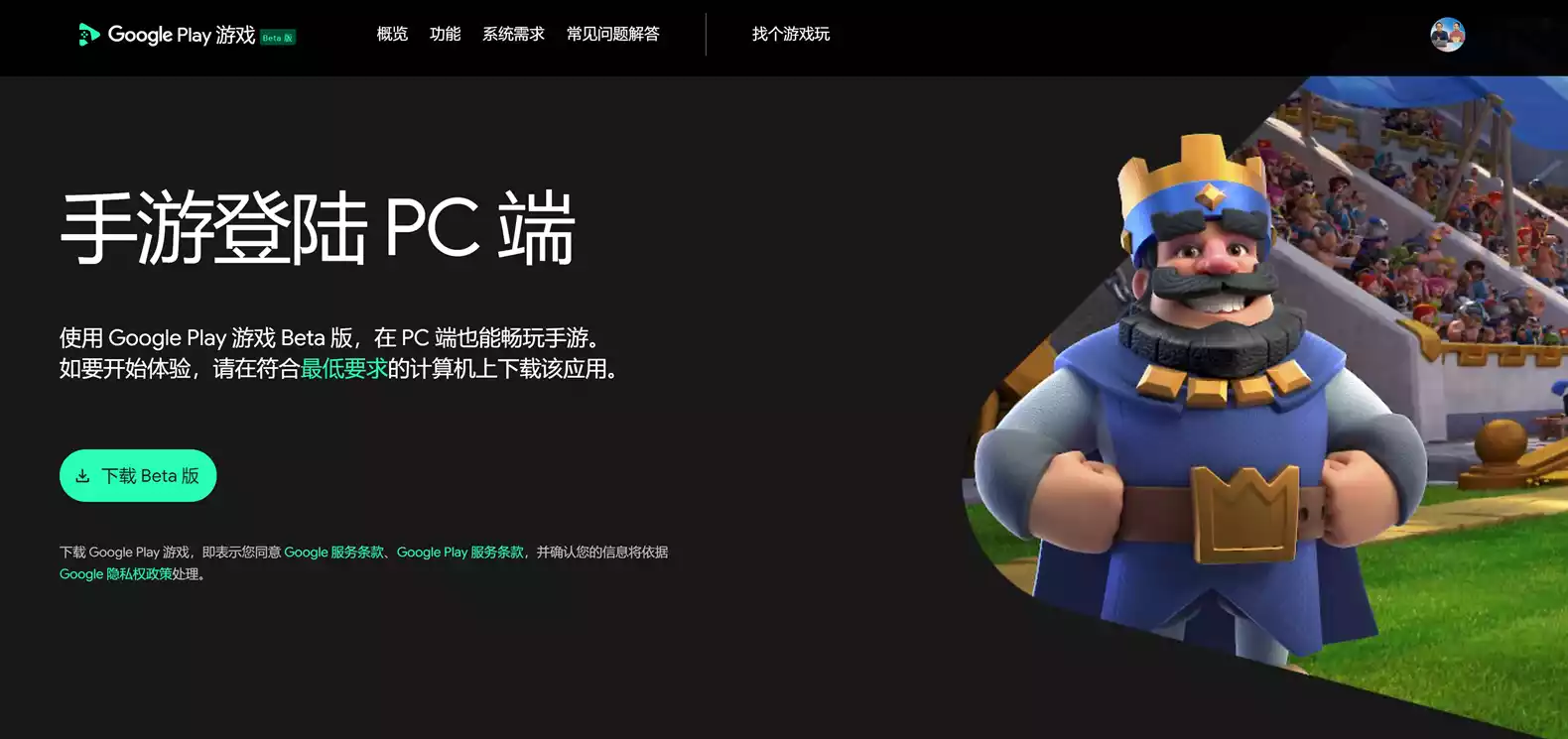
FydeOS是由开源项目Chromium OS二次开发的操作系统,是使用Linux内核,包括浏览器平台与容器技 […]
Meta FAIR公开发布了多项新的研究成果、模型和数据集,旨在通过开放、合作和卓越的原则,推动AI领域的创新 […]
Hedra Labs 推出了 Character-1 的研究预览版。支持根据任意人物照片和语音内容生成个人会说 […]
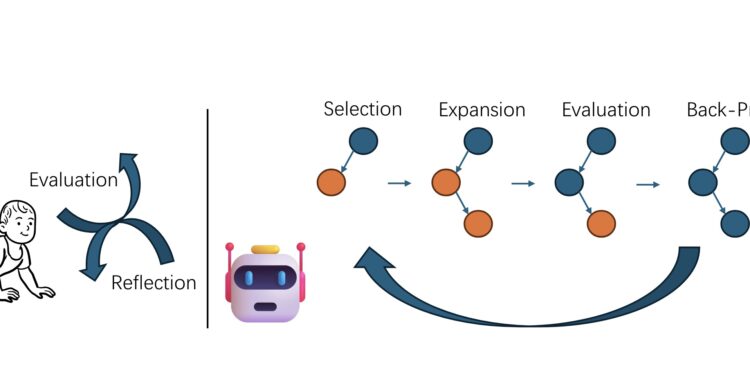
来自全球多所大学和科技公司的研究人员们共同完成了一项重要的工作,他们系统地整理了关于生成性人工智能(GenAI […]
高考覆盖各类学科及题型,同时因其开考前的“绝密性”,被视作中国最具权威的考试之一,成为评估考生综合能力的“试金 […]
ChatTTS Speaker 提供了ChatTTS生成的音色的稳定性评分,并根据性别和年龄分类,用户可以试听 […]
Xiaoju Survey 是一个轻量、安全的问卷系统基座,提供面向个人和企业的一站式产品级解决方案,旨在快速 […]
矩阵乘法(MatMul)是使用Transformer架构的大语言模型(LLM)中最耗费计算资源的操作,需要大量 […]
Runway推出新一代视频生成模型 Gen-3 Alpha,具备更高的保真度和一致性,能够生成逼真的人类角色和 […]
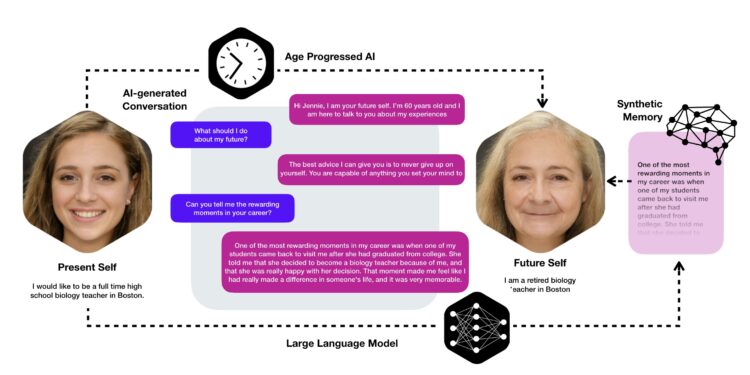
麻省理工学院(MIT)的研究人员开发了一款名为Future You “未来的你”的AI聊天机器人,它可以让你和 […]
