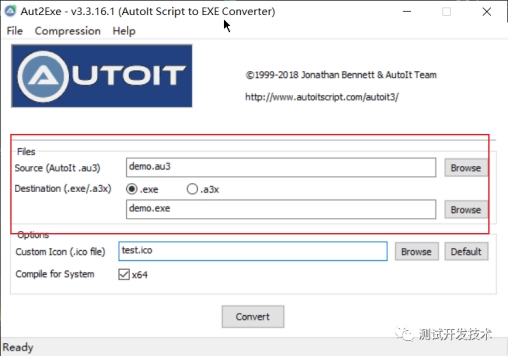
刚刚过去的 2023 年是大模型元年,在国产大模型数量狂飙突进的同时——已经超过 200 个,「套壳」一直是萦 […]
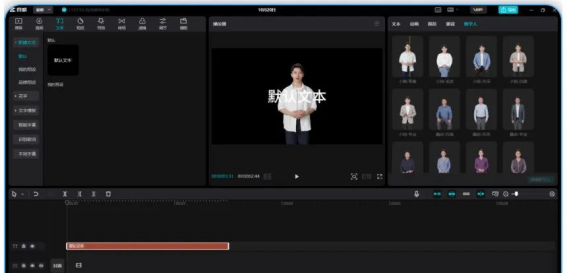
昨天的文章提到通过修改数字人的材质做全息投影仪的动态效果,今天分享一下生成金色动态粒子人的代码,效果图如下: […]
不是模型不够强大,是你的提示不够精准。 当大型语言模型如ChatGPT在各领域大放异彩时,普通用户却对其指令设 […]
Stable Diffusion 以其可控性被越来越多的设计师纳入了工作流程。以电商为例,在AI工具出现以前, […]
论文由微软研究团队撰写,这篇论文深入探讨了Sora的发展背景、核心技术、新兴应用场景、现有的局限性以及未来的发 […]
ChatGPT从推出到现在将近一年的时间给我们的工作和生活都带来了很大的冲击,渗透到了我们生活的方方面面,在学 […]
你是不是也有这样的困扰? 一、AI 助手用不起来。注册了 N 个 AI 助手,但仅会偶尔闲聊,找不到「AI 效 […]
今天分享几个全球流行AI做PPT的工具,用得好可以事半功倍,效率杠杠的 1、Decktopus (地址:htt […]
本篇文章介绍:1, 声音数据集训练到模型的过程 2 ,SVC和RVC声音模型网站推荐 一、声音数据集训练到模型 […]
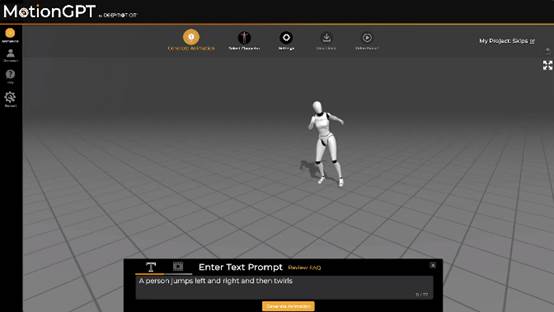
专注于AI动捕技术的DeepMotion日前发布了MotionGPT。这是一款基于生成式AI的工具,可以将文本 […]
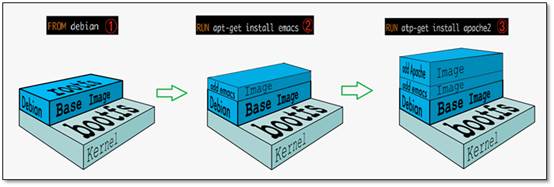
