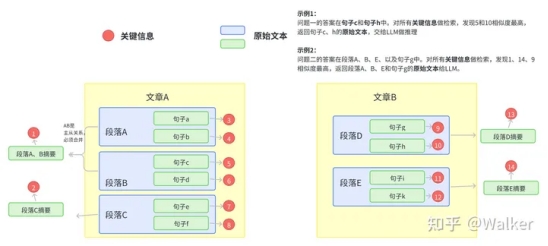
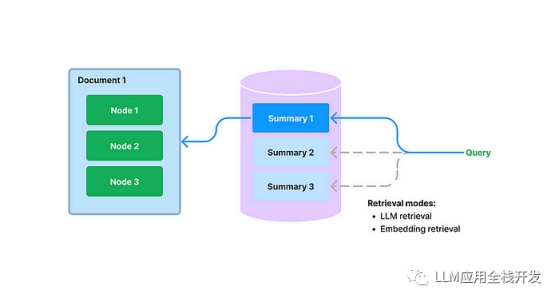
随着 LangChain + LLM 方案快速普及,知识问答类应用的开发变得容易,但是面对回答准确度要求较高的 […]
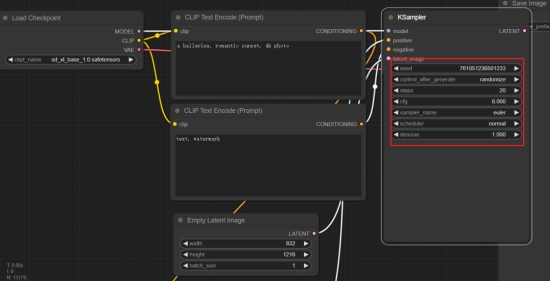
一、ControlNet 简介 SDXL 1.0 发布已经过去20多天,终于迎来了首批能够应用于 SDXL 的 […]
众所周知,⼤模型代表了⼈⼯智能技术的前沿发展。它以强⼤的语⾔理解和⽣成能⼒,正在重塑许多领域。但是从获得⼤模型 […]
在开源大模型LLaMA 2会扮演类似Android的角色么?一文中曾经提到:大模型落地的方式是系统型超级应用。 […]
项目简介 选择如何对 Transformer 的位置信息进行编码一直是 LLM 架构的关键组成部分之一。 最近 […]
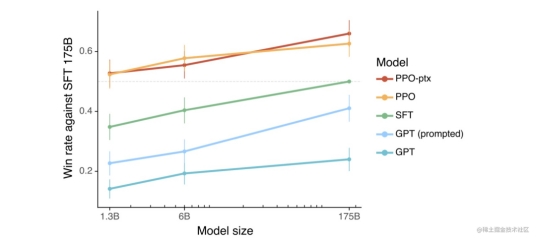
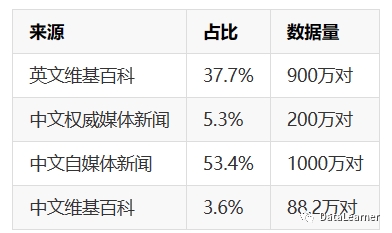
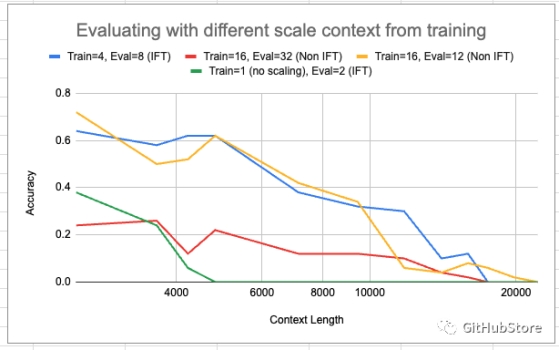
我们开源了第一个中文QLoRA 33B大语言模型——Anima。按照我们的评测,Anima模型的性能超越了对比 […]
本文旨在比较用于 LLM 推理和服务的不同开源库。我们将通过实际部署示例探讨它们的核心特性和优缺点。研究 vL […]
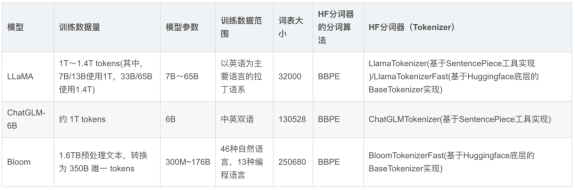
分词是NLP中的关键预处理步骤之一,用于将文本分解为词或子词的组合,使机器更好地理解和分析文本。 1. 规则分 […]








![[中文开源震撼首发]33B QLoRA大语言模型Anima真的太强大了!QLoRA技术可能是AI转折点!](https://www.linkshub.net/wp-content/uploads/other/aizx/2024-06-06/0df7f240b6490854759d24b85f36360b.jpg)
1 背景 1.1 为什么要做新系统 B站过去的客服系统是通过外部采购获得的,已经使用了几年。然而 […]