DeepSeek宣布发布开源模型DeepSeek-Coder-V2,该模型在代码和数学能力上超越了GPT-4- […]
DeepMind最新研发了一种叫视频转音频(V2A)的技术。这种技术可以根据视频画面和文字描述,自动生成丰富的 […]
Color Health与OpenAI合作开发了一款名为Color’s copilot的工具,旨在通过使用GP […]
MimicBrush 由阿里巴巴开发的一种新型的图像编辑方法,也可以称为模仿编辑(imitative edit […]
Synowedjat是Synology的一个后门程序,无论您使用的是否为正版设备,也就意味着无论你是购买的正品 […]
最低要求 操作系统: Windows 10 (v2004) 及以上 存储: 具有 10 GB 可用存储空间的固 […]
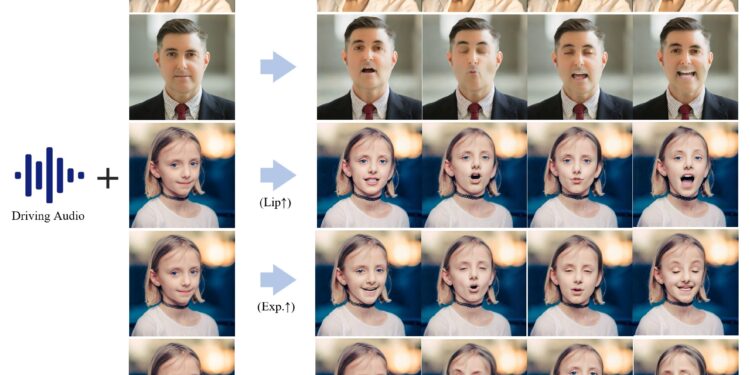
通过语音音频输入来驱动肖像图像生成动画视频,也就是一段语音+个人图像生成会说话唱歌的视频。 研究团队提出了一种 […]
随着人工智能的快速发展,诸如GPT-4和LLaMA等大语言模型在自然语言处理能力方面取得了显著进步。这些模型展 […]
如果你想让通过ChatGPT来生成图像,一般一次只会生成一张,一张一张的生成而且想要保持图像风格和角色一致非常 […]
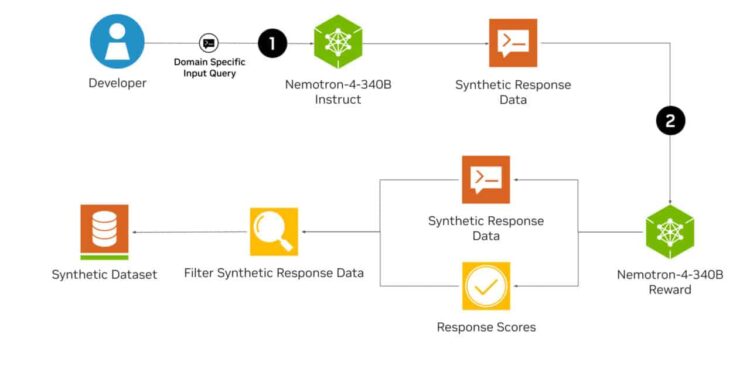
NVIDIA 发布了 Nemotron-4 340B 开源模型家族,该模型主要用于生成高质量的合成数据,从而提 […]
“Soft and Squishy Linework” 是一个文本生成图像模型,专门设计用于创建柔和的、低保真 […]