Docker中的三个重要构成:Image(镜像),Container(容器),Repository(仓储)。I […]
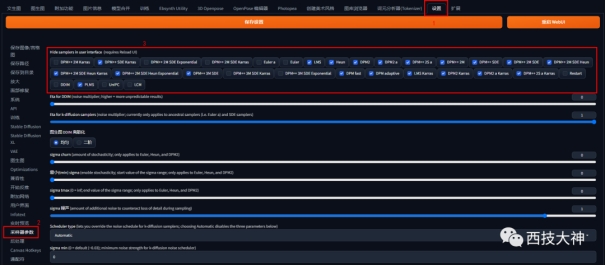
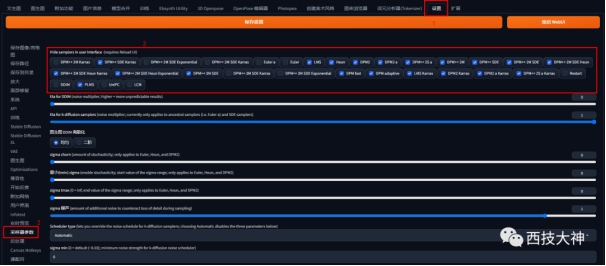
在使用StableDiffusion过程中一个核心环节——选择什么样的采样器?30个采样器都是干嘛的?今天就跟 […]
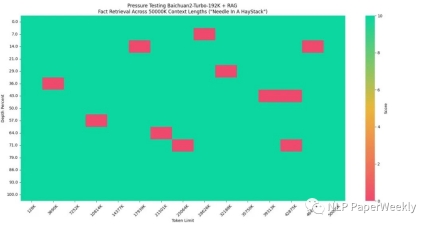
今天对百川的RAG方法进行解读,百川智能具有深厚的搜索背景,来看看他们是怎么爬RAG的坑的吧~ 总的来说,百川 […]
据悉,ChatGPT每周拥有1亿用户,但许多人仍然不知道如何正确运用其力量。因此,网络上充斥着各种备忘单,以即 […]
在制作定制数字人时,有时候为了不侵权,会使用换脸软件将原素材的脸型进行替换,今天一个客户就提出了这样的需求,所 […]
随着互联网不断发展,它给我们带来便利的同时,也带来了枯燥、重复、机械的重复工作。今天,我要和大家分享一款老牌实 […]
几个月前,Stable Diffusion的大模型连续推出了两中提速技术,一个是官方的Turbo,一个是清华团 […]
一段文字,一张照片,就能让照片的人物开口说话?这听起来像科幻电影里的情节,但如今已经变为现实!随着技术的发展, […]
文章地址:https://arxiv.org/pdf/2312.04461.pdf 项目地址:https:// […]
人类设计 prompt 的效率其实很低,效果也不如 AI 模型自己优化。 2022 年底,ChatGPT […]
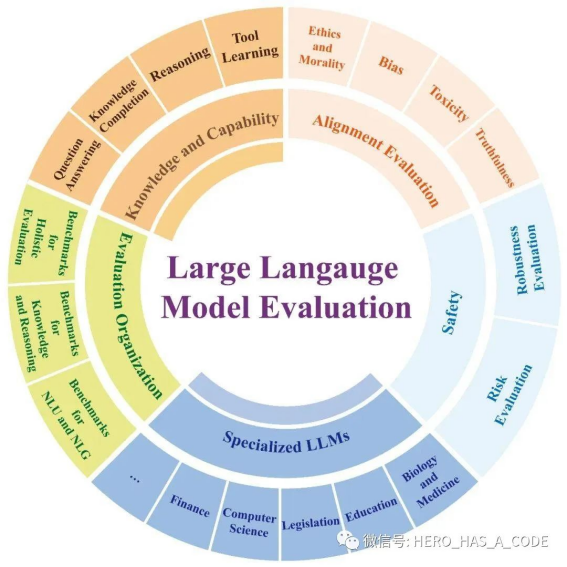
大模型技术的快速发展,特别是由OpenAI发布的ChatGPT等模型的问世,标志着人工智能进入了一个新的里程碑 […]
