TTS引擎用于实现文本到语音的转换。随着人工智能的普及以及数字设备应用的增加,相关系统对语音识别以及文语转换技 […]
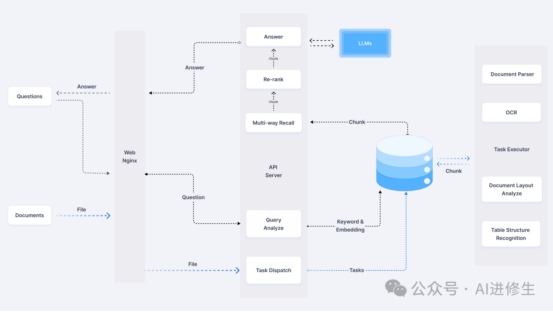
RAGFlow 是一个基于Deepdoc(深度文档理解)的开源RAG(检索增强生成)引擎,仅仅一月,Githu […]
最近,央视公开了一些由ai生成的图片与视频,其中有几张图片非常有趣,成功吸引到了我, 那便是这几张由ai与 […]
这篇文章将给大家分享十个科研论文写作的高效提示词指令(prompt),这些提示词指令可以帮助大家更有效地利用C […]
大家共同整理的提示词: 【特别感谢无私分享的朋友】 1 . 移动镜头:推、拉、摇、移、升、降,包括猛推、快推、 […]
微软研究院推出了GraphRAG,这是一种先进的方法,旨在提升大语言模型(LLM)从私有数据集中检索和生成响应 […]
Poe推出了一项名为“Previews”的新功能,允许用户在聊天中直接查看和互动生成的Web应用程序。该功能特 […]
OdysseyML 旨在开发能够生成和导演好莱坞级别视觉效果的AI技术。受早期计算机图形研究和皮克斯故事的启发 […]
PaintsUndo是一个旨在模拟数字绘画行为的基础模型。你只需要通过输入静态图像,它就能帮你自动生成视频输出 […]
Huffington的心理健康公司Thrive Global和OpenAI创业基金合作创建Thrive AI […]
一位名为 Charles Diaz 的开发者使用树莓派创建了一个完全功能的 TARS 复制品。 这不仅仅是一个 […]
加州大学圣地亚哥分校和麻省理工学院的研究人员刚刚推出了一个名为Open-TeleVision的项目,这是一种开 […]
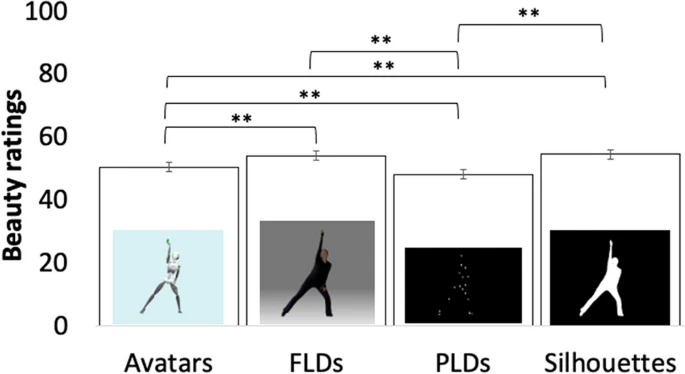
EMOKINE 是一个软件包和数据集创建框架,用于研究实验心理学、情感神经科学和计算机视觉中的情感全身运动。E […]
FunAudioLLM 是阿里巴巴开发的一组语音处理模型,旨在改善人类与大语言模型之间的语音交互。它由两个主要 […]
X/Twitter 目前正在经历大量变化,包括埃隆·马斯克开源的算法。如果您是创作者,跟踪这些变化是有意义的, […]
InternLM-XComposer-2.5 (浦语灵笔 IXC-2.5) 是由上海人工智能实验室, 香港中文 […]
Florence-2:微软全新开源视觉模型! 能够执行超过10种不同的视觉任务 包括图像字幕生成、对象检测、图 […]
【点击前往】下载安装插件 在侧边栏(Side panel)里打开 Chrome 内置 Gemini […]
Chrome 127 集成Gemini:本地AI功能 Google将Gemini大模型整合进Chrome浏览器 […]
LivePortrait是一个用于生成逼真肖像动画的框架,只需一张静态肖像图像就能生成动态视频。其主要目标是实 […]
Kyutai 研究实验室今天在巴黎发布了 Moshi AI语音助手,一个能与人类进行自然对话的AI语音助手,可 […]
为了帮助内容创作者维护安全的互联网,Cloudflare 推出了全新的一键按钮: “easy button” […]
Clone Robotics是一家致力于开发低成本、生物仿生和智能仿生机器人的公司。其使命是利用先进的肌肉骨骼 […]
最新泄露的细节显示,Google Pixel 9系列将带来更多复杂的AI体验。据Android Authori […]
Perplexity 发布了Pro Search的新升级版本,旨在解决更复杂的问题并提高研究效率。Pro Se […]
Retool 刚刚发布了最新2024上半年《人工智能现状报告》,收集了约750名技术人员的意见,包括开发者、数 […]
Meta 3D-Gen (3DGen) 是Meta开发的一种最新的文本到3D资产生成技术,可以端到端生成高质量 […]
1.零度教程演示的测试工具: Internet Speed 2:【点击下载】 【因为我是webOS 系统,可能 […]
Fish Speech 是一个全新的文本转语音 (TTS) 解决方案,该项目由fishaudio开发。当前模型 […]
Gen-3 Alpha 是Runway推出的新一代视频生成模型,它在保真度、一致性、运动和速度方面都比以前的模 […]








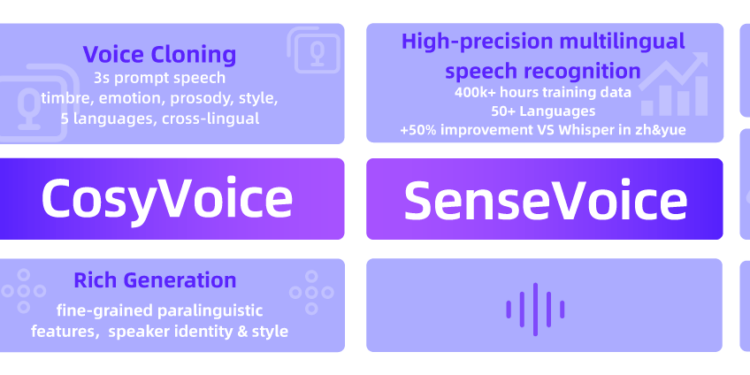














TTS引擎用于实现文本到语音的转换。随着人工智能的普及以及数字设备应用的增加,相关系统对语音识别以及文语转换技 […]