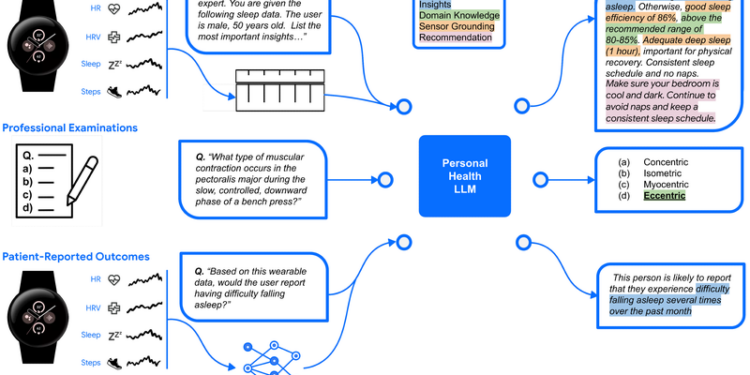
移动设备和可穿戴设备(如智能手表和健身追踪器)能够持续、详细和长期地记录个人的生理状态和行为数据。例如: 步数 […]
开局即巅峰!视频AI新秀”梦想机器”惊艳亮相! 视频生成AI工具再添猛将!昨日,Luma AI重磅推出旗舰产品 […]
VideoLLaMA 2 是一个旨在提升视频大语言模型(Video-LLM)时空建模和音频理解能力的项目。该模 […]
MaxKB 是一个基于大语言模型 (LLM) 的智能知识库问答系统。它能够帮助企业高效地管理知识,并提供智能问 […]
PROTEUS是斯坦福大学的研究人员和Apparate Labs推出的一款用于生成逼真、具有表现力的人类形象的 […]
Luma Dream Machine 基于 DIT 视频生成架构,能够快速从文本和图像生成高质量、逼真的视频。 […]
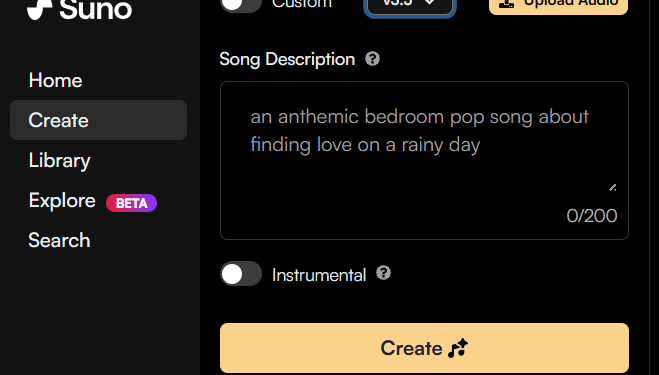
Suno 发布了一项新功能,允许用户从任何声音创建歌曲。所有专业版和高级版用户现在可以上传或录制音频,并将其转 […]
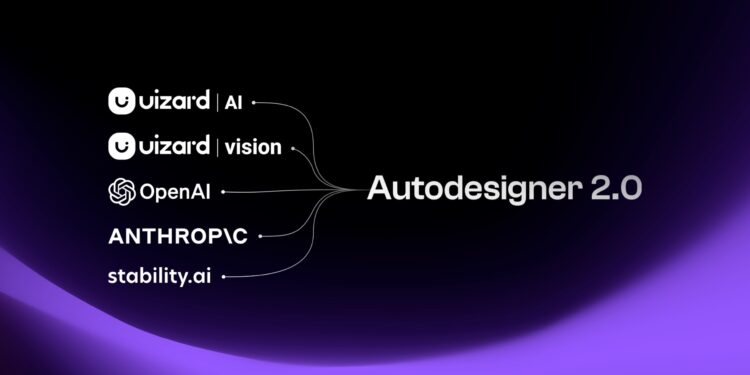
Uizard 发布 Autodesigner 2.0 AI设计引擎,结合了 uizard 的专有模型和Anth […]
东京大学的一组研究人员开发并训练了一款名为Musashi的“肌骨类人机器人”,能够驾驶一辆小型电动车。这款机器 […]





















FydeOS是由开源项目Chromium OS二次开发的操作系统,是使用Linux内核,包括浏览器平台与容器技 […]