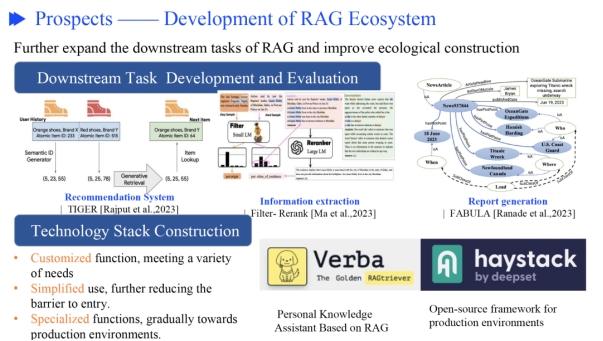
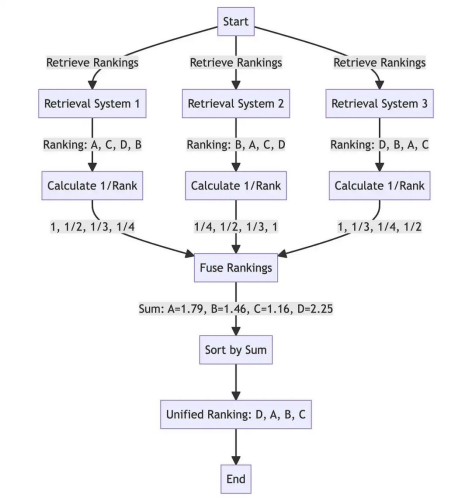
今天分享一个来自同济大学Haofen Wang的关于检索增强生成的报告:《Retrieval-Augmente […]
龙年伊始,Sora横空出世,举世震惊。Sora声称“作为世界模拟的视频生成模型”,豪气干云。有人悲观预言很多传 […]
最近腾讯的PhotoMaker很火,因为仅需要一张大头照就可以快速实现类似妙鸭相机的效果,现在又有一个类似的解 […]
嘿,小伙伴们!有没有遇到这种烦恼?看到网上有超赞的视频、音乐或图片,却无法轻松地保存到自己的电脑或手机上? 别 […]
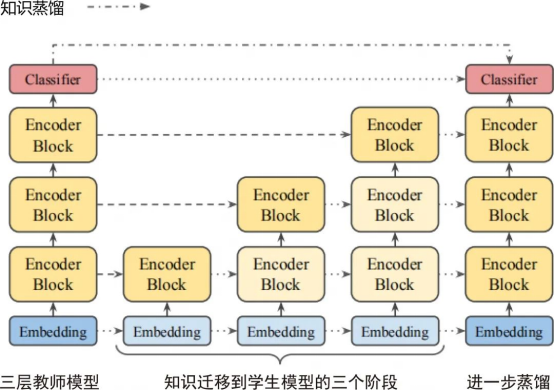
导读:近年来,BERT 系列模型成了应用最广的预训练语言模型,随着模型性能的提升,其参数规模不断增大,推理速度 […]
by Adrian H. Raudaschl 近十年来,我一直在探索搜索技术。可以诚实地说,最近出现的检索增强 […]
在学术研究和数据分析的过程中,提高论文质量是每位研究者的追求。ChatGPT作为一个先进的自然语言处理 […]
引言: Stable Diffusion作为一种强大的图像生成技术,受到了广泛的关注和应用。对于想要探索这一技 […]

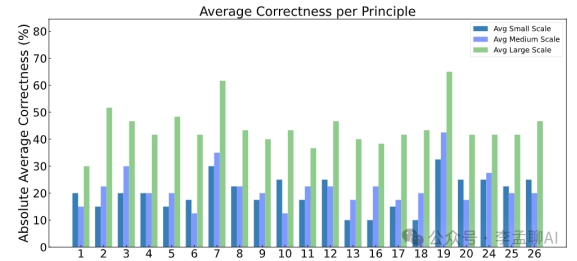

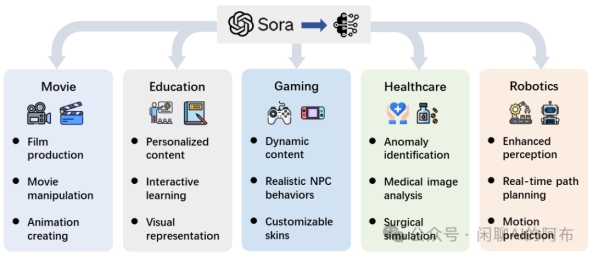

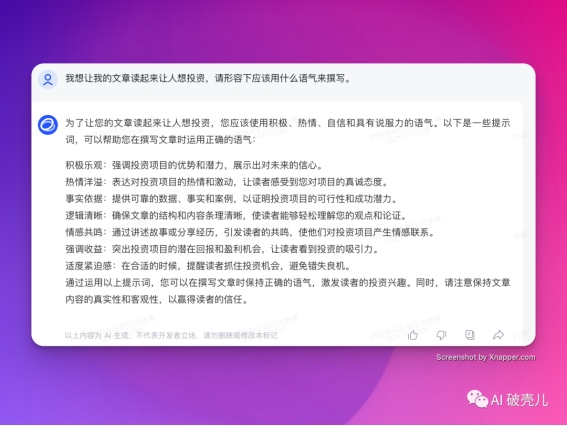










刚刚过去的 2023 年是大模型元年,在国产大模型数量狂飙突进的同时——已经超过 200 个,「套壳」一直是萦